

This is the comprehensive guide that will help you learn Apache Spark. Starting from the introduction, I’ll show you everything you want to know about Apache Spark. Sounds good? Let’s dive right in..
What is Apache Spark? Why there is a buzz all around about this technology? Why is it important to learn Apache Spark? This definite guide will help you to get the answer to all of these questions.
2011, Yes! It was the year when I first heard of the term “Apache Spark”. It was the time when I developed an interest in learning Scala; it is the language in which Spark has been written. Just then I felt myself to learn Apache Spark, and I started without giving any second thought. And now, I’m turning all my study, knowledge, and experience into a comprehensive guide to learning Apache Spark. It is surely going to be a recommended place for Big Data Spark professionals to get started!
Let’s start learning Apache Spark!
It’s Time to Learn Apache Spark
For the analysis of big data, the industry is extensively using Apache Spark. Hadoop enables a flexible, scalable, cost-effective, and fault-tolerant computing solution. But the main concern is to maintain the speed while processing big data. The industry needs a powerful engine that can respond in less than seconds and perform in-memory processing. Also, that can perform stream processing as well as batch processing of the data. This is what made Apache Spark come into existence!
Apache Spark is a powerful open-source framework that provides interactive processing, real-time stream processing, batch processing as well as the in-memory processing at very fast speed, with standard interface and ease of use. This is what creates the difference between Spark vs Hadoop.
What is Apache Spark?
The Spark is a project of Apache, popularly known as “lightning fast cluster computing”. Spark is an open-source framework for the processing of large datasets. It is the most active Apache project of the present time. Spark is written in Scala and provides APIs in Python, Scala, Java, and R.
The most important feature of Apache Spark is its in-memory cluster computing that is responsible to increase the speed of data processing. Spark is known to provide a more general and faster data processing platform. It helps you run programs comparatively faster than Hadoop i.e. 100 times faster in memory and 10 times faster even on the disk.
Worth mention, contradicting a common misbelief, Apache Spark cannot be considered as a modified version of Apache Hadoop. Spark has its own cluster management, so it’s not dependent on Hadoop. But Spark is just a way to implement Spark. Spark uses Hadoop only for storage purpose.
Apache Spark Features
Apache Spark introduction cannot be completed without mentioning Apache Spark features. So, let’s move one step ahead and learn Apache spark features.
Multiple Language Support
Apache Spark supports multiple languages; it provides APIs written in Scala, Java, Python or R. It allows users to write applications in different languages. Note that Spark comes up with 80 high-level operators for interactive querying.
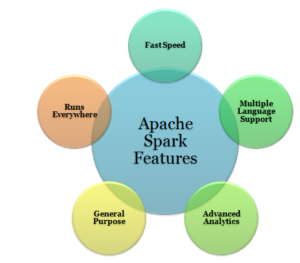
Fast Speed
The most important feature of Apache Spark is its processing speed. It allows an application to run on Hadoop cluster, up to 100 times faster in memory, and 10 times faster on disk. It is done by the reduction of the number of read/write operations to the disk by storing intermediate data in memory.
Apache Spark is faster than other big data processing frameworks. Let’s check out Top 11 Factors That Makes Apache Spark Faster!
Advanced Analytics
Apache Spark is known to support ‘Map’ and ‘Reduce’ that has been mentioned earlier. But along with MapReduce, it supports Streaming data, SQL queries, Graph algorithms, and Machine learning. Thus, Apache Spark is a great mean of performing advanced analytics.
General Purpose
The spark is a powered by the plethora of libraries for machine learning i.e. MLlib, DataFrames, and SQL along with Spark Streaming and GraphX. One is allowed to use a combination of these libraries coherently in an application. The feature of combining streaming, SQL, and complex analytics, and using in the same application makes Spark a general-purpose framework.
Runs Everywhere
Spark can run on multiple platforms without affecting the processing speed. It can run on Hadoop, Kubernetes, Mesos, Standalone, and even in the Cloud. Also, Spark can have access to different sources of data such as HDFS, HBase, Cassandra, Tachyon, and S3.
