

The DP-900: Microsoft Azure Data Fundamentals certification is for you, if you are new to Cloud and just getting started with it. You must also be aware of the relational and non-relational data concepts, and various kinds of data workloads such as analytical and transactional.
These free DP-900 Exam Questions and Answers provide you with an overview of the Microsoft Azure Data Fundamentals certification, and introduce you to the various objectives and concepts of the DP-900 exam.
Domain : Describe an analytics workload on Azure
Q1 : What is the role of a pipeline in a data factory in the management of activities?
A. A pipeline allows the management of activities as a set
B. A pipeline allows the management of activities individually
C. A pipeline allows the management of activities individually and as a set both
D. There is no role of pipeline in the management of activities
Correct Answer: A
Explanation
A pipeline itself is a group of activities that performs a task altogether in an Azure data factory. It means pipeline allows the management of activities as a set, not individually. One can not deploy and schedule activities independently, but as a pipeline only.
Option A is correct. A pipeline is a group of activities, grouped as per logic and performs a task altogether in a data factory. The pipeline allows the management of activities as a set.
Option B is incorrect. A pipeline is a group of activities and does not allow the management of activities individually.
Option C is incorrect. A pipeline allows the management of activities as a set only, not individually.
Option D is incorrect. A pipeline allows the management of activities as a set.
Reference: To know more about the Pipeline and Activities in Azure Data Factory, refer to the documentation below from Azure: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipelines-activities
Domain : Describe core data concepts
Q2 : Read the statement – “In relational databases, all the values in a column will have the same data type.”
A. Yes
B. No
Correct Answer: A
Explanation
A relational database stores data and provides access to data points that are related to each other. A relational database follows the basic relational model that is a simple and straightforward method of storing data in tables. Each row of the table in a relational database represents a record with a unique id i.e. key. Each column of the table holds an attribute of the data, and each record represents the value for each attribute.
For example, a table STUDENT_RECORD represents the record of students in a class and the attributes of columns are – Student_Id, Student_Name, Student_Branch, and Student_Marks. We need to define the data type of each attribute in the beginning at the time of the creation of the table. Here, if we set Student_Id as a number, all the values in the column Student_Id will contain numbers only. And if we set it as alphanumeric, all the values in the column Student_Id will contain both alphabets and numbers.
| Student_Id | Student_Name | Student_Class | Student_Marks |
| 1001 | John | CS | 903 |
| 1002 | Koe | EC | 678 |
| 1003 | Faiz | IT | 782 |
| 1004 | Kally | ME | 876 |
So, Option A is correct.
Reference: To know more about the characteristics of Relational Databases, click the Link below: https://docs.rackspace.com/support/how-to/properties-of-rdbmss-and-nosql-databases/
Domain : Describe how to work with relational data on Azure
Q3 : Which of the following is not a feature of the Azure Database for MariaDB?
A. High availability and predictable performance
B. Provides read and write mysql system database
C. Autoscaling, auto backups, and point-in-time-restore
D. Secure protection of data with enterprise-grade security and compliance
Correct Answer: B
Explanation
Azure Database for MariaDB is a relational database service with the following features:
- Build-in high availability without any extra cost
- Autoscaling whenever required, within seconds
- Enterprise-level security and compliance
- Predictable performance with the pay-as-you-go model
- Auto backups and point-in-time-restore for up to 35 days
- Protection and security of confidential data in motion as well as at rest
Azure Database for MariaDB has a limitation that the mysql system database in Azure Database for MariaDB is a read-only as it supports a number of PaaS functionality. You can’t make any changes to the mysql system database.
Option A is incorrect. Azure Database for MariaDB delivers build-in high availability without any additional cost and predictable performance with a pay-as-you-go pricing model.
Option B is correct. The mysql system database in Azure Database for MariaDB is read-only as it supports a number of PaaS functionality. You can’t make any changes to the mysql system database.
Option C is incorrect. Azure Database for MariaDB delivers autoscaling in seconds when required, auto backups, and power-in-time-restore.
Option D is incorrect. Azure Database for MariaDB delivers secured protection of sensitive data in motion as well as at rest, and also offer enterprise-level compliance and security.
References: To know more about the Azure Database for MariaDB, refer to the links below: https://docs.microsoft.com/en-us/azure/mariadb/overview, https://docs.microsoft.com/en-us/azure/mariadb/concepts-limits
Domain : Describe how to work with non-relational data on Azure
Q4 : Which of the following is a unique identifier for the document, often hashed for the even distribution of data, and helps in the retrieval of data from the document in the document data store?
