

Did you come here searching for AWS Certified DevOps Engineer Professional exam-free test questions?
The AWS Certified DevOps Engineer Professional credential enables organizations in the identification and development of talent that carries critical skills required in the implementation of Cloud Initiatives. This is a professional-level certification and provides you with a total of 3 hours to complete the exam.
These questions and answers give you a thorough overview of the exam objectives.
Domain : High Availability, Fault Tolerance, and Disaster Recovery
Q1 : You are a DevOps engineer for a company. With stack policies in place, you have been requested to create a cost-effective rolling deployment solution with minimal downtime. How should you achieve this?
A. Re-deploy your application using an Opsworks template to deploy Elastic Beanstalk.
B. Re-deploy with a CloudFormation template, define update policies on Auto Scaling groups in your CloudFormation template.
C. Use the AutoscalingRollingUpdate attribute to specify how CloudFormation handles updates to the Autoscaling Group Resource.
D. After each stack is deployed, tear down the old stack.
Correct Answers: B and C
Explanation
The AWS::AutoScaling::AutoScalingGroup resource supports an UpdatePolicy attribute. This is used to define how an Auto Scaling group resource is updated when an update to the CloudFormation stack occurs. A common approach to updating an Auto Scaling group is to perform a rolling update, which is done by specifying the AutoScalingRollingUpdate policy. According to the parameters specified, this retains the same Auto Scaling group and replaces old instances with new ones.
Option A is invalid because it is not efficient to use Opsworks to use Elastic Beanstalk.
Option D is invalid because this is an inefficient process to tear down stacks when there are stack policies available.
For more information on Autoscaling Rolling Updates, please refer to the below link: https://aws.amazon.com/premiumsupport/knowledge-center/auto-scaling-group-rolling-updates/
Domain : Configuration Management and Infrastructure as Code
Q2 : You have been requested to use CloudFormation to maintain version control and achieve automation for the applications in your organization. Which of the following options is the best practice to keep everything agile and maintain multiple environments?
A. Create separate templates based on functionality and create nested stacks with CloudFormation.
B. Use CloudFormation custom resources to handle dependencies between stacks.
C. Create multiple templates in one CloudFormation stack.
D. Combine all resources into one template for version control and automation.
Correct Answer: A
Explanation
As your infrastructure grows, common patterns can emerge in which you declare the same components in each of your templates. You can separate out these common components and create dedicated templates for them. That way, you can mix and match different templates but use nested stacks to create a single, unified stack. Nested stacks are stacks that create other stacks. To create nested stacks, use the AWS::CloudFormation::Stackresource in your template to reference other templates.
For more information on Cloudformation best practices, please refer to the below link: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/best-practices.html
Domain : Configuration Management and Infrastructure as Code
Q3 : You have a complex system that involves networking, IAM policies, and multiple, three-tier applications. You are still receiving requirements for the new system. So you don’t yet know how many AWS components will be present in the final design. You want to start using AWS CloudFormation to define these AWS resources so that you can automate and version-control your infrastructure. How would you use AWS CloudFormation to provide agile new environments for your customers in a cost-effective reliable manner?
A. Manually create one template to encompass all the resources that you need for the system. So you only have a single template to version-control.
B. Create multiple separate templates for each logical part of the system, create nested stacks in AWS CloudFormation, and maintain several templates to version-control.
C. Create multiple separate templates for each logical part of the system, and provide the outputs from one to the next using an Amazon Elastic Compute Cloud (EC2) instance running the SDK for finer granularity of control.
D. Manually construct the networking layer using Amazon Virtual Private Cloud (VPC) because this does not change often, and then use AWS CloudFormation to define all other ephemeral resources.
Correct Answer: B
Explanation
As your infrastructure grows, common patterns can emerge in which you declare the same components in each of your templates. You can separate these common components and create dedicated templates for them. That way, you can mix and match different templates but use nested stacks to create a single, unified stack. Nested stacks are stacks that create other stacks. To create nested stacks, use the AWS::CloudFormation::Stackresource in your template to reference other templates.
For more information on Cloudformation best practices, please refer to the below link: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/best-practices.html
Domain : Monitoring and Logging
Q4 : You use Amazon CloudWatch as your primary monitoring system for your web application. After a recent software deployment, your users are getting Intermittent 500 Internal Server Errors when using the web application. You want to create a CloudWatch alarm and notify an on-call engineer when these occur. How can you accomplish this using AWS services?
A. Deploy your web application as an AWS Elastic Beanstalk application. Use the default Elastic Beanstalk Cloudwatch metrics to capture 500 Internal Server Errors. Set a CloudWatch alarm on that metric.
B. Install a CloudWatch Logs Agent on your servers to stream web application logs to CloudWatch.
C. Use Amazon Simple Email Service to notify an on-call engineer when a CloudWatch alarm is triggered.
D. Create a CloudWatch Logs group and define metric filters that capture 500 Internal Server Errors. Set a CloudWatch alarm on that metric.
E. Use Amazon Simple Notification Service to notify an on-call engineer when a CloudWatch alarm is triggered.
Correct Answers: B, D and E
Explanation
You can use CloudWatch Logs to monitor applications and systems using log data.
CloudWatch Logs uses your log data for monitoring; so, no code changes are required. For example, you can monitor application logs for specific literal terms (such as “NullReferenceException”) or count the number of occurrences of a literal term at a particular position in log data (such as “404” status codes in an Apache access log). When the term you are searching for is found, CloudWatch Logs reports the data to a CloudWatch metric that you specify. Log data is encrypted while in transit and while it is at rest.
For more information on Cloudwatch logs, please refer to the below link: http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
Amazon CloudWatch uses Amazon SNS to send email. First, create and subscribe to an SNS topic. When you create a CloudWatch alarm, you can add this SNS topic to send an email notification when the alarm changes state.
For more information on SNS and Cloudwatch logs, please refer to the below link: http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/US_SetupSNS.html
Domain: High Availability, Fault Tolerance, and Disaster Recovery
Q5: You have been tasked with deploying a scalable distributed system using AWS OpsWorks. Your distributed system is required to scale on demand. As it is distributed, each node must hold a configuration file containing the hostnames of the other instances within the layer. How should you configure AWS OpsWorks to manage to scale this application dynamically?
