

This blog post guides you on system administration in the cloud such as deploying, managing and operating AWS workloads. Since AWS is exploding into the market as a Cloud provider as well as a leader, it is an excellent time to advance your career and knowledge in AWS administration.
Here, we have provided AWS SysOps Administrator Associate exam questions (SOA-C02) with detailed answers for free. This helps you in understanding the certification objectives clearly and fastens your preparation for this AWS exam.
Also, note that the exam syllabus covers questions from the following domains:
- Domain 1: Monitoring, Logging, and Remediation
- Domain 2: Reliability and Business Continuity
- Domain 3: Deployment, Provisioning, and Automation
- Domain 4: Security and Compliance
- Domain 5: Networking and Content Delivery
- Domain 6: Cost and Performance Optimization
Let’s start exploring!
Domain : Security and Compliance
Q1 : A pharma company has deployed a new web application on multiple Amazon EC2 instances behind an Application Load Balancer and is protected by AWS WAF. The Security Operations team was observing spam traffic from an IP address and instructed you to block immediately. Further checks found that this IP address is accessing web applications from behind the proxy server.
Which is the correct rule that can be applied to meet this requirement?
A. Configure WAF rate-based rules to block matching IP addresses for web request origin.
B. Configure WAF rate-based rules to block matching IP addresses from the X-Forwarded-For HTTP header.
C. Configure WAF rule to block matching IP address from X-Forwarded-For HTTP header.
D. Configure WAF rule to block matching IP address for web request origin.
Correct Answer: C
Explanation
Using AWS WAF, two types of rules can be set; regular rules & rate-based rules. It considers the number of requests coming from a particular IP address in a five-minute interval with rate-based rules. If those requests are exceeding threshold limits, AWS WAF would block the IP address. Regular Rules simply allow or block a matching IP address.
Web request origin consists of the IP address of the proxy server & not of an originating client IP address. In such cases, the originating client IP address is forwarded in the X-Forwarded-For HTTP header.
In the above case, since the IP address needs to be blocked immediately & is behind a proxy server, the AWS WAF rule matching IP address from the X-Forwarded-For HTTP header can suffice the requirement to block spam traffic from this IP address.
Options A & B are incorrect as IP addresses need to be blocked immediately, rate-based rules won’t be an ideal option.
Option D is incorrect as traffic is from an IP address that is behind a proxy server, matching an IP address in web request origin won’t be able to block the traffic. In this case, web request origin consists of the IP address of the proxy server & not of the originating client.
For more information on AWS WAF rules for the forwarded IP addresses, refer to the following URL: https://docs.aws.amazon.com/waf/latest/developerguide/waf-rule-statement-forwarded-ip-address.html
Domain : Deployment, Provisioning, and Automation
Q2 : A Multinational IT firm has a large number of AWS accounts working on various projects. All these accounts are part of AWS Organizations. The Operations Team is facing difficulties in enforcing policies across all these multiple accounts and detecting non-conforming resources. The Operations team is seeking your guidance to automate policy management for this multi-account setup.
Which of the following services is best suited to be implemented along with AWS Organizations to meet this requirement?
A. AWS Control Tower
B. AWS Security Hub
C. AWS Service Catalog
D. AWS Systems Manager
Correct Answer: A
Explanation
AWS Control Tower is best suited for set-up & governing a multi-account AWS environment. AWS Control Towers has the following features.
- Automates Creation of multi-account setup using Landing Zone.
- Automates policy management across multiple accounts using guardrails.
- Integrated dashboard displaying a summary of policies implemented.
In the above case, guardrails can be used to enforce policies using Service control policies and also to detect any non-conforming resources with these accounts.
Option B is incorrect as AWS Security Hub will provide a comprehensive view of security alerts. It is not suited to enforce governance policies across all accounts.
Option C is incorrect as AWS Service Catalog helps create AWS approved IT service catalog. It is not suited to enforce governance policies across all accounts.
Option D is incorrect as AWS Systems Manager is used for tracking and resolving operational issues across all AWS accounts.
For more information on AWS Control Tower, refer to the following URL : https://aws.amazon.com/controltower/features/
Domain : Networking and Content Delivery
Q3 : An ECS cluster running on docker containers is launched using AWS Fargate Launch type. The Operations Team is looking for traffic logs between each of the tasks and engaging you to collect these logs.
Which is the correct interface on which VPC flow logs can be applied to meet this requirement?
A. Apply VPC flow logs on the docker virtual interface to monitor traffic between each task.
B. Apply VPC flow logs on Amazon EC2 instance secondary ENI to monitor traffic between each task.
C. Apply VPC flow logs on ENI of the Amazon ECS task to monitor traffic between each task.
D. Apply VPC flow logs on Amazon EC2 instance primary ENI to monitor traffic between each task.
Correct Answer: C
Explanation
Default networking mode for AWS Fargate launch type is awsvpc, in which each Amazon ECS task launched on the instance gets a separate ENI. For monitoring traffic between tasks, VPC Flow Logs can be applied at the ENI of each task.
Options A, B & D is incorrect as these are invalid options on applying VPC flow logs in the case of AWS Fargate launch type.
For more information on Amazon Fargate task networking, refer to the following URL: https://docs.aws.amazon.com/AmazonECS/latest/userguide/fargate-task-networking.html
Domain : Deployment, Provisioning, and Automation
Q4 : Your team uses a CloudFormation stack for an application. There are a large amount of AWS resources created in the stack, including Auto Scaling groups, Lambda functions, Security groups and Route 53 domain names, which make the CloudFormation template hard to maintain. You want to divide the template into several parts and inherit the resources. In the meantime, you still want to manage all resources in a single stack. Which of the following options is the most appropriate?
A. Ensure that the stack template uses the YAML format and uses the “—” symbol to divide the template into several partitions.
B. Use the “AWS::CloudFormation::Stack” resources to divide the stack into several nested stacks.
C. Use the “AWS::CloudFormation::SubStack” resources to create sub-stacks and export the values in the sub-stacks for other stacks to import.
D. Divide the stack into a CloudFormation StackSet by using the “AWS::CloudFormation::StackSet” resource.
Correct Answer: B
Explanation
Option A is incorrect because the option does not mention how to share resources between different parts, and