Components of Apache Spark Ecosystem
Apache Spark Ecosystem comprises of various Apache Spark components that are responsible for the functioning of the Apache Spark. Several modifications are made in the components of Apache Spark time to time. Primarily, these are 5 components of Apache Spark that constitute Apache Spark ecosystem. So now, we are going to learn Apache Spark components –
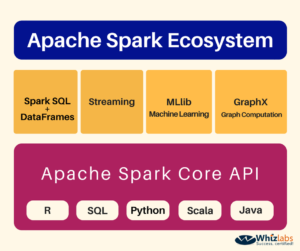
Spark Core
The main execution engine of the Spark platform is known as Spark Core. All the working and functionality of Apache Spark depends on the Spark Core including memory management, task scheduling, fault recovery, and others. It enables in-memory processing and referencing of big data in the external storage systems. Spark Core is responsible to define RDD (Resilient Distributed Dataset) by an API that is the programming abstraction of Spark.
Spark SQL and DataFrames
The Spark SQL is the main component of Spark that works with the structured data and supports structured data processing. Spark SQL comes with a programming abstraction known as DataFrames. Spark SQL performs the query on data through SQL and HQL (Hive Query Language, Apache Hive version of SQL). Spark SQL enables developers to combine SQL queries with manipulated programmatic data that are supported by RDDs in different languages. This integration of SQL with advanced computing medium combines SQL with the complex analytics.
Spark Streaming
This Spark component is responsible for the live stream data processing such as log files created by production web servers. It provides API for the manipulation of data streams, thus makes it easy to learn Apache Spark project. It also helps to switch from one application to another that performs manipulation of real time as well as stored data. This component is also responsible for throughput, scalability, and fault tolerance as that of the Spark Core.
MLlib
MLlib is the in-built library of Spark that contains the functionality of Machine Learning, known as MLlib. It provides various ML algorithms such as clustering, classification, regression, collaborative filtering and supporting functionality. MLlib also contains many low-level machine learning primitives. Spark MLlib is 9 times faster than the Hadoop disk-based version of Apache Mahout.
GraphX
GraphX is the library that enables graph computations. GraphX also provides an API to perform graph computation by allowing users generate directed graph using arbitrary properties of the edge and vertex. Along with the library for manipulating graphs, GraphX provides many operators for the graph computation.
Apache Spark Languages
Apache Spark is written in Scala. So, Scala is the native language used to interact with the Spark Core. Besides, the APIs of Apache Spark has been written in other languages, these are
- Scala
- Java
- Python
- R
So, the languages supported by Apache Spark are Scala, Java, Python, and R. As the framework of Spark is built on Scala, it can offer some great features as compared to other Apache Spark languages. Using Scala with Apache Spark provides you access to the latest features. Python consists of a number of data libraries to perform analysis of data.
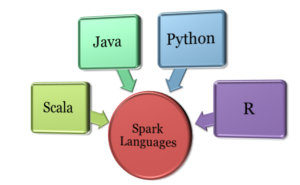
R programming package provides a rich development environment to develop applications that make use of statistical analysis and machine learning algorithms. Although Java does not support REPL the big data professionals with Java background prefer to use Java as Apache Spark language. One can opt any of these four languages for the development, they are comfortable in.
According to a Spark Survey on Apache Spark Languages, 71% of Spark developers are using Scala, 58% are using Python, 31% are using Java, while 18% are using R language.
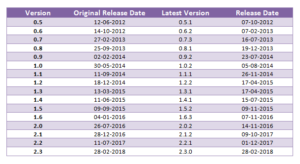
Apache Spark History
Apache Spark introduction cannot actually begin without mentioning the history of Apache Spark. So, let’s state in brief, Spark was first introduced in the year 2009 in UC Berkeley R&D Lab, now AMP Lab by M. Zaharia. And then Spark was open-sourced under BSD License in the year 2010.
In 2013, the Spark project was donated to Apache Software Foundation and the BSD license turned into Apache 2.0. In 2014, Spark became a top-level project of Apache Foundation, known as Apache Spark.