A. Create a Chef Recipe to update this configuration file, configure your AWS OpsWorks stack to use custom cookbooks, and assign this recipe to the Configure LifeCycle Event of the specific layer.
B. Update this configuration file by writing a script to poll the AWS OpsWorks service API for new instances. Configure your base AMI to execute this script on an Operating System startup.
C. Create a Chef Recipe to update this configuration file, configure your AWS OpsWorks stack to use custom cookbooks, and assign this recipe to execute when instances are launched.
D. Configure your AWS OpsWorks layer to use the AWS-provided recipe for distributed host configuration, and configure the instance hostname and file path parameters in your recipes settings.
Correct Answer: A
Explanation
Please check the following AWS DOCs which provides details on the scenario. Check the example of “configure”. https://docs.aws.amazon.com/opsworks/latest/userguide/workingcookbook-events.html
You can use the Configure Lifecycle event.
This event occurs on all of the stack’s instances when one of the following occurs:
- An instance enters or leaves the online state.
- You associate an Elastic IP address with an instance or disassociate one from an instance.
- You attach an Elastic Load Balancing load balancer to a layer or detach one from a layer.
Ensure the Opswork layer uses a custom Cookbook.
For more information on Opswork stacks, please refer to the below document link: from AWS http://docs.aws.amazon.com/opsworks/latest/userguide/welcome_classic.html
Domain : Monitoring and Logging
Q6 : You are considering using AWS CodeStar to create a central place to control and monitor a new app in the AWS platform. It is a Node.js web application that is deployed in a Lambda function. By using a template provided by CodeStar, the project has been built smoothly in 10 minutes. In the AWS CodeStar dashboard for this project, which part of information can you view and monitor?
A. The commit history from CodeCommit.
B. The CodePipeline status includes the stages of source, build and deploy.
C. The application activity status provided by AWS CloudWatch.
D. All the above
Correct Answer: D
Explanation
For a Node.js application in Lambda, the CodeStar project is built on the tools of CodeCommit (source), CodeBuild (build), CloudFormation (Deploy), and CloudWatch (Monitor):
After the project is created successfully, the CodeStar dashboard has provided various valuable information for users.
This has included:
1, The Commit history provided by CodeCommit. Users can quickly have a rough idea of the latest code commit and also access to CodeCommit service to view the details if needed.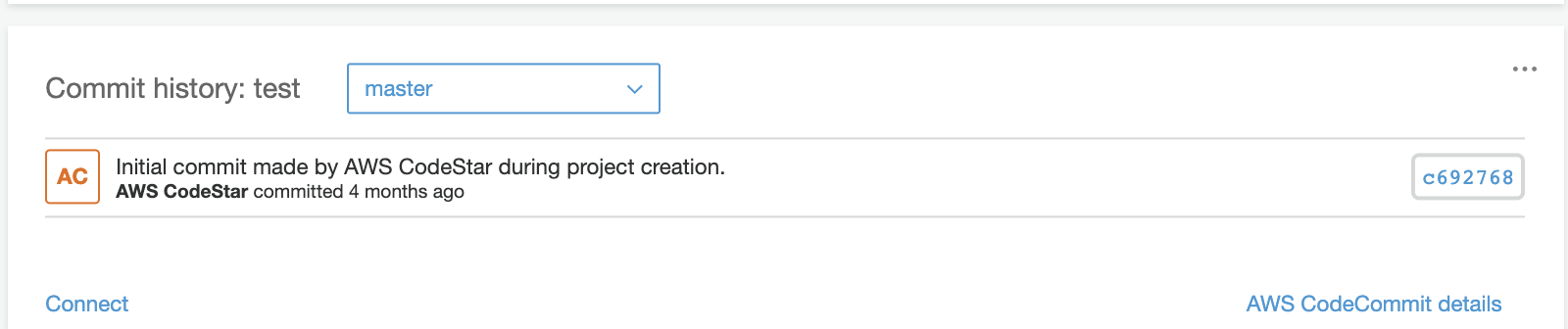
2, The continuous deployment status from CodePipeline service: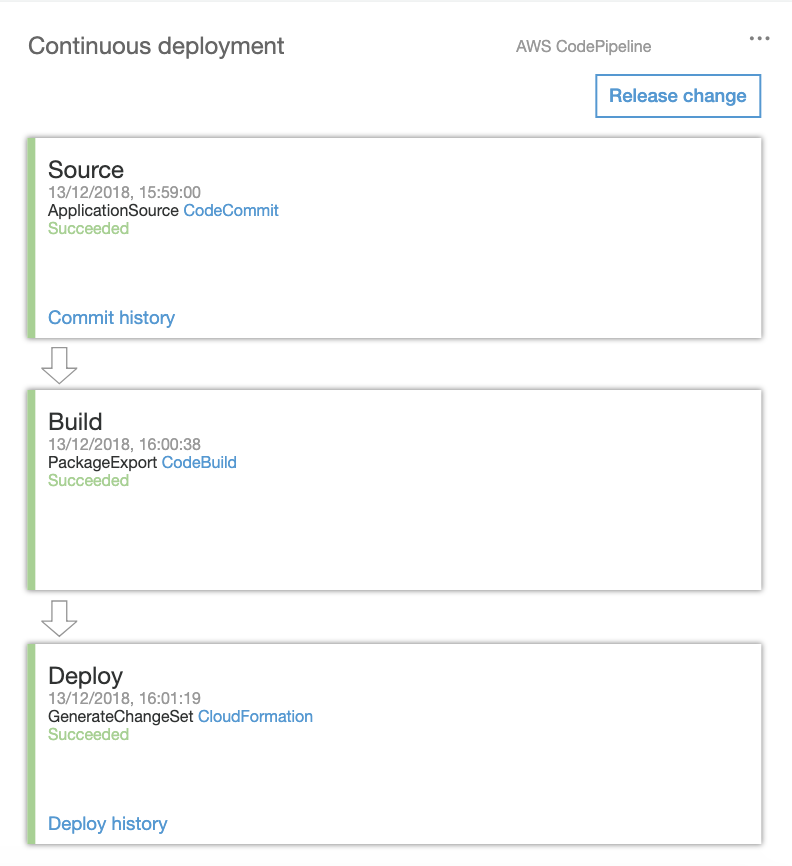
3, The metrics provided by CloudWatch. CodeStar is integrated with CloudWatch which is a monitoring solution to monitor the project’s applications and resources.