A. Primary Key
B. Hash Key
C. Secondary Key
D. Document Key
Correct Answer: D
Explanation
A document data store manages the object data values and named string fields in documents. The document key is a unique identifier for the document, often hashed for the even distribution of data. It helps in the retrieval of data from the document. In some document databases, the document key is created automatically while in others, you have to set an attribute of the document and use it as the document key.
Option A is incorrect. There is no primary key in the document of a document data store. The data is retrieved with the help of a unique identifier, document key.
Option B is incorrect. There is no hash key in the document of a document data store. The data is retrieved with the help of a unique identifier, document key.
Option C is incorrect. There is no secondary key in the document of a document data store. The data is retrieved with the help of a unique identifier, document key.
Option D is correct. The document key is a unique identifier for the document, often hashed for the even distribution of data. It helps in the retrieval of data from the document.
Reference: To know more about the Document Data Store, refer to the link below: https://docs.microsoft.com/en-us/azure/architecture/data-guide/big-data/non-relational-data
Domain : Describe how to work with non-relational data on Azure
Q5 : You are working as a Data Associate in an organization. Your client has accomplished the tasks with his Azure CosmoDB account and wants to delete it.
He does not know about the steps to be followed for it. You need to help him to follow the right sequence of steps to clean up his Azure Cosmos DB account. How will you arrange the following steps in the right sequence?
- Select the created resource group for the quickstart.
- Search and Select Resource Groups in the Azure Portal Search Bar.
- Enter the name of the resource group you want to delete and select Delete.
- Select Delete Resource Group on the Resource Group Overview Page.
A. 2143
B. 1342
C. 4231
D. 1234
Correct Answer: A
Explanation
You can delete the Azure resources when you are done with them. In the same manner, when you are done with the Azure Cosmo DB, you can delete your Azure Cosmo DB account. The steps to delete an Azure Cosmo DB account are as below:
- Search and Select Resource Groups in the Azure Portal Search Bar.
- Select the created resource group.

- Select Delete Resource Group on the Resource Group Overview Page.

- Enter the name of the resource group you want to delete and select Delete.


Option A is correct. Search and Select Resource Groups in the Azure Portal Search Bar, Select the created resource group, Select Delete Resource Group on the Resource Group Overview Page, Enter the name of the resource group you want to delete, and select Delete is the correct sequence of steps to delete an Azure Cosmo DB account.
Option B is incorrect. 1342 doesn’t form the correct sequence of steps for the deletion of an Azure Cosmo DB account.
Option C is incorrect. 4321 doesn’t form the correct sequence of steps for the deletion of an Azure Cosmo DB account.
Option D is incorrect. 1234 doesn’t form the correct sequence of steps for the deletion of an Azure Cosmo DB account.
Reference: To know more about Cosmo DB Resources, refer to the link below: https://docs.microsoft.com/en-us/azure/cosmos-db/create-cosmosdb-resources-portal
Domain : Describe core data concepts
Q6 : The common tasks and responsibilities of a data analyst include,
A. Finding hidden patterns using data
B. Focuses only on the available data
C. Restricts access to data in the company
D. Arrives at conclusions with one-step analysis
Correct Answer: A
Explanation
A data analyst uses various techniques and tools for collating data from different sources to visualize the data in an understandable and relevant format. Data analysts use the visualization tools for the transformation of data into graphical formats that can help in finding useful patterns in the data.
Option A is CORRECT. Data analysts are primarily responsible for using visualization tools, and their skills in using data can help them in the transformation of data into understandable formats according to business requirements.
Option B is incorrect. Data analysts combine the resultant sets of data from different sources, and in some cases; they rely on live operational data.
Option C is incorrect. Data analysts have to share their data visualization reports with employees in other departments while also addressing the responsibility of integrating data from many sources for better insights.
Option D is incorrect. Data analysts don’t just observe the data from different sources arranged in a specific format to deliver insights. They have to refine the data by removing redundancies and errors in raw data from different sources and transform it, followed by improvements before visualizing them into desired formats.
Reference: To know more about the tasks and responsibilities of data analysts refer to the following Azure documentation: https://docs.microsoft.com/en-us/learn/modules/explore-roles-responsibilities-world-of-data/5-review-tasks-tools-for-data-visualization-reporting
Domain : Describe how to work with non-relational data on Azure
Q7 : Which of the following use case scenarios aptly relates to the use of non-relational data offerings on Azure?
A. Inventory management systems
B. Database migration systems
C. Accounting systems
D. Transaction management systems
Correct Answer: B
Explanation
Non-relational data offerings or NoSQL databases are ideally suited for managing large, unrelated, and rapidly fluctuating data, thereby serving as the fitting option for database migration use cases.
Option A is incorrect. Inventory management systems require a specific schema alongside the need for continuous synchronization between the database and the system.