In 2015, with the effort of over 1000 contributors, Apache Spark became one of the most active Apache projects as well as most active open source project of big data. Till date, Apache Spark has undergone many modifications and thus there is a long list of Apache Spark Releases. The following table elaborates different Spark releases with the initial and latest version. Apache Spark version 2.3.0 has recently been released on Feb 28th, 2018 which is the latest version of Apache Spark.
Why You Should Learn Apache Spark
With the generation of big data by businesses, it has become very important to analyze that data to understand business insights. Spark is a revolutionary framework on big data processing land. Enterprises are extensively adopting Spark which in turn is increasing demand for Apache Spark developers. In this section, we will mention why you should learn Apache Spark to boost your development career.
According to O’Reilly Data Science Salary Survey, the salary of developers is a function of their Apache skills. Scala language and Apache Spark skills give a good boost to your existing salary. Apache Spark developers are known as the programmers who receive the highest salary in development. With the increasing demand for Apache Spark developers and their salary level, it is the right time for development professionals to learn Apache Spark and thus help enterprises to perform analysis of data.
Top 5 reasons to learn Apache Spark are –
- To get more access to Big Data
- To grow with the growing Apache Spark Adoption
- To get benefits of existing big data investments
- To fulfill the demands for Spark developers
- To make big money
Let’s discuss these reasons one by one!
1. Learn Apache Spark to Get More Access to Big Data
Apache Spark helps to explore big data and so makes it easier for the companies to solve many big data related problems. Not only data engineers but the data scientists also nowadays are adopting Spark. Apache Spark has become a growing platform for the data scientists. They are showing more interest in Apache Spark as it supports in-memory storage and processing of data. So, if you are the aspirant big data professional and expecting to get more access to big data, you should learn Apache Spark.
Not only Data Engineers but data scientists are also adopting Apache Spark these days. Find out Why You Should Learn Apache Spark to Become a Data Scientist.
2. Learn Apache Spark and Grow with Growing Apache Spark Adoption
The number of companies adopting recent big data technologies like Hadoop and Spark is enhancing continuously. Spark is the big data processing framework that has now become a go-to big data technology. As per the statement of M. Zaharia, the founder of Apache Spark, Spark is an open source big data project that has increased the speed of data processing considerably and drastically. According to the recent Spark adoption survey, Spark is the most active project of Apache foundation, having the highest number of contributors over other open source projects.
There is a huge demand for BI workloads support using Spark SQL and Hadoop, two most popular big data tools. Over 68% of the Spark adopters are using it to provide support to BI workloads. The Spark adoption is increasing day by day, thus bringing more opportunities for the developer with Hadoop and Spark skills.
3. Learn Apache Spark and Get Benefits of Existing Big Data Investments
The important feature of Apache Spark is that it can run over existing clusters. If you are the one who has invested in Hadoop clusters to make use of the Hadoop technology and now wants to switch to Apache Spark. Don’t worry; you don’t need to spend again on the Apache Spark clusters. Yes, you can still adopt Apache Spark and it will run over the existing Hadoop computing cluster.
This compatibility of Apache Spark with the Hadoop cluster make companies hire more Spark developers to integrate Spark well with Hadoop. It will reduce their expenses of spending again on the new computing clusters. It brings more opportunities the Spark developers who already have Hadoop skills, so Hadoop developers can also learn Apache Spark to enhance their skills and get more opportunities.
4. Learn Apache Spark to Fulfill the Demand for Spark Developers
Being an alternative to MapReduce, the adoption of Apache Spark by enterprises is increasing at a rapid rate. Apache Spark needs the expertise in the OOPS concepts, so there is a great demand for developers having knowledge and experience of working with object-oriented programming.
If you want to build a career in big data technology in order to become a big data professional, you should learn Apache Spark. Learning Apache Spark will provide you a number of opportunities to start your big data career. There is a little gap between Apache Spark skills and Apache Spark jobs that can be easily covered by Apache Spark training and gain some real-time experience by working on Spark projects.
