

Apache Spark is one of the popular and widely used Big Data tools among the industries. Apache Spark has become a buzz in the industry and is very trending nowadays. But the industries are shifting towards Apache Flink – the 4th Generation of Big Data due to Apache Spark limitations.
Want to know more about Apache Spark? Learn Apache Spark with this Guide, here is everything you need to know about Apache Spark as a beginner!
In this article, we will describe Apache Spark limitations in detail. Let’s start with the Apache Spark introduction first!
Apache Spark Introduction
Apache Spark is an open-source, lightning-fast cluster computing framework schemed for fast computing. Apache Spark extends the MapReduce model to use it efficiently for many kinds of computations including stream processing and interactive queries. Apache Spark has its main feature as in-memory cluster computing which can enhance an application’s processing speed.
Spark was planned for covering a wide range of workloads such as iterative algorithms, batch applications, streaming, and interactive queries. Instead of supporting these workloads, it also reduces the management clog of maintaining different tools.
Going for Apache Spark interview? Read these Top 11 Apache Spark interview questions and get ready to crack the interview!
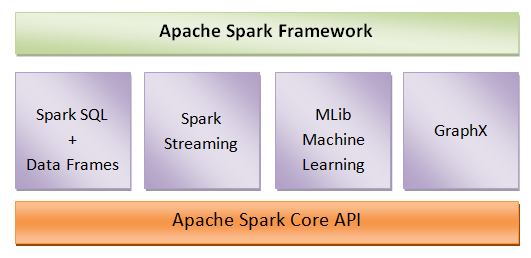
Core Components of Apache Spark Framework
Apache Spark framework consists of the main five components that are responsible for the functioning of the Spark. These components are–
Spark SQL and Data Frames – At the top, Spark SQL allows users to run SQL and HQL queries in order to process structured and semi-structured data.
Spark Streaming – Spark streaming facilitates the processing of live stream data i.e. log files. It also contains APIs to manipulate data streams.
MLib Machine Learning – MLib is the Spark library with machine learning functionality. It contains various machine learning algorithms such as regressions, clustering, collaborative filtering, classification, etc.
GraphX – The library that supports graph computation is known as GraphX. It enables users to perform graph manipulation. It also provides graph computation algorithms.
Apache Spark Core API – It is the kernel of the Spark framework and provides a platform to execute Spark applications.
The diagram below shows a clear picture of the core components of Apache Spark.
There are a number of Big Data tools like Apache Spark. Here is the list of Top 10 Open Source Big Data Tools you can use for Big Data processing!
Apache Spark Limitations
There are some limitations of Apache Spark that user has to face while working on it. This article completely focuses on the Apache Spark limitations and ways to overcome these limitations. Let’s read out the following limitations of Apache Spark in detail and the way to overcome these Apache Spark limitations.
1. No File Management System
There is no file management system in Apache Spark, which need to be integrated with other platforms. So, it depends upon other platforms like Hadoop or any other cloud-based platform for the file management system. This is one of the major Apache Spark limitations.
2. No Real-Time Data Processing
Spark doesn’t support real-time data stream processing fully. In Spark streaming, the live data stream is partitioned into batches, known as Spark RDD (Resilient Distributed Database). The operations like join, map or reduce, etc. are applied to these RDDs to process them. After processing, the result is again converted into batches. This way, Spark streaming is just micro-batch processing. Hence, it does not support full real-time processing but somewhat near to it.
3. Expensive
It is not easy to keep data in memory when we talk about the cost-efficient processing of big data. While working with Spark, memory consumption is very high. Spark needs huge RAM for processing in-memory. The consumption of memory is very high in Spark which doesn’t make it much user-friendly. The additional memory needed to run Spark costs very high which makes Spark expensive.
Planning to become a Data Scientist? Let’s understand why should you Learn Spark to become a Data Scientist?
4. Small Files Issue
There is a problem of small files when we use Spark with Hadoop. HDFS comes with a limited number of large files but a large number of small files. If we use Spark with HDFS, this problem is persistent. But with Spark, all the data is stored as zip files in S3. Now the problem is that all of these small zip files are required to be uncompressed to collect the data files.
It is possible to compress zip files only when the complete file is present at one core. It requires a lot of time to burn cores and unzip files in a sequence only. This time consuming long procedure also affects data processing. For efficient processing, immense shuffling of data is required.
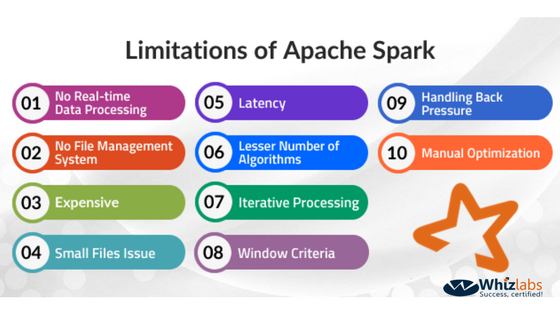
5. Latency
The latency of Apache Spark is higher which results in lower throughput. As compared to Apache Spark, Apache Flink has comparatively lower latency but the higher throughput which makes it better than Apache Spark.
6. The lesser number of Algorithms
In Apache Spark framework, MLib is the Spark library that contains machine learning algorithms. But there are only a few numbers of algorithms in the Spark MLib. So, the lesser available algorithms are also one of the Apache Spark limitations.
Do you know Apache Spark is faster than Hadoop? Here are the top 11 factors that make Apache Spark faster!
7. Iterative Processing
Iteration basically means to use transitional results repeatedly. In Spark, data is iterated in batches, and then for the processing of data each iteration is scheduled and executed one by one.
8. Window Criteria
In Spark streaming, the data is divided into small batches on the basis of preset time intervals. So, Apache Spark supports time-based window criteria but not the record-based.
9. Handling Back Pressure
Back pressure refers to the data buildup at an input/output switch at the time when the buffer is too full to receive any data. Data cannot be transferred until the buffer is empty. Hence, Apache Spark does not have the ability to handle this back pressure but it has to be done manually.
10. Manual Optimization
Manual optimization of jobs, as well as datasets, is required while working with Spark. To make partitions, users can specify the number of Spark partitions on their own. For this, the number of partitions to be fixed is required to pass as the parameter of the parallelize method. In order to get the correct partitions and cache, all these partition procedures should be controlled manually.
Apache Spark is still popular in the Big Data industry. Let’s find out the importance of Apache Spark in Big Data industry!
Despite these limitations, Apache Spark is still one of the popular Big Data tools. But a number of technologies have arrived now to overtake Spark; Apache Flink is one of them. Apache Flink supports real-time data streaming. Thus, Flink streaming is better than Apache Spark Streaming. Databricks certification is one of the top Apache Spark certifications so if you aspire to become certified, you can choose to get Databricks certification.
Bottom Line
Every tool or technology comes with some advantages and limitations. So, the Apache Spark limitations don’t remove it from the game. It’s still in demand and industries are using it as a Big Data solution. The latest versions of Spark are coming with continuous modifications to overcome these Apache Spark limitations.
So, if you are a Spark professional or want to build a career as a Spark professional, there are a lot of opportunities for you in this Big Data world. A Spark developer certification will help you demonstrate your Spark skills to your employer. Whizlabs is aimed to help you have a bright career with Spark Developer Certification (HDPCD) Online Course.
Planning to get certified in Spark? Get Databricks certification that is one of the top here are the 5 best Apache Spark Certification to boost your career!
Start your preparation now and become a certified Spark developer!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