Option B is CORRECT. Database migration systems can leverage non-relational data offerings on Azure for coping with the massive volumes of unrelated, rapidly fluctuating, and indeterminate data.
Option C is incorrect. Accounting systems are generally associated with legacy systems that are fit for relational structures, thereby downplaying the significance of non-relational data offerings.
Option D is incorrect. Transaction management systems often deal with complex querying requirements and the needs for multi-row transactions. Therefore, non-relational data offerings on Azure might not be a fitting option.
Reference: To know more about the suitable use cases for non-relational data offerings on Azure, explore the following Azure documentation: https://azure.microsoft.com/en-in/overview/nosql-database/
Domain : Describe an analytics workload on Azure
Q8 : Which of the following benefits don’t relate closely to interactive reports in Power BI?
A. AI-powered augmented analytics
B. Advanced analytics with the knowledge of MS Office
C. Easier preparation and modeling of data
D. Ideal for enterprise and medium companies that have human capital for supporting data analytics
Correct Answer: D
Explanation
The tool that relates closely to the benefit of being the ideal tool for enterprise and medium companies with the human capital for supporting data analytics operations in Tableau. It provides easier creation of dashboards in comparison to Power BI. Therefore, the answer does not relate closely to the benefits of interactive reports with Power BI.
Option A is incorrect. AI-powered augmented analytics is an evident advantage with the interactive reports in Power BI with a focus on new AI capabilities evident with Azure and now in Power BI.
Option B is incorrect. Advanced analytics with fluency in MS Office is critical functionality evident with interactive reports in Power BI. It can enable diving deeper into data for discovering patterns that can foster actionable insights. Users can get full control over their data analytics model with Power BI through the comprehensive DAX formula language.
Option C is incorrect. Power BI allows easier and faster preparation and modeling of data through the facility of productive data modeling tools. The self-service Power Query experience with Power BI directly benefits interactive reports, unlike other tools.
Option D is CORRECT. The support of human capital is superfluous in the case of Power BI with the facility of sophisticated functionalities to leverage interactive reports for ensuring desired data analytics activities.
Reference: If you want to know more about the functionalities of data visualization in Microsoft Power BI, then go through the following resource: https://powerbi.microsoft.com/en-us/desktop/
Domain : Describe how to work with relational data on Azure
Q9 : How many virtual machine images are maintained by Azure for each supported operating system (OS), version, and edition combination?
A. One
B. Two
C. Three
D. Unlimited
Correct Answer: A
Explanation
Azure maintains 1 virtual machine (VM) image for each supported operating system (OS), version, and edition combination. The images are refreshed over time, and the older ones are removed.
Option A is CORRECT. Azure maintains 1 virtual machine (VM) image for each supported operating system (OS), version, and edition combination. The images are refreshed over time, and the older ones are removed.
Option B is incorrect as only 1 virtual machine image is maintained by Azure for each supported operating system (OS), version, and edition combination.
Option C is incorrect as only 1 virtual machine image is maintained by Azure for each supported operating system (OS), version, and edition combination.
Option D is incorrect as only 1 virtual machine image is maintained by Azure for each supported operating system (OS), version, and edition combination.
Reference: To know more, refer to the documentation below from Azure: https://docs.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/sql-server-on-azure-vm-iaas-what-is-overview
Domain : Describe how to work with non-relational data on Azure
Q10 : You need to store semi-structured data in the database as key-value pairs where the key is unique and columns can vary and each row holds the whole data for a logical entity. Which storage option should you choose?
A. Azure Table Storage
B. Azure File Storage
C. Azure Blob Storage
D. None
Correct Answer: A
Explanation
Azure Table storage stores a large amount of structured NoSQL data in the cloud, providing a key-value store with a schemaless design. A table can be created using an Azure storage account. In the table, rows indicate the items, and columns represent the various fields and values. The following diagram depicts the components of table storage.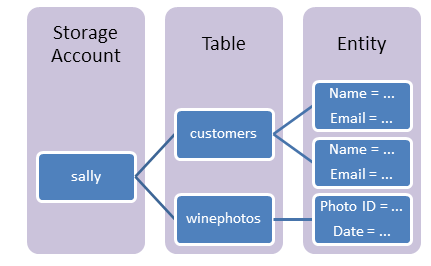
Option A is CORRECT as Azure table storage follows the key/value model to store the data.
Option B is incorrect. Azure Blob storage is an object storage solution that allows storing huge amounts of unstructured data in the cloud. It does not store the data as key-value pairs.
Option C is incorrect. Azure File Storage is a shared storage service that supports creating files shares in the cloud, and accessing these file shares from anywhere and at any time with an internet connection.