5. Learn Apache Spark and Make Big Money
The demand for Apache Spark developers is so high that the organizations are even ready to mold their recruitment procedure and rules, offer flexible work hours, and provide great benefits just to hire a professional having Apache Spark skills. The increasing requirements for Apache Spark developers make enterprises to offer them a great salary. So, if you want to make big money, start learning Apache Spark now.
Apache Spark developers are offered a great salary as compared to the others development professionals. According to O’Reilly, the data experts having experience in Apache Spark are those who earn considerably highest salary. A number of surveys have been made on the salary of IT and big data engineers. The results always show that the data analysts and engineers with big data skills like Hadoop earn more as compared to IT engineers; Spark developers even lead the race. So, it’s not wrong to say that if you want to grow your big data career and desire to make big money, you must learn Apache Spark now.
If you want to become a big data professtional, you should learn Apache Spark. Let’s explore the Importance of Apache Spark in Big Data Industry!
So, growing adoption, big data exploration, big data investments, increasing demand, and the higher salary, are the reasons one should learn Apache Spark. There is no doubt but it’s confirmed that if you learn Apache Spark, you will have a bright and growing career. So, what are you waiting for?? Start learning Apache Spark and become a successful big data professional!
Do You Need Hadoop to Run Spark?
Spark and Hadoop are the most popular big data processing frameworks. Being faster than MapReduce, Apache Spark has taken an edge over the Hadoop in terms of speed. Also, Spark can be used for the processing of different kind of data including real-time whereas Hadoop can only be used for the batch processing.
Although Hadoop and Spark don’t do the same thing but can still work together. Spark is responsible for the faster and real-data processing of data in Hadoop. To achieve maximum benefits, one can run Spark in the distributed mode using HDFS.
But the question is do you always need Hadoop to run Spark? The big data expert has answered this question in this video, let’s check it out!
So, it is not the case that we always need Hadoop to run Spark. But if you want to run Spark with Hadoop, HDFS is the main requirement to run Spark in the distributed mode. There are different modes to run Spark in Hadoop – Standalone Mode, in MapReduce, and over YARN.
Getting Started with Apache Spark
When you have been well-familiar with the Apache Spark by going through Apache Spark introduction, it’s time to get one step ahead to learn Apache Spark. Let’s get some hands-on experience working on Spark. Yes, you got it right! Now, we will first perform the Apache Spark installation and then will run an application on Spark. So, we will begin with the installation of Apache Spark.
Apache Spark Installation
The installation of Apache Spark is not a single step process but we need to perform a series of steps. Note that Java and Scala are the prerequisites to install Spark. Let’s start 7 step Apache Spark installation process.
Step 1: Verify if Java is Installed
The installation of Java is mandatory for Spark installation. The following command will ensure the Java installation on your system.
![]()
The following output will confirm that Java is installed

If you don’t see this response, it means Java is not installed on your system. So, first install Java and then move to the next step.
Step 2: Verify if Scala is Installed
The installation of Scala is required to implement Spark. The following command will ensure the Scala installation on your system.
![]()
The following output will confirm that Scala is installed.
![]()
If you don’t see this response, it means Scala is not installed on your system. So, first install Scala and then move to the next step.
Step 3: Download Scala
Download the Scala, prefer to download the latest version. Currently, we are using version 2.11.6 of Scala. Find the downloaded Scala tar file in downloads.
Step 4: Install Scala
Following are the steps to install Scala.
Extracting Scala Tar File
The first step for the installation is to extract the downloaded Scala tar file. Use the following command –
![]()
Moving Scala Files
The second step of the Scala installation is moving Scala software files to the Scala directory (/usr/local/scala) by the following command –

Setting Path for Scala
Set the path by using the following command –
![]()
Verifying Scala Installation
When you are done with the installation, verify it once with the following command.
![]()
The following output will confirm that Scala is installed.
![]()
Step 5: Download Spark
Download Spark; prefer to download the latest version. Currently, we are using version spark-1.3.1-bin-hadoop2. Find the downloaded Spark tar file in downloads.
Step 6: Install Spark
Following are the steps to install Spark.