Option D is CORRECT: Refer to the explanations as above.
Domain : Monitoring and Logging
Q7 : You have provided AWS consulting service to a financial company that just migrated its major on-premises products to AWS. Last week, there was an outage of AWS hardware which impacted one of the EBS volumes. This failure was alerted in the AWS Personal Health Dashboard. However, it took the team several hours to be aware of that. The company asks for a solution to notify the team when there is an open issue happening in AWS Personal Health Dashboard. Which approach should you recommend?
A. Create a CloudWatch Event Rule that filters AWS Health Event and triggers an SNS notification when there is a new event.
B. In the AWS Personal Health Dashboard console, configure an SNS notification when specific open issues appear.
C. Configure a Lambda function that periodically checks open issues via AWS Health API and triggers an SNS notification if a new issue has been found.
D. Create a new CloudWatch Event that monitors Trusted Advisor service and triggers an SNS notification when there is a new issue.
Correct Answer: A
Explanation
AWS Personal Health Dashboard can show AWS information such as open issues, schedule changes, and event logs that may be relevant to your AWS resources:
The most convenient way to set up notifications is based on AWS CloudWatch Events. The details can be checked in https://docs.aws.amazon.com/health/latest/ug/cloudwatch-events-health.html.
Option A is CORRECT: As below screenshot, a CloudWatch Event rule is created based on AWS Health service, and the user can identify specific event service such as EBS: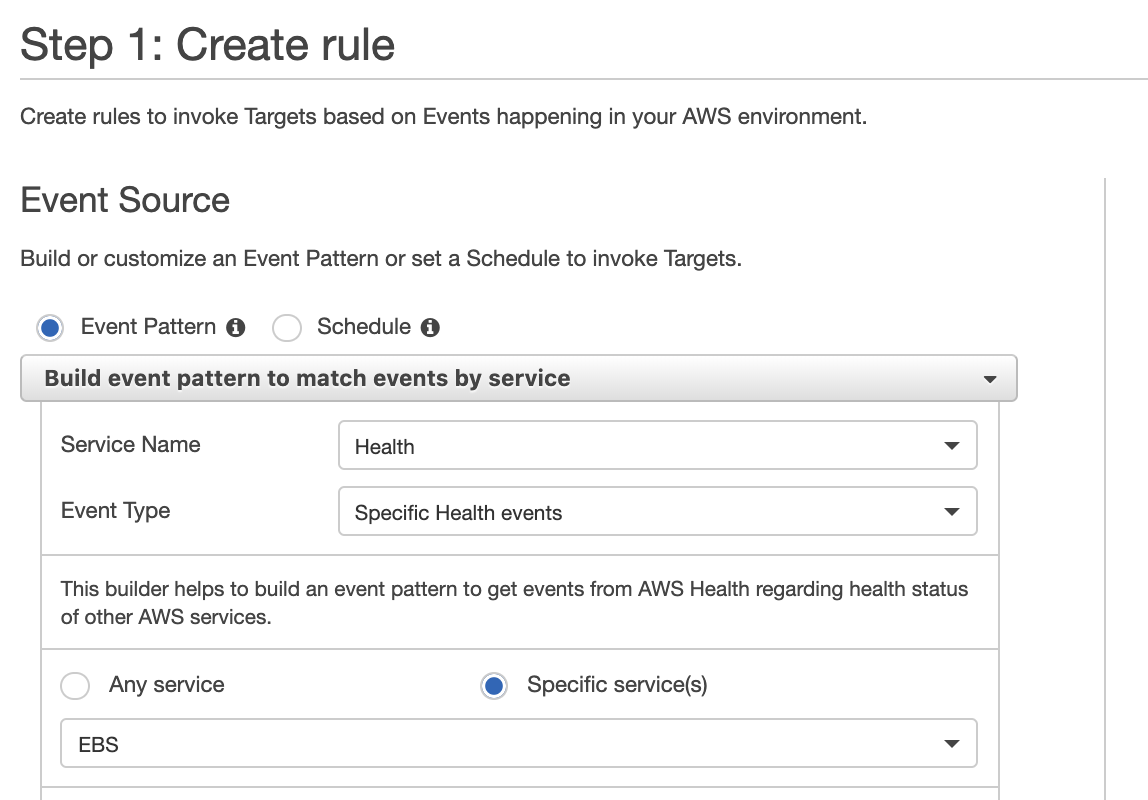
Option B is incorrect: Because there is no way to configure notifications directly in AWS Personal Health Dashboard.
Option C is incorrect: Although this option can work, it is not as simple as Option A. One thing to note is that AWS Health has provided API access with the endpoint in “https://health.us-east-1.amazonaws.com”.
Option D is incorrect: Because it should be a Health service instead of a Trusted Advisor service. The Personal Health Dashboard is provided by AWS Health in the AWS management console.
Domain : Monitoring and Logging
Q8 : You need to perform ad-hoc business analytics queries on well-structured, petabytes of data. Data comes in constantly at a high velocity. Your business intelligence team knows how to use SQL to query data and perform analysis. What AWS service(s) should you use?
A. Kinesis Firehose + RDS
B. Kinesis Firehose + RedShift
C. EMR using Hive
D. EMR running Apache Spark
Correct Answer: B
Explanation
Amazon Kinesis Firehose is the easiest way to load streaming data into AWS. It can capture, transform, and load streaming data into Amazon Kinesis Analytics, Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service, enabling near real-time analytics with existing business intelligence tools and dashboards you’re already using today. It is a fully managed service that automatically scales to match your data’s throughput and requires no ongoing administration. It can also batch, compress, and encrypt the data before loading it, minimizing the amount of storage used at the destination and increasing security.