References: To know more about the different type of storage options, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/azure/storage/tables/table-storage-overview, https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-overview, https://docs.microsoft.com/en-us/azure/storage/files/storage-files-introduction
Domain : Describe an analytics workload on Azure
Q11 : Which of the following components of an Azure Data Factory is triggered to run data ingestion tasks?
A. Pipeline
B. Datasets
C. Linked Services
D. CSV file
Correct Answer: A
Explanation
Azure Data Factory consists of various key components like Pipelines, Activities, Datasets, Linked services, Data Flows, and Integration Runtimes. All these components collectively provide a platform that allows you to compose data-driven workflows with steps to move and transform data. Out of these components, Pipeline is the component that is triggered to run data ingestion tasks.
A data factory may consist of one or more pipelines. A pipeline represents a logical grouping of tasks/activities and these activities collectively perform a task. For example, a pipeline may consist of a group of activities that ingest data from an Azure blob and then run a Hive query on an HDInsight cluster for data partitioning.
Option A is correct. A pipeline is the component of the Azure data factory that is triggered to run activities for ingesting data.
Option B is incorrect. Datasets in the Azure data factory is not any task that can be run. Instead, a dataset represents the data structures within the data stores, which is a reference to the data that is to be used as inputs or outputs in the activities.
Option C is incorrect. Linked services in the Azure data factory specify the connection parameters to connect to the Azure service. It is not any task that could be run.
Option D is incorrect. Although a CSV file can be exported or imported, an orchestration framework is necessary to run it.
Reference: To know more about Azure Data Factory, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/azure/data-factory/introduction
Domain : Describe core data concepts
Q12 : Which of the following is/are the example(s) of unstructured data?
A. A student table with columns studentname, student_id, and Registration
B. Audio and video files and binary data files
C. A table within SQL Server database
D. A student table with rows studentname, student_id, and Registration
E. JSON Document
Correct Answer: B
Explanation
The data or dataset having a predefined structure is the structured data. Structured data is typically tabular data that is represented by rows and columns in a database. Databases that store the data in this form are known as Relational Databases. On the other hand, data not having any specific structure is known as unstructured data. Among the given options, Audio and Video files and binary files are the ones having no specific structure and therefore is an example of unstructured data. Besides structured and unstructured data, there is also Semi-structured data that doesn’t exist in a relational database but still has some structure associated with it. Documents in JavaScript Object Notation (JSON) format are examples of semi-structured data.
Option A is incorrect. A student table with a defined set of columns is an example of structured data.
Option B is correct. As audio and video files and binary data files might not have a specific structure, they are unstructured data.
Option C is incorrect. A table within SQL Server database is an example of structured data as it has predefined columns and structure.
Option D is incorrect. A student table with a defined set of rows is an example of structured data.
Option E is incorrect. Documents in JavaScript Object Notation (JSON) format are examples of semi-structured data.
Reference: To know more, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/explore-core-data-concepts/2-identify-need-data-solutions
Domain : Describe how to work with relational data on Azure
Q13 : Complete the statement.
In Azure SQL databases, transparent data encryption encrypts the ……………..
A. Database to protect the data in the motion
B. Server to protect the data in the motion
C. Database to protect the data at rest
D. Server to protect the data at rest
Correct Answer: C
Explanation
Transparent Data Encryption (TDE) protects Azure SQL Database, Azure Synapse Analytics, and Azure SQL Managed Instance against malicious offline activities by encrypting the data at rest. Here, the database, associated backups, and transaction log files at rest can be encrypted and decrypted in real-time without the need for any change in the application.
Option A is incorrect. Transparent Data Encryption (TDE) protects the data at rest; not in the motion. To protect the data in the motion, transport layer security is used.
Option B is incorrect. Transparent Data Encryption (TDE) protects the data at rest; not in the motion. To protect the data in the motion, transport layer security is used.
Option C is CORRECT. Transparent Data Encryption (TDE) encrypts the database to protects the data at rest.
Option D is incorrect. Transparent Data Encryption (TDE) encrypts the database, not the server, to protects the data at rest.
Reference: To know more about theTransparent Data Encryption (TDE), refer to the documentation below from Azure: https://docs.microsoft.com/en-us/azure/azure-sql/database/transparent-data-encryption-tde-overview?tabs=azure-portal
Domain : Describe how to work with relational data on Azure
Q14 : In the following SQL query:
INSERT INTO Students ( StudentName , StudentID , Marks , Address) VALUES (‘Ram’ , 1501, 87, ‘Delhi’) ;
What are the Students and Marks respectively?
A. Column and table
B. Index and Column
C. Table and Primary key
D. Table and Column
Correct Answer: D
Explanation
INSERT is a command in SQL with syntax
INSERT INTO table name ( column 1, column 2, column 3, ……..) VALUES (Value 1, Value 2 , Value 3, ………..). Therefore, in the above-given query, Students is a table and Marks is a column of the Students table.