Extracting Spark Tar File
The first step for the installation of Spark is to extract the downloaded Spark tar file. Use the following command –
![]()
Moving Spark Files
The second step of the Spark installation is moving Spark software files to the Spark directory (/usr/local/spark) by the following command –
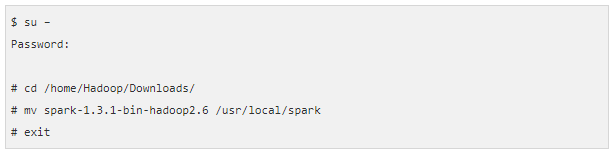
Setting Environment for Spark
Set the environment for Spark by adding the following line to ~/.bashrc file. It adds the location of Spark files to the PATH variable.
![]()
Source the ~/.bashrc file with the following command.
![]()
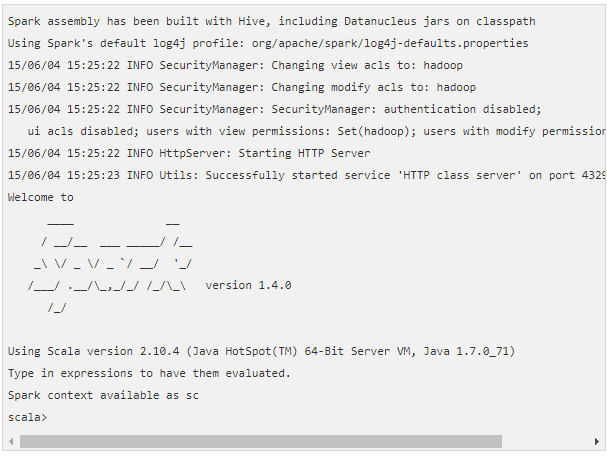
Step 7: Verify Spark Installation
When you are done with the installation, verify it by opening the shell with the following command.
![]()
The following output will confirm that Scala is installed.
Spark Example: Word Count Application
On completing and verifying the installation of Apache Spark, let’s get ahead to learn Apache Spark and run the first application on Spark. Now, we’ll see an example i.e. how to run word count application.
The word count application will count the number of each word in the document. Consider the below-given input text which has been saved as input.txt in the home directory.
Input file: input.txt

Now, following is the procedure to execute the word count application –
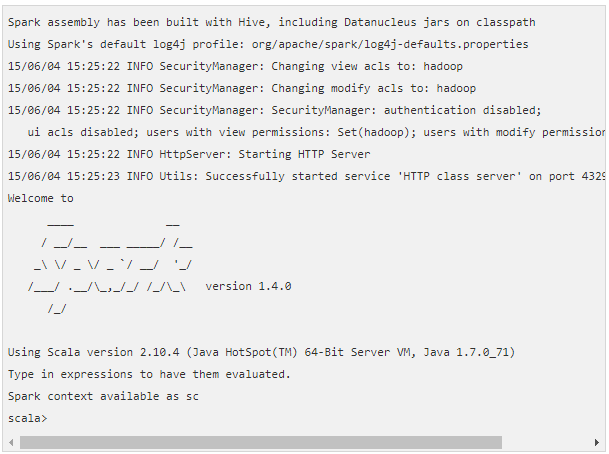
Step 1: Open Spark Shell
Use the following command to open the Spark shell.
![]() On the successful opening of Spark shell, the response of this command will look like –
On the successful opening of Spark shell, the response of this command will look like –
Step 2: Create RDD
Read the input file with Spark Scala API using following command. This command will also create a new RDD with the input file name.
![]()
The string input.txt is given as an argument in textFile method gives the path for the input file.
Step 3: Execute Word count Logic
The following command will execute the logic for word count.

Execution of this command will not give you the output of the application. The reason is that it is just a transformation, not an action. The transformation only tells Spark about what to do with the input.
Step 4: Apply Action
So, now we will apply an action on the transformation. Applying action – store all the transformations with the following command will result in a text file.
![]()
The String argument for the method saveAsTextFile is the path of output folder. So here, output mentioned is the current location.
Step 5: Check Output
Go to the home directory by opening another terminal. To check the output directory, use the following command.

The output shows that there are 2 files in the output directory.