For more information on Kinesis firehose, please visit the below URL: https://aws.amazon.com/kinesis/firehose/
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers.
For more information on Redshift, please visit the below URL: http://docs.aws.amazon.com/redshift/latest/mgmt/welcome.html
Option A is INCORRECT because the database needs to scale to petabytes of data. Redshift is more suitable for this requirement.
Options C and D are INCORRECT because the ‘data’ is input in a ‘high velocity’, and the suitable option here would be a ‘Kinesis Firehose’ and not EMR.
Domain : Configuration Management and Infrastructure as Code
Q9 : Your team created a DynamoDB table called “Global-Temperature” to track the highest/lowest temperatures of cities in different countries. The items in the table were identified by a partition key (CountryId) and there was no sort key. The application is recently improved with more features and some queries need to be based on a new partition key (CityId) and sort key (HighestTemperature). How should you implement this?
A. Add a Local Secondary Index with a partition key as CityId and a sort key as HighestTemperature.
B. Modify the existing primary index with partition key as CityId and sort key as HighestTemperature.
C. Add a Global Secondary Index with a partition key as CityId and a sort key as HighestTemperature.
D. Add a Global Secondary Index with partition key as CityId and another Global Secondary Index with partition key as HighestTemperature. Because the primary index only uses a simple primary key (partition key), Secondary Index can only have one partition key as well.
Correct Answer: C
Explanation
Commonly, applications might need to perform various queries via different attributes as query criteria. In this case, more global secondary indexes are required. Please refer to https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GSI.html for its introductions.
Option A is incorrect: Because Local Secondary Index can only be configured when the DynamoDB table is created, which means a local secondary index cannot be added to an existing table.
Option B is incorrect: Because the existing primary index cannot be modified. In this scenario, Global Secondary Index should be considered.
Option C is CORRECT: Because Global Secondary Index can achieve this requirement. For example:
Option D is incorrect: Because the Global Secondary index key schema can be different from the base table schema. Even if the table contains a simple primary key (partition key), the global secondary index can still contain a composite primary key (partition key and sort key). This is clearly illustrated in https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GSI.html.
Domain : Configuration Management and Infrastructure as Code
Q10 : What is required to achieve gigabit network throughput on EC2? You already selected cluster-compute, 10GB instances with enhanced networking, and your workload is already network-bound, but you do not see 10 gigabit speeds.
A. Enable biplex networking on your servers. So packets are non-blocking in both directions and there’s no switching overhead.
B. Ensure the instances are in different VPCs, so you don’t saturate the Internet Gateway on any one VPC.
C. Select PIOPS for your drives and mount several so that you can provision sufficient disk throughput.
D. Use a placement group for your instances, so the instances are physically near each other in the same Availability Zone.
Correct Answer: D
Explanation
A placement group is a logical grouping of instances within a single Availability Zone. Placement groups are recommended for applications that benefit from low network latency, high network throughput, or both. To provide the lowest latency and the highest packet-per-second network performance for your placement group, choose an instance type that supports enhanced networking.
For more information on Placement Groups, please visit the below URL: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Domain : Configuration Management and Infrastructure as Code
Q11 : As a DevOps engineer, you are supporting the development team to deploy a new e-commerce software. You have used AWS CodeDeploy to deploy the latest software release to several AWS EC2 instances. In this CodeDeploy application, there are two Deployment groups called Stage and Prod. Currently, the only difference between Stage and Prod is the logging level which can be configured in a file. What is the most efficient way to implement the different logging levels for Deployment groups Stage and Prod?
A. Create two source versions of script files in the BeforeInstall hook. One version has its logging level setting for Deployment Group “Stage”. And the other one has its logging level setting for “Prod”. Choose the relevant source files when creating a new deployment.
B. For the script file in the BeforeInstall hook, use the environment variable DEPLOYMENT_GROUP_NAME to determine the Deployment Group. Then modify the logging level accordingly in the script.
C. In the hook script file, use the environment variable DEPLOYMENT_ID to determine which Deployment Group it is. Then modify the logging level accordingly in the script.
D. Create two script files. One version has its logging level setting for “Stage”. And the other one has its logging level setting for “Prod”. Modify the Deployment Group configurations to use the correct script file.
Correct Answer: B
Explanation
Since the only difference between Deployment Groups is logging level, the same set of sources files should be used with an environment variable to determine the Deployment Group.
About how to use environment variables in AppSec files, check this link https://docs.aws.amazon.com/codedeploy/latest/userguide/reference-appspec-file-structure-hooks.html.
Option A is incorrect: This is not the best solution as two revisions of files have to be maintained.
Option B is CORRECT: Because DEPLOYMENT_GROUP_NAME is the correct environment variable to determine the Deployment Group. The below code can be used in the script file:
if [ “$DEPLOYMENT_GROUP_NAME” == “Staging” ]
then
//modify the logging level here for Staging deployments.
fi
Option C is incorrect: Because DEPLOYMENT_ID is used to tell the specific deployment that is unsuitable for this case.
Option D is incorrect: Because it should not maintain two versions of files. Besides, Deployment Groups cannot be configured to use script files.
Domain : High Availability, Fault Tolerance, and Disaster Recovery
Q12 : You currently have an Autoscaling group that has the following settings.
Min capacity – 2
Desired capacity – 2
Maximum capacity – 4
The current number of instances running in the Autoscaling Group is 2. You have been notified that for a duration of an hour, you need to ensure that no new instances are launched by the Autoscaling Group. What actions would stop the new instances from being launched?
A. Change the Maximum capacity to 2
B. Change the Desired capacity to 4
C. Suspend the Launch process of the Autoscaling Group
D. Change the Minimum capacity to 2
Correct Answers: A and C
Explanation
You can temporarily suspend the creation of new instances by either reducing the maximum capacity to 2 so that the current instances running which is 2 matches the maximum limit.
Secondly, you can suspend the launch process of the Autoscaling Groups.