Option A is incorrect as according to the syntax for INSERT, Students is the table and Marks is the column.
Option B is incorrect as Students is a table, not an index. INSERT command is never applied on the indexes.
Option C is incorrect as in the given SQL query, Marks is a simple column as it is not explicitly defined as the primary key.
Option D is CORRECT as according to the syntax of INSERT command, Students is the table and Marks is the column.
Reference: To know more, refer to the documentation below from Azure: https://docs.microsoft.com/en-us/learn/modules/query-relational-data/2-introduction-to-sql
Domain : Describe how to work with relational data on Azure
Q15 : There is a Student Management System with the following “Student” table:
| Student_Name | Registration_No | Address |
| Rahul | 10301 | Delhi |
| Ram | 10302 | Agra |
| Shyam | 10303 | Noida |
Now, there is a need to change the name of column “Registration_No” to “Roll_No”. Which statement you would use?
A. UPDATE
B. ALTER
C. CREATE
D. INSERT
Correct Answer: B
Explanation
For functions like changing the column name, size or datatype, the Alter command is used.
Syntax for ALTER:
ALTER TABLE Tablename
Rename Column OldColumnName TO NewColumnName
Option A is incorrect as UPDATE statement is used to modify the data; not the name of the column.
Option B is CORRECT as ALTER statement is used to change the structure of the table. As here we need to rename the column, the following statement can be used;
ALTER TABLE Student
RENAME COLUMN Registration_No TO Roll_no ;
Option C is incorrect as the CREATE statement is used to create the table, not to rename the column.
Option D is incorrect as INSERT is used to insert the data into the table.
Reference: To know more, refer to the documentation below from Azure: https://docs.microsoft.com/en-us/learn/modules/query-relational-data/2-introduction-to-sql
Domain : Describe how to work with relational data on Azure
Q16 : Which of the following Azure tools describes the service(s) to be deployed in JSON (JavaScript Object Notation) format?
A. Azure Portal
B. Azure command-line interface (CLI)
C. Azure Powershell
D. Azure Resource Manager templates
Correct Answer: D
Explanation
An Azure Resource Manager template describes the service(s) to be deployed in a text file, in JSON format. The below is an example template that can be utilized to provision an instance of Azure SQL Database.
Option A is incorrect. The Azure portal shows the sequence of service-specific pages that prompt you for the settings needed and confirms these settings before the service is actually provisioned.
Option B is incorrect. CLI offers a set of commands that can be run from the operating system (OS) command prompt or the Cloud Shell in the Azure portal. These commands can be used for creating and managing the Azure resources.
Option C is incorrect. Azure PowerShell provides a set of commands that can be used for scripting and automating the administrative tasks. Azure offers a series of commandlets, that are Azure-specific commands, that can be utilized in PowerShell for creating and managing the Azure resources.
Option D is CORRECT. An Azure Resource Manager template describes the service(s) to be deployed in a text file, in JSON format.
Reference: To know more about the relation data services, refer to the documentation below from Azure: https://docs.microsoft.com/en-us/learn/modules/explore-provision-deploy-relational-database-offerings-azure/2-describe-provision-relational-data-services
Domain : Describe how to work with non-relational data on Azure
Q17 : Which of the following API of Azure Cosmo Database provides a graph-based view on database?
A. MongoDB API
B. Cassandra AP
C. Gremlin
D. Table API
Correct Answer: C
Explanation
Cosmo DB supports 5 APIs: Core (SQL) API, MongoDB API, Cassandra API, Table API, and Gremlin API.
Core (SQL) API is the default API that provides a view of that data that resembles a traditional NoSQL document store. SQL like language is used to query the hierarchical JSON documents with a SQL-like language.
MongoDB is a document database that has its own programmatic interface. Therefore, the data structure associated with MangoDB is JSON documents. Cassandra is a column family database management system that supports querying data through Cassandra Query Language (CQL).
Gremlin provides a graph-based view of the database. It means that the data is either a vertex (an individual item in the database), or an edge (a relationship between the database items).
Option A is incorrect. MongoDB is a document database that has its own programmatic interface. Therefore, data structures associated with MangoDB are JSON documents.
Option B is incorrect. Cassandra is a column family database management system that supports querying data through Cassandra Query Language (CQL).
Option C is CORRECT. Gremlin provides a graph-based view of the database. It means that the data is either a vertex (an individual item in the database), or an edge (a relationship between the database items ).
Option D is incorrect. Table API allows using the Azure Table Storage API to store and retrieve the documents. The associated data structure with Table API is key-value.