Command to see the output from Part-00000 files
![]()
Output

Command to see the output from Part-00000 files
![]()
Output

Preparing for an Apache Spark interview? Go through these Top 11 Apache Spark Interview Questions and Answers that will help you crack the interview!
Apache Spark Use Cases
So, after getting through Apache Spark introduction and installation, it’s time to have an overview of the Apache Spark use cases. What do these Spark use cases signify? The Apache Spark use cases explain where Apache Spark can be used. Before reading the Apache Spark use cases, let’s understand why companies should use Apache Spark.
So, the businesses should adopt or say have adopted Apache Spark due to its
- Ease of use
- High-performance gains
- Advanced analytics
- Real-time data streaming
- Ease of deployment
Apache Spark helps businesses to understand the types of challenges and problems where we can effectively use Apache Spark. Let’s have a quick sampling of top Apache Spark use cases in different industries!
E-Commerce Industry
In the e-commerce industry, the role of Apache Spark is to process and analyze online transactions. It passes information of real-time online transactions to collaborative filter or streaming cluster algorithm. The result obtained from them is then combined with the other sources of data, such as product reviews, customer comments etc. This combined data can be used to implement recommendations and improve the system according to the latest trends and customer’s requirements with time.
Finance Industry
In the finance industry, Apache Spark is used to analyze and access emails, social profiles, complaint logs, call recordings etc. It helps businesses to get the insights that will make them take right business decisions for risk management, targeted advertisement, and customer satisfaction. It helps banks in the detection of the fraud transactions based on previous logs.
Healthcare Industry
Apache Spark is being used a number of healthcare applications as it helps in enhancement of the healthcare quality. It helps healthcare industry in the analyzing the record of patients to track the patient previous health issues. It is used to avoid re-admittance of the patient by providing home healthcare services which save costs for both the patients and the hospitals. With Apache Spark, the organization of chemicals in the healthcare industry has become a task of few hours only.
Travel Industry
In the travel industry, the travel service providers use Apache Spark to help travelers by advising them to get best-priced hotels and travel. Spark reduces the time of reading and processing reviews on hotels which, in turn, provides faster and better service to the customers. Spark algorithms are faster, and thus can perform a task of weeks in hours only, resulting in better team productivity.
Game Industry
Apache Spark is used in game industry to discover and process patterns from the real-time game events. Also, Spark has the capability of responding instantly to these patterns. This ability of Spark results in high profits in the game business by helping businesses in the targeted advertisement, player withholding, auto-adjustment and much more.
Security Industry
Spark stack plays an important role in the security industry. It is used for the detection and authentication purposes in systems like risk-based authentication system, intrusion detection system, and fraud detection system. Apache Spark provides best results by gathering a large set of archived logs and combines it with the other external data sources. The external data sources may contain information about compromised accounts, data breaches, request/connection i.e. IP location etc.
Apache Spark Books
Good books are the sea of knowledge, so if you want to learn Apache Spark it becomes important to read some good books. It is always said that if you read the books everyone is reading, will make you think like everyone only. To learn Apache Spark efficiently and gain some advanced knowledge, you should read the best Apache Spark books.
Here is the list of top 10 Apache Spark Books –
- Learning Spark: Lightning-Fast Big Data Analysis
- High-Performance Spark: Best Practices for Scaling and Optimizing Apache Spark
- Mastering Apache Spark
- Apache Spark in 24 Hours, Sams Teach Yourself
- Spark Cookbook
- Apache Spark Graph Processing
- Advanced Analytics with Apark: Patterns for learning from Data at Scale
- Spark: The Definitive Guide – Big Data Processing Made Simple
- Spark GraphX in Action
- Big Data Analytics with Spark
These are the best Apache Spark books for those who want to learn Apache Spark. This list of Apache Spark books includes the different type of Apache Spark books. Some of these books are for the beginners and others are for the advanced level professionals.
Want to get an overview of these top Apache Spark books? Read complete blog on 10 Best Apache Spark Books.