The AWS Documentation mentions.
Scaling Processes
Amazon EC2 Auto Scaling supports the following scaling processes:
Launch
Adds a new EC2 instance to the group, increasing its capacity.
Warning
If you suspend Launch, this disrupts other processes. For example, you can’t return an instance in a standby state to service if the Launch process is suspended, because the group can’t scale.
For more information on Autoscaling Suspend and Resume, please visit the below URL: http://docs.aws.amazon.com/autoscaling/latest/userguide/as-suspend-resume-processes.html
Domain : SDLC Automation
Q13 : A DevOps engineer is building up a pipeline for a Java project which is under development. AWS CodePipeline service has been chosen as the CI/CD tool. For the service deployment phase, CloudFormation stacks are used. However, there are several situations to be considered. For example, (i) stack should be created if a stack does not exist, (ii) Change Set should be created and inspected if a stack already exists. The team lead prefers to implement a visualized state machine for the deployment and each state executes a Lambda function. What is the best way to achieve this requirement?
A. Establish several SQS queues to indicate running status. The Lambda function for each state gets the message from the queue and processes the deployment task accordingly. The final result is returned to CodePipeline by a dedicated Lambda.
B. Use a Python script in EC2 to record the running status and achieve the state machine feature. It calls different Lambda functions depending on the current status. The script returns the execution status back to CodePipeline.
C. Use a Lambda Function to interface with an AWS Step Functions which implements the workflow-driven state machines for CloudFormation stack deployment. The Lambda Function returns the execution status back to CodePipeline.
D. Use a shell script in EC2 to interface with the AWS MQ service to achieve the function of the state machine. Depending on the running status of the AWS MQ service, the script returns the execution result back to CodePipeline.
Correct Answer: C
Explanation
A visualized state machine is required in this question. AWS Step Functions is the best tool to achieve this. About how to integrate with AWS CodePipeline for AWS Step Functions, check this document in https://aws.amazon.com/blogs/devops/using-aws-step-functions-state-machines-to-handle-workflow-driven-aws-codepipeline-actions/.
Option A is incorrect: Because SQS is not ideal for implementing a state machine. It also cannot provide a native visualized status as Step Functions.
Option B is incorrect: Similar reason as Option A.
Option C is CORRECT: Because AWS Step Functions makes it easy for users to understand which tasks have been executed and why a state has been reached. It also can interact with Lambda and inform AWS CodePipeline of its status.
Option D is incorrect: Because AWS MQ service is a service for ActiveMQ that can set up and operate message brokers in AWS. It is not an ideal tool to achieve a work-flow driven state machine.
Domain : Policies and Standards Automation
Q14 : You’re building a mobile application game. The application needs permissions for each user to communicate and store data in DynamoDB tables. What is the best method for granting each mobile device that installs your application to access DynamoDB tables for storage when required?
A. During the install and game configuration process, each user creates an IAM credential and assigns the IAM user to a group with proper permissions to communicate with DynamoDB.
B. Create an IAM group that only gives access to your application and the DynamoDB tables. When writing to DynamoDB, include the unique device ID to associate the data with that specific user.
C. Create an IAM role with the proper permission policy to communicate with the DynamoDB table. Use web identity federation, which assumes the IAM role using AssumeRoleWithWebIdentity, when the user signs in, granting temporary security credentials using STS.
D. Create an Active Directory server and an AD user for each mobile application user. When the user signs in to the AD sign-on, allow the AD server to federate using SAML 2.0 to IAM and assign a role to the AD user assumed with AssumeRoleWithSAML.
Correct Answer: C
Explanation
For access to any AWS service, the ideal approach for any application is to use Roles. This is the first preference.
For more information on IAM policies, please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html
Next, for any web application, you need to use a web identity federation. Hence option C is the right option. This, along with the usage of roles, is highly stressed in the AWS documentation.
The AWS documentation mentions the following.
When developing a web application, it is recommended not to embed or distribute long-term AWS credentials with apps that a user downloads to a device, even in an encrypted store. Instead, build your app so that it requests temporary AWS security credentials dynamically when needed using web identity federation. The supplied temporary credentials map to an AWS role that has only the permissions needed to perform the tasks required by the mobile app.
For more information on web identity federation, please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_oidc.html
Domain : Configuration Management and Infrastructure as Code
Q15 : A team has implemented a service with AWS API Gateway and Lambda. The service endpoint can save input JSON data to the internal database and S3. After the service has run for several years, some data in the JSON body are no longer used and should not be saved anymore. The backend Lambda has been upgraded to support only the valid JSON values. The original API in API Gateway is still used for some time before all users migrate to the new API. How should the original API be configured so that the Lambda still supports the old request in the backend?
A. In the original API, add a stage for canary deployment to understand how many users are still using the old JSON format before the original API service is completely removed.
B. Configure a mapping template in Integration Request to remove the obsolete data so that the original API requests are transformed to be supported by the new Lambda.
C. In the original API, use a new Lambda as an authorizer so that only the requests with valid JSON data can proceed to hit the backend.
D. In Integration Response of the API, add a mapping template to remove the obsolete data for the backend Lambda to support the old requests.
Correct Answer: B
Explanation
In this question, the backend Lambda is already upgraded, and the original API is kept for some time. However, Lambda only supports the new requests without obsolete data in the JSON body, which means that a mapping template is needed to map the original requests to the new ones in Integration Request.
Option A is incorrect: Because the canary deployment in stage configuration can be regarded as a deployment strategy, which does not help support the original requests.
Option B is CORRECT: Because a mapping template can transform the request to the proper format. From the original users’ perspective, nothing has changed.
Option C is incorrect: Because old requests will be blocked by the authorizer. This is unacceptable.
Option D is incorrect: Because it should be Integration Request instead of Integration Response to add the mapping template.
Domain: Incident and Event Response
Q16: You are responsible for maintaining several AWS CloudFormation templates. Last month, there were two incidents in that resources in the existing CloudFormation stacks that someone has changed without any alerts or notifications. Because of that, the potential changes may have negative impacts on the stacks, and the changes may be lost if the stacks are re-deployed. This is not compliant with company policy. Your team lead asked you to warn the team whenever a drift in the CloudFormation stack appears. What is the best way to achieve that?