Reference: To know more about the API for Azure Cosmos Database, please refer to the Azure documentation: https://docs.microsoft.com/en-us/learn/modules/choose-api-for-cosmos-db/2-identify-the-technology-options
Domain : Describe an analytics workload on Azure
Q18 : Consider the statements below:
S1: Bring data into Power BI Desktop, and create a report
S2: Publish to the Power BI service, where you can create new visualizations or build dashboards
S3: Share dashboards with others, especially people who are on the go
S4: View and interact with shared dashboards and reports in Power BI Mobile apps.
Which of the following sequences of the above statements represents the common flow of activities in Power BI?
A. S1-S2-S4-S3
B. S2-S1-S3-S4
C. S1-S2-S3-S4
D. S2-S3-S1-S4
Correct Answer: C
Explanation
The activities and analyses in Power BI generally follow a common flow as given below:
- Bring data into Power BI Desktop, and create a report.
- Publish to the Power BI service, where you can create new visualizations or build dashboards.
- Share dashboards with others, especially people who are on the go.
- View and interact with shared dashboards and reports in Power BI Mobile apps.
So, the sequence S1-S2-S3-S4 is the right sequence.
Option A is incorrect as in normal flow, Share dashboards with others, especially people who are on the go comes before View and interact with shared dashboards and reports in Power BI Mobile apps.
Option B is incorrect as it is Bring data into Power BI Desktop, and create a report, not Publish to the Power BI service, where you can create new visualizations or build dashboards, that is the first activity in the normal flow.
Option C is correct. Bring data into Power BI Desktop, and create a report, Publish to the Power BI service, where you can create new visualizations or build dashboards, Share dashboards with others, especially people who are on the go, and finally View and interact with shared dashboards and reports in Power BI Mobile apps is the common flow in Power BI.
Option D is incorrect as Bring data into Power BI Desktop, and create a report is the first activity in the normal flow. The right sequence of common flow is – Bring data into Power BI Desktop, and create a report, Publish to the Power BI service, where you can create new visualizations or build dashboards, Share dashboards with others, especially people who are on the go and finally View and interact with shared dashboards and reports in Power BI Mobile apps is the common flow in Power BI.
Reference: To know more about Power BI, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/get-started-with-power-bi/2-using-power-bi
Domain : Describe an analytics workload on Azure
Q19 : You have retrieved data formatted in a different format from multiple sources. Now, you need to transform the data into a single uniform format. Which of the following data services would you use?
A. Azure Data Factory
B. Azure Data Lake Storage
C. Azure Databricks
D. None of These
Correct Answer: A
Explanation
Azure Data Factory is a data integration service that allows users to retrieve data from one or multiple data sources, and convert it into the desired format. The various data sources might have different data representation and have a noise that needs to be filtered out. Azure Data Factory allows to extract only the interesting/required data, and discard the rest. Even if the interesting data is not presented in the required format for processing by other services, it can be transformed into the desired format.
Option A is correct. Azure Data Factory allows transforming the data from multiple sources in the desired uniform format.
Option B is incorrect. Azure Data Lake Storage is a secure cloud platform that offers cost-effective and scalable storage for big data analytics. In an Azure Data Services data warehouse solution, data is generally loaded into Azure Data Lake Storage before it is processed into a structure that supports efficient analysis in Azure Synapse Analytics.
Option C is incorrect. Azure Databricks is an Apache Spark environment that runs on Azure to offer big data processing, streaming, and machine learning.
Option D is incorrect. Azure Data Factory allows users to transform the data from multiple sources in the desired uniform format.
Reference: To know more about Azure Data Factory, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/examine-components-of-modern-data-warehouse/3-explore-azure-data-services-warehousing
Domain : Describe an analytics workload on Azure
Q20 : Select the right sequence for implementing the Extract, Load, and Transform (ELT) process.
A. Extract the source data into text files, Prepare the data for loading, Load the data into staging tables with PolyBase or the COPY command, Land the data into Azure Blob storage or Azure Data Lake Store, Transform the data, Insert the data into production tables
B. Extract the source data into text files, Land the data into Azure Data Lake Store or Azure Blob storage, Prepare the data for loading, Load the data into staging tables with PolyBase or the COPY command, Transform the data, Insert the data into production tables
C. Extract the source data into text files, Land the data into Azure Blob storage or Azure Data Lake Store, Prepare the data for loading, Load the data into staging tables with PolyBase or the COPY command, Insert the data into production tables, Transform the data
D. Extract the source data into text files, Prepare the data for loading, Load the data into staging tables with PolyBase or the COPY command, Land the data into Azure Blob storage or Azure Data Lake Store, Insert the data into production tables, Transform the data
Correct Answer: B
Explanation
ELT is a process that extracts the data from a source system, loads it into a SQL pool, and then transforms it.
