Apache Storm is a free and open source distributed real-time computation system. It makes everything simple to process unbounded streams of data in a reliable manner. It is easy to use and works with any programming language. Written mainly in the ‘Clojure’ and ‘Java’ programming languages, it makes use of ‘Spouts’ and ‘Bolts’ to run application-specific logic.
The latest stable version is ‘2.2.0’ which is a June 2020 release.
Originally created by ‘Nathan Marz’ and team at ‘Backtype’, it was open sourced after being acquired by Twitter. It is scalable, fast, fault-tolerant, guarantees that the data is processed and easy to set up and operate. It has a record of processing a million tuples per second per node.
Storm joined the Apache Software Foundation as an incubator project delivering high-end applications. Since then, Apache Storm has been meeting the demands of Big Data Analytics.
Its applications include:
- Real-time Analytics
- Online Machine Learning
- Continuous Computation
- Distributed RPC
- ETL
It is integrated with Hadoop to maximise throughput and can work with any programming language. It is scalable and ensures that the data is processed. It is simple to set up and get in action.
Apache Storm integrates with the existing queueing and database technology. An Apache Storm topology consumes data streams and processes them in arbitrarily complex ways, repartitioning the streams as needed between stages of computation.
Some major organisations using Apache Storms are:
- Twitter- Twitter uses Apache Storm for its “Publisher Analytics products.” Every tweet and click on the Twitter Platform is processed by “Publisher Analytics Products”. Twitter’s infrastructure is deeply integrated with Apache Storm.
- NaviSite- Storm is NaviSite’s event log monitoring/Auditing system. Every log generated by the system will be processed by Storm. Storm will compare the message to the configured set of regular expressions, and if a match is found, the message will be saved to the database.
- Wego- Wego is a Singapore-based travel metasearch engine. Travel-related data is gathered from a variety of sources around the world at varying times. Storm assists Wego in searching real-time data, resolving concurrency issues, and determining the best match for the end user.
Advantages Apache Storm offers:
- Real-time stream processing is possible and equipped with operational intelligence.
- Storm is extremely fast because it has humongous data processing power.
- Storm can maintain performance even under increasing load by adding resources in a linear fashion.
- Storm refreshes data and provides end-to-end delivery responses in seconds or minutes, depending on the problem. It has extremely low latency.
- Storm guarantees data processing even if any of the cluster’s connected nodes fail or messages are lost.
Topology:
A topology is a graph of computation.Topologies are created to perform real-time computations on Storm. Each node herein contains processing logic, and links between nodes suggest how data should be passed between them.
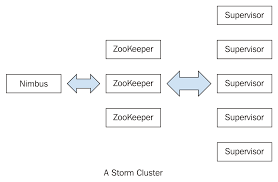
Storm Cluster:
A Storm cluster is slightly similar to a Hadoop cluster. While on Hadoop, you run “MapReduce jobs”, on Storm “topologies” are run. And where a MapReduce job eventually finishes, a topology processes messages indefinitely or until you kill it.
On a Storm cluster, there are two types of nodes:
- Master nodes, and
- Worker nodes.
The master node runs a “Nimbus” daemon, which is similar to Hadoop’s “JobTracker.” Nimbus is in charge of distributing code throughout the cluster, assigning tasks to machines, and monitoring for failures.
Each worker node runs the “Supervisor” daemon. The supervisor listens for work assigned to its machine and initiates and terminates worker processes as needed based on what Nimbus has assigned to it.
A running topology is made up of many worker processes distributed across multiple machines and each worker process executes a subset of topology. All communication between Nimbus and the Supervisors takes place via a Zookeeper cluster. Furthermore, the Nimbus and Supervisor daemons are fail-safe and stateless. All state is stored in Zookeeper or on a local disc. This means that even if you kill -9 Nimbus or the Supervisors, they will restart as if nothing happened.
Storm clusters are extremely stable as a result of this design.
Running a Topology:
Running a Topology is simple.