A. Use a Lambda function to check the drift status in each CloudFormation stack every 10 minutes. If there is a drift, send the team an email via the AWS SES service.
B. Create a rule in AWS Config to evaluate if the stack is considered to have drifted for its resources. If the rule is NON_COMPLIANT, notify the team via an SNS notification.
C. Create a CloudWatch event rule for CloudFormation. If any event happens for CloudFormation, trigger an email notification by SNS.
D. Enable CloudTrail. Use a Lambda function to analyze the CloudTrail logs. Send an email if it is found that the resources in CloudFormation stacks are modified.
Correct Answer: B
Explanation
In AWS Config, there is an AWS managed rule (cloud formation-stack-drift-detection-check
To check if there is a drift, refer to https://docs.aws.amazon.com/config/latest/developerguide/cloudformation-stack-drift-detection-check.html
for details.
Option A is incorrect: Because this is not as straightforward as Option B. And SES is unsuitable to be a notification service. It should be SNS.
Option B is CORRECT: Because it can quickly set up a rule to manage the drift status, and users can understand if the stacks are compliant or not.
Option C is incorrect: Because it should not be an event for the CloudWatch Event rule since the question only asks for the situation of stack drift.
Option D is incorrect: Extra efforts are required such as creating a Lambda function. Option B is much simpler as the AWS Config rule can easily identify a drift via an AWS-managed rule.
Domain: SDLC Automation
Q17: Which of the following will you need to consider so you can set up a solution that incorporates a single sign-on from your corporate AD or LDAP directory and restricts access for each user to a designated user folder in a bucket?
A. Setting up a federation proxy or identity provider.
B. Using AWS Security Token Service to generate temporary tokens.
C. Tagging each folder in the bucket
D. Configuring IAM role
E. Setting up a matching IAM user for every user in your corporate directory that needs access to a folder in the bucket.
Correct Answers: A, B, and D
Explanation
The below diagram showcases how authentication is carried out when having an identity broker. This is an example of a SAML connection, but the same concept holds true for getting access to an AWS resource.
For more information on federated access, please visit the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_common-scenarios_federated-users.html, https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-idp_saml.html?icmpid=docs_iam_console, https://aws.amazon.com/blogs/security/writing-iam-policies-grant-access-to-user-specific-folders-in-an-amazon-s3-bucket/
Domain : Configuration Management and Infrastructure as Code
Q18 : What does the ‘Swap Environment URLs’ feature aid most directly when thinking of AWS Elastic Beanstalk?
A. Immutable Rolling Deployments
B. Mutable Rolling Deployments
C. Canary Deployments
D. Blue-Green Deployments
Correct Answer: D
Explanation
The AWS Documentation mentions the following.
Because Elastic Beanstalk performs an in-place update when you update your application versions, your application may become unavailable to users for a short period of time. It is possible to avoid this downtime by performing a blue/green deployment, where you deploy the new version to a separate environment and then swap CNAMEs of the two environments to redirect traffic to the new version instantly.
Blue/green deployments require that your environment runs independently of your production database, if your application uses one. If your environment has an Amazon RDS DB instance attached to it, the data will not transfer over to your second environment. They will be lost if you terminate the original environment.
For more information on Blue/Green deployments with AWS, please visit the link – http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features.CNAMESwap.html
Domain: Configuration Management and Infrastructure as Code
Q19: Which of the following are true with regard to Opsworks stack Instances?
A. A stacks instances can be a combination of both Linux and Windows-based operating systems.
B. You can use EC2 Instances that were created outside the boundary of Ops work.
C. You can use instances running on your own hardware.
D. You can start and stop instances manually.
Correct Answers: B, C, and D
Explanation
The AWS Documentation mentions the following
1) You can start and stop instances manually or have AWS OpsWorks Stacks automatically scale the number of instances. You can use time-based automatic scaling with any stack; Linux stacks also can use load-based scaling.
2) In addition to using AWS OpsWorks Stacks to create Amazon EC2 instances, you can also register instances with a Linux stack that were created outside of AWS OpsWorks Stacks. This includes Amazon EC2 instances and instances running on your own hardware. However, they must be running one of the supported Linux distributions. You cannot register Amazon EC2 or on-premises Windows instances.
3) A stack’s instances can run either Linux or Windows. A stack can have different Linux versions or distributions on different instances, but you cannot mix Linux and Windows instances.
For more information on Opswork instances, please visit the below url http://docs.aws.amazon.com/opsworks/latest/userguide/workinginstances-os.html
Domain: SDLC Automation
Q20: A large company uses AWS CodeCommit to manage its source code. There are over a hundred of repositories and many teams are working on different projects. As a DevOps engineer, you need to allocate suitable access to different users. For example, the development team should not access the repositories that contain sensitive data. How should you manage this?
A. Tag repositories in AWS CodeCommit. Create policies in IAM that allow or deny actions on repositories based on the tags associated with repositories.
B. In the AWS CodeCommit console, create CodeCommit policies for IAM groups that allow or deny actions on repositories.
C. Configure Git tags in AWS CodeCommit repositories. Create policies in IAM that allow or deny actions on repositories based on the Git tags.
D. In IAM, for each IAM user, add an IAM policy that allows or denies actions on repositories based on repository names.
Correct Answer: A
Explanation
In July 2019, CodeCommit has a new feature to support adding tags in its repositories. For details refer to https://aws.amazon.com/about-aws/whats-new/2019/07/aws-codecommit-now-supports-resource-tagging/.
Option A is CORRECT: Because with tags, an IAM policy can be easily configured to control the access. For example:
{
“Version”: “2012-10-17”,
“Statement” : [
{
“Effect” : “Deny”,
“Action” : “codecommit:*”
“Resource” : “*”,
“Condition” : {
“StringEquals” : “aws:ResourceTag/Department”: “BigData”
}
}
]
}
Option B is incorrect: Because there is no CodeCommit policy. In this case, IAM policy should be used.