The basic steps for implementing the Extract, Load, and Transform (ELT) process are:
- Extract the source data into text files.
- Land the data into Azure Data Lake Store or Azure Blob storage.
- Prepare the data for loading.
- Load the data into staging tables through PolyBase or the COPY command.
- Transform the data.
- Insert the data into the production tables.
Reference: To know more about the implementation of the Extract, Load, and Transform (ELT) process, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-elt-data-loading
Domain : Describe an analytics workload on Azure
Q21 : In Data Lake Analytics, which of the following languages is used to define a job that contains queries to transform data and extract insights?
A. SQL
B. C#
C. U-SQL
D. PL/SQL
Correct Answer: C
Explanation
Data Lake Analytics provides a framework and collection of tools that is used to analyze data stored in Microsoft Azure Data Lake Store and other repositories. You write the jobs consisting of queries to transform the data and get insights. The language that is used to write these jobs is known as “U-SQL”. U-SQL is a hybrid language that has the features of both languages SQL and C#, and offers the procedural and declarative capabilities that can be used for data processing.
Option A is incorrect. It is U-SQL, not SQL, that is used to define the mentioned jobs in data lake analytics.
Option B is incorrect. It is U-SQL, not #C, that is used to define the mentioned jobs in data lake analytics.
Option C is correct. U-SQL is the language that is used to define a job that contains queries to transform data and extract insights into data lake analytics.
Option D is incorrect. It is U-SQL, not PL/SQL, that is used to define the mentioned jobs in data lake analytics.
Reference: To know more, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/explore-data-storage-processing-azure/2-describe-azure
Domain : Describe core data concepts
Q22 : Which of the following are the characteristics of a relational database?
A. All data needs to be stored as integers
B. The rows in a table consist of one or more columns that represent the properties of the entity
C. The different rows in the same table might have different columns
D. A tuple in a relation represents a single entity
D. A relational database has a flexible schema
Correct Answers: B and D
Explanation
In a relational database, the entities are modeled as the tables. Entities are the things for which the information needs to be stored or known. For example, in an organization, you might be interested in storing the information regarding employees, department and project, etc. All these employees, departments and projects are known as entity types, and tables are created for those. Each row in a table represents one instance of that entity type. For example, in the EMPLOYEE table, each row represents the details of one employee. Below is a snapshot of the database with table EMPLOYEE, DEPARTMENT, and PROJECT.")
")
")
Option A is incorrect. All the data don’t need to be stored as integers. Data can be stored as any data type integer, real number, string, Date, etc.
Option B is correct. In a relational database, the rows in a table consist of one or more columns that represent the properties of the entity.
Option C is incorrect. In a table, all the rows need to have the same columns although the values for different rows might be the same or different depending upon the attribute.
Option D is correct. A Row or Tuple in a table represents the one instance or entity of a particular entity type.
Option E is incorrect. Schemaless design in the property of the non-relational database, not the relational database.
Reference: To know more about the characteristics of a Relational Database, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/describe-concepts-of-relational-data/2-explore-characteristics
Domain : Describe core data concepts
Q23 : …………….. is the process of transforming and mapping the raw data into a more useful format for analysis?
A. Data Cleaning
B. Data Ingestion
C. Wrangling
D. Data Analysis
E. Data Modeling
Correct Answer: C
Explanation
Wrangling is the process of transforming and mapping raw data into a more useful format for analysis. It might include writing code for capturing, filtering, cleaning, combining, and aggregating data from multiple sources.
Option A is incorrect. Data cleaning is a generalized term that comprises a wide range of actions like removing or deleting anomalies and applying filters and transformations that would be too time-taking to run during the ingestion phase.
Option B is incorrect. Data ingestion is the process that obtains and imports the data for immediate use or storage in a database.
Option C is correct. Wrangling is the process of transforming and mapping raw data into a more useful format for analysis.
Option D is incorrect. Data analysis is the process of inspecting, cleansing, transforming, and modeling data to get useful information, supporting decision-making, and informing conclusions.
Option E is incorrect. Data modeling is a process of creating a conceptual representation of the data objects, in association with other data objects, and the rules between them.
Reference: To know more about wrangling, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/explore-concepts-of-data-analytics/2-describe-data-ingestion-process
Domain : Describe core data concepts
Q24 : Which of the following are the roles and responsibilities of a database administrator?
A. To install and upgrade the database server and application tools
B. To enroll the users and maintain system security
C. To develop, construct, test, and maintain the databases and data structures
D. To monitor and optimize the performance of the database
E. To Prepare the data for prescriptive and predictive modeling
Correct Answers: A, B and D
Explanation
Database Administrator is tasked to manage and organize the databases. The main job of a database administrator is to ensure that data is available and protected from loss, theft, and corruption and is easily accessible whenever needed. The following figure shows the common roles and responsibilities of a database administrator:
- To install and upgrade the database server and application tools.