- Package all the code and dependencies into a single jar
- Execute the following command
‘storm jar all-my-code.jar org.apache.storm.MyTopology arg1 arg2’
This invokes the class org.apache.storm.MyTopology with the arguments ‘arg1’ and ‘arg2’. The primary function of the class that defines the topology and submits it to Nimbus. The storm jar connects to Nimbus and uploads the jar. This is the simplest way of running it via a JVM based language.
Since Nimbus is a thrift service, topologies can be created and submitted using any programming language.
Streams:
A Stream is an unbounded sequence of tuples. Stream is the core abstraction in Storm.
Storm provides the basis for transforming an existing stream into a new stream in a distributed and dependable manner. You could, for example, turn a stream of tweets into a stream of trending topics.
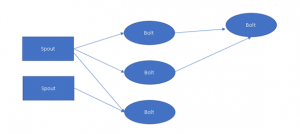
Storm’s basic primitives for performing stream transformation are “spouts” and “bolts.” Spouts and bolts have interfaces that could be used to implement application-specific logic.
A Spout is a stream source. A Spout, for example, could read tuples from a Kestrel queue and emit them as a stream. A Spout could also connect to the Twitter API and send out a stream of tweets.
A Bolt takes in a number of input streams, processes them, and may emit new streams. Complex stream transformations, such as generating a stream of trending topics from a stream of tweets, necessitate multiple steps and, as a result, multiple bolts. Bolts can filter tuples, perform streaming aggregations, carry out streaming joins, communicate with databases, run functions and much more.
Spout and Bolt networks are packaged into a “topology,” which is the top-level abstraction that you provide to Storm clusters to run. A topology is a graph of stream transformations, with each node representing either a spout or a bolt. The graph’s edges show the bolts subscribed to respective streams. When a spout or bolt emits a tuple to a stream, the tuple is sent to every bolt that has subscribed to that stream.
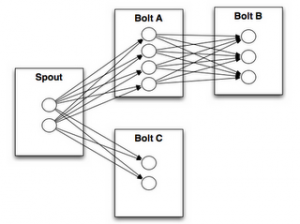
The connections between your topology’s nodes indicate how tuples should be passed around. For instance, if there exists a link between Spout A and Bolt B, a link between Spout A and Bolt C, and a link between Bolt B and Bolt C, then whenever Spout A emits a tuple, it will be sent to both Bolt B and Bolt C. Moreover, all of Bolt B’s output tuples will be sent to Bolt C.
In a Storm topology, every node executes in parallel. You can specify the amount of parallelism you want for each node in your topology, and Storm will spawn that number of threads across the cluster to execute the code. A topology exists indefinitely, or until terminated. Any failed tasks will be reassigned automatically by Storm.
These features were part of Storm’s reliability API, which describes how Storm ensures that every message that comes off a spout is fully processed. Information on how this works and what you need to do as a user to take advantage of Storm’s reliability capabilities, see Guaranteeing message processing.
Data Model:
Storm makes use of Tuples as its data model.
Tuple:
A Tuple is a named list of values and a field in any Tuple could be an Object of any type. Storm supports all the primitive types, string and byte arrays as Tuple field values.
Stream Groupings:
A Stream grouping tells a topology how to send tuples between two components.
Ensuring Message Processing:
Trident
Storm ensures that every message is routed via the topology at least once. A frequently asked question is “On top of Storm, how do you do things like count? Will you not overestimate?”. Trident is a higher-level API in Storm that allows you to achieve exactly-once messaging semantics for most computations.
Distributed RPC
Storm’s primitives can be used for a variety of other purposes. Distributed RPC is one of the Storm’s most fascinating applications, in which you parallelize the computation of intensive functions on the go.
Conclusion
The Apache Storm provides various functions and services for computations. With its integrated queueing system and database system, everything becomes easy. It is a distributed, fault-tolerant, open-source computation system which can process streams of a variety of data in real-time. It provides guaranteed processing of data, which provides the ability to replay data that was not successful the first time it was processed.
You can use multiple languages in Storm like Python and you can also use it in some situations such as Internet of Things (IoT), Fraud detection, Social analytics, Extraction, Transformation and Loading (ETL), Network monitoring, Search, and Mobile engagement from multiple platforms.
Also read:
Understanding MapReduce in Hadoop
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021