Option C is incorrect: Although Git tag is supported in CodeCommit, in this scenario, tags of repositories should be used instead of Git tags.
Option D is incorrect: The company owns over a hundred of repositories. It is inappropriate and inefficient to create an IAM policy per IAM user based on repository names.
Domain : SDLC Automation
Q21 : You have just developed a new mobile application that handles analytics workloads on large scale datasets that are stored on Amazon Redshift. Consequently, the application needs to access Amazon Redshift tables. Which of the below methods would be the best, both practically and security-wise, to access the tables?
A. Create an IAM user and generate encryption keys for that user. Create a policy for RedShift read-only access. Embed the keys in the application.
B. Create a HSM client certificate in Redshift and authenticate using this certificate.
C. Create a RedShift read-only access policy in IAM and embed those credentials in the application.
D. Use roles that allow a web identity federated user to assume a role that allows access to the RedShift table by providing temporary credentials.
Correct Answer: D
Explanation
For access to any AWS service, the ideal approach for any application is to use Roles. This is the first preference. Hence option A and C are wrong.
For more information on IAM policies please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html
Next for any web application, you need to use web identity federation. Hence option D is the right option. This along with the usage of roles is highly stressed in the AWS documentation.
“When you write such an app, you’ll make requests to AWS services that must be signed with an AWS access key. However, we strongly recommend that you do not embed or distribute long-term AWS credentials with apps that a user downloads to a device, even in an encrypted store. Instead, build your app so that it requests temporary AWS security credentials dynamically when needed using web identity federation. The supplied temporary credentials map to an AWS role that has only the permissions needed to perform the tasks required by the mobile app”.
For more information on web identity federation please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_oidc.html
Domain : Policies and Standards Automation
Q22 : A company has purchased a software license and installed the software in on-premise servers. The servers are being migrated from on premise to AWS EC2 and the license requires that the software should be installed in the same EC2 physical hosts. As a DevOps engineer, you need to deploy the EC2 instances and manage the software license properly. Which combinations of services would you choose to achieve the requirements?
A. Launch EC2 instances with auto-placement hosts to install the software. Manage the software license in AWS Service Catalog with a license configuration.
B. Create reserved EC2 instances to install the software. Reserve Elastic IPs and associate them with the instances. Manage the software license through an AWS Config rule.
C. Create an EC2 Capacity Reservation for the EC2 instances to install the software. Manage the license in AWS System Manager by counting the number of used vCPUs. Trigger an SNS notification when the license reaches its limits.
D. Host the applications in EC2 dedicated hosts and manage the software license through AWS License Manager.
Correct Answer: D
Explanation
As the software license asks for the same physical hosts, EC2 dedicated hosts should be used. EC2 dedicated host is also integrated with AWS License Manager which is a service to help you manage the software licenses. Details can be found in https://aws.amazon.com/ec2/dedicated-hosts/.
Option A is incorrect: With auto-placement hosts, the EC2 instances are launched on pre-allocated hosts. The first part of the answer is correct. However, AWS Service Catalog is not appropriate to manage software licenses.
Option B is incorrect: Because either reserved EC2 instances or Elastic IPs cannot guarantee that the software runs on the same physical hosts.
Option C is incorrect: A Capacity Reservation helps to reserve the specified capacity for your use. But it does not determine the dedicated hosts for EC2 instances. Besides, AWS System Manager is not suitable to manage licenses.
Option D is CORRECT: The combinations of EC2 dedicated hosts and AWS License Manager can achieve the requirements.
Domain : SDLC Automation
Q23 : Your organization owns several AWS accounts. The AWS operation team creates several base docker images in AWS ECR. Another development team is working on a new project in which the build phase needs to use AWS CodeBuild to build artifacts. One requirement is that the environment image of CodeBuild must use an ECR docker image owned by the operation team. However, the ECR docker image is located in different AWS account. How would you resolve this and create the CodeBuild project?
A. Select AWS managed Ubuntu image. In the image, pull the ECR docker image from another account.
B. CodeBuild does not support cross account ECR image. Copy the image to the ECR registry in the same account first.
C. Select custom image and choose ECR image registry. Enter the full ECR repository URI for the repository in the other account.
D. Select custom image and choose Other registry for an external Docker registry. In external registry URI, enter the ECR repository URI of the other account.
Correct Answer: C
Explanation
AWS CodeBuild supports accessing cross-account ECR images according to
Option A is incorrect: Because AWS managed image should not be used. For ECR images, custom image should be configured.
Option B is incorrect: Because cross-account ECR image is supported.