- To allocate system storage and plan storage needs for the database system.
- To modify the database structure, as necessary, from information provided by application developers.
- To enroll the users and maintain system security.
- To ensure compliance with the database vendor license agreement.
- To control and monitor user access to the database.
- To monitor and optimize the performance of the database.
- To do Planning for backup and recovery of database information.
- To maintain archived data.
- To ensure Backing up and restoring databases.
- To contact database vendors for technical support.
- To generate various reports from the database using appropriate queries as per needs.
- To manage and monitor data replication.
Option A is correct. To install and upgrade the database server and application tools is one of the common roles and responsibilities of a database administrator.
Option B is correct. To enroll the users and maintain system security is one of the common roles and responsibilities of a database administrator.
Option C is incorrect. To develop, construct, test, and maintain the databases and data structures is the responsibility of the data engineer, not the data administrator.
Option D is correct. To monitor and optimize the performance of the database is one of the common roles and responsibilities of a database administrator.
Option E is incorrect. To Prepare the data for prescriptive and predictive modeling is the responsibility of the data engineer, not the data administrator
References: To know more about the roles and responsibilities of a Data Administrator, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/learn/modules/explore-roles-responsibilities-world-of-data/3-review-tasks-tools-for-database-administration, https://docs.microsoft.com/en-us/learn/modules/explore-roles-responsibilities-world-of-data/4-review-tasks-tools-for-data-engineering
Domain : Describe how to work with non-relational data on Azure
Q25 : Which of the following statements is false about Azure Cosmos DB?
A. It supports providing or restricting access to the Cosmos account, database, container, and offers (throughput) using Access control (IAM) in the Azure portal
B. It supports monitoring the account for normal and abnormal activities
C. All connections to Azure Cosmos DB support HTTPS
D. The data once deleted can’t be recovered in any way
Correct Answer: D
Explanation
Azure Cosmos DB secures the database through
- Network security and firewall settings
- User authentication and fine-grained user controls
- Replicating data globally for regional failures
- Ability to failover from one data center to another
- Local data replication within a data center
- Automatic data backups
- restoring the deleted data from backups
- isolating and protecting the sensitive data
- Responding to attacks
- Monitoring for attacks
- Geo-fencing data to adhere to data governance restrictions
- Physical protection of servers in protected data centers
- Certifications
Option A is incorrect. In Azure Cosmos DB, you can provide or restrict access to the Cosmos account, container, database, and offers (throughput) through Access control (IAM) in the Azure portal. IAM offers role-based access control and integrates with Active Directory. You can utilize built-in or even the custom roles for groups as well as individuals.
Option B is incorrect. Azure Cosmos DB allows monitoring the account for normal and abnormal activities using audit logging and activity logs. You can see what operations have been carried out on your resources, who started the operation, when the operation happened and the status of the operation, etc.
Option C is incorrect. In Azure Cosmos DB, all connections to Azure Cosmos DB support HTTPS.
Option D is correct. It is false that the data once deleted can’t be recovered in Azure Cosmos DB. It supports recovering data you might have accidentally deleted up to ~30 days after the event through automated online backups.
Reference: To know more about Azure Cosmos DB, please refer to the Azure documentation below: https://docs.microsoft.com/en-us/azure/cosmos-db/database-security
Summary
Hope you found these exam questions on the DP-900 certification useful and were quick to answer. If you spend more time on your learning, then you can face the exam with full confidence. For more such practice test questions, refer to our Whizlabs official webpage, and move closer towards passing the DP-900 certification in the first attempt.
- Top 25 DevSecOps Interview Question and Answers for 2024 - March 1, 2023
- How to prepare for VMware Certified Technical Associate [VCTA-DCV] Certification? - February 14, 2023
- Top 20 Cloud Influencers in 2024 - January 31, 2023
- 25 Free Question on SC-100: Microsoft Cybersecurity Architect - January 27, 2023
- Preparation Guide on MS-101: Microsoft 365 Mobility and Security - December 26, 2022
- Exam tips to prepare for Certified Kubernetes Administrator: CKA Exam - November 24, 2022
- Why do you need to upskill your teams with the Azure AI fundamentals? - October 11, 2022
- The best employee retention strategy for IT industries – UPSKILLING - September 26, 2022
Hi I have read a lot from this blog thank you for sharing this information. We provide all the essential topics in Data structure and algorithms system design program Full stack development like, Data science, Python, AI and Machine Learning, Tableau, etc. for more information just log in to our website best data structures and algorithms system design