Apache Spark Certifications
With the increasing popularity of Apache Spark in the big data industry, the demand for Apache Spark developers is also increasing. It is easy to find a number of resources online for learning Apache Spark. But the companies are looking for the candidates with validated Apache Spark skills i.e. professionals with an Apache Spark Certification.
Apache Spark Certifications will help you to start a big data career by validating your Apache Spark skills and expertise. Getting an Apache Spark Certification will make you stand out of the crowd by demonstrating your skills to the employers and peers. There are many Apache Spark certifications, so it becomes easy to get certified.
Here is the list of top 5 Apache Spark Certifications:
- HDP Certified Apache Spark Developer
- O’Reilly Developer Certification for Apache Spark
- Cloudera Spark and Hadoop Developer
- Databricks Certification for Apache Spark
- MapR Certified Spark Developer
Worth mention, you will have to pay a good amount of fees for these Apache Spark certification exams. So, it becomes important to get fully prepared before applying for the exam. Reading some good Apache Spark books and taking best Apache Spark training will help you pass and Apache Spark certification.
So, choose the right certification, prepare well, and get certified!
Here is the detailed description of top 5 Apache Spark Certifications to Boost your Career.
Apache Spark Training
As the demand for Apache Spark developers is on the rise in the industry, it becomes important to enhance your Apache Spark skills. It is recommended to learn Apache Spark from the industry experts. It boosts your knowledge and also will help you to learn from their experience. A good Apache Spark training helps big data professionals to get hands-on experience as per industry standards. Nowadays, enterprises are looking for Hadoop developers who are skilled in the implementation of Apache Spark best practices.
Whizlabs Apache Spark Training helps you to learn Apache Spark and prepares you for the HDPCD Certification exam. This Apache Spark online training helps you get familiar with the deployment of Apache Spark to develop complex and sophisticated solutions for the enterprises. Whizlabs online training for Apache Spark Certification is one of the best in industry Apache Spark training.
This Hortonworks Apache Spark Certification Online Training helps you to
- validate your Apache Spark expertise
- demonstrate your Apache Spark skills
- remain updated with the latest releases
- solve your queries by industry experts
- get accredited as certified Spark developer
- earn more by giving you a raise in your salary
So, get trained and enhance you Apache Spark skills. In case you have any query related to Whizlabs Apache Spark Certification training, write down in the comment section.
Preparing for HDPCD Certification? Whizlabs Apache Spark Training will help you pass the HDPCD certification exam!
Final Words
In this blog, we have covered a complete definitive and comprehensive guide on Apache Spark. No doubt, it is a must-read guide for those who want to learn Apache and also for those who want to extend their Apache Spark skills. Whether you want to learn Apache Spark components or need to find best Apache Spark certifications, you can find here!
This guide is the one-stop destination where one can find the answer to all the questions based on Apache Spark. Apache Spark has the power to simplify the challenging processing tasks on different types of large datasets. It performs complex analytics with the integration of graph algorithms and machine learning. Spark has brought Big Data processing for everyone. Just check it out!
Have any question about Apache Spark? Feel free to ask here or just leave a comment below. We will be happy to answer!
Wish you the success in your Spark career!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021

Nice information sir it is very easy to learn Spark,History and it’s features
Thank You Kamsala!
If you have any query related to Big Data or Apache Spark, you can ask here. Our Big Data Expert Team will help you 🙂
Hai,
Thank you for sharing information. Here is the information regarding Big Data. Please go through this.
Excellent Sharing. You have done a great job.
It is a great post. Keep sharing such kind of noteworthy information.
Such a very useful article. Very interesting to read this.I would like to thank you for the efforts you had made for writing this awesome article.
Great content usefull for all the candidates of Spark & Scala who want to kick start these career in Spark & Scala field.
I appreciate your work on Spark. It’s such a wonderful read on Spark tutorial. Keep sharing stuffs like this.
the above content is nice information to all aspirants, thank you.
I can recommend a good java for dummies tutorial. Accidentally found this article, went through a couple of lectures. Friendly resource for newbies.
The above content is admirable, Great job, Thanks for sharing.
Awesome article, Thanks for sharing.
Good content, Thanks for sharing.
Interesting writing!
It’s very useful when finding that information.