Option C is CORRECT: Refer to the below example: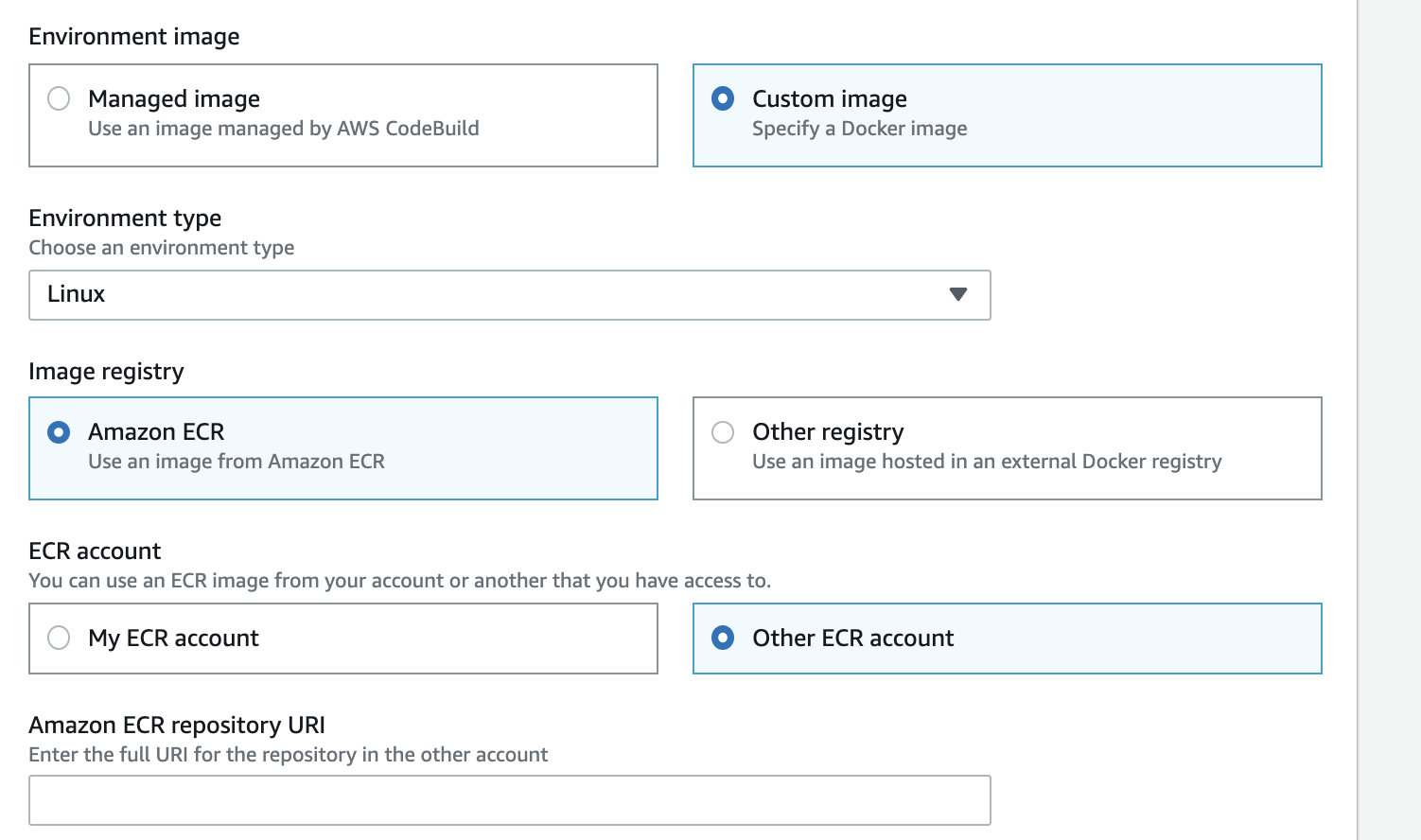
Option D is incorrect: Because external Docker registry is not used for AWS ECR. Other registries such as public DockerHub would use external Docker registry.
Domain : Monitoring and Logging
Q24 : You are a Devops Engineer for your company. You are planning on using Cloudwatch for monitoring the resources hosted in AWS. Which of the following can you do with Cloudwatch logs ideally.
A. Stream the log data to Amazon Kinesis for further processing
B. Send the log data to AWS Lambda for custom processing
C. Stream the log data into Amazon Elasticsearch for any search analysis required.
D. Send the data to SQS for further processing.
Correct Answers: A, B and C
Explanation
Amazon Kinesis can be used for rapid and continuous data intake and aggregation. The type of data used includes IT infrastructure log data, application logs, social media, market data feeds, and web clickstream data
Amazon Lambda is a web service which can be used to do serverless computing of the logs which are published by Cloudwatch logs
Amazon Elasticsearch Service makes it easy to deploy, operate, and scale Elasticsearch for log analytics, full text search, application monitoring, and more.
For more information on Cloudwatch logs please see the below link: http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
Domain : Monitoring and Logging
Q25 : A financial company has used Kinesis Stream to store system logs in real time from a busy application. Then the data in Kinesis Stream is sent to a Kinesis Firehose delivery stream which delivers data to the final S3 bucket destination. The input data format is RFC3163 Syslog however it is required to convert the format to JSON in Kinesis Firehose before the data is delivered. How should you implement this?
A. Create a Lambda function for data transformation using a blueprint. Kinesis Data Firehose can invoke the Lambda function to transform incoming source data.
B. In Kinesis Data Firehose, invoke AWS Glue to create a schema in order to modify the format of incoming source data.
C. Configure Kinesis Data Firehose to use third party JSON deserializer tool Apache Hive JSON SerDe to convert the data to JSON format.
D. Kinesis Firehose cannot transform the data format inside of it. Instead it has to be done in Kinesis Stream.
Correct Answer: A
Explanation
Refer to https://docs.aws.amazon.com/firehose/latest/dev/data-transformation.html
for how to transform data format in Kinesis Data Firehose.
Option A is CORRECT: Kinesis Data Firehose provides the following Lambda blueprint to convert Syslog to JSON:
Option B is incorrect: AWS Glue can create a schema in AWS Glue Data Catalog however it cannot convert the data format in Kinesis Firehose.
Option C is incorrect: Apache Hive JSON SerDe can be used to serialize/deserialize JSON data. It is not used to convert Syslog to JSON.
Option D is incorrect: Because Kinesis Stream should not be used to convert data format. This can be done in Kinesis Firehose. Data transformation is also very common for Kinesis Firehose:
Summary
Did you find these AWS Certified DevOps Engineer Professional free test questions helpful? Follow our official website for more Practice Test Questions for the DevOps Engineer Professional exam. If you spend more time on learning, then you are able to pass the certification exam within the first attempt. Stay tuned with us for more updates!
- Top 25 DevSecOps Interview Question and Answers for 2024 - March 1, 2023
- How to prepare for VMware Certified Technical Associate [VCTA-DCV] Certification? - February 14, 2023
- Top 20 Cloud Influencers in 2024 - January 31, 2023
- 25 Free Question on SC-100: Microsoft Cybersecurity Architect - January 27, 2023
- Preparation Guide on MS-101: Microsoft 365 Mobility and Security - December 26, 2022
- Exam tips to prepare for Certified Kubernetes Administrator: CKA Exam - November 24, 2022
- Why do you need to upskill your teams with the Azure AI fundamentals? - October 11, 2022
- The best employee retention strategy for IT industries – UPSKILLING - September 26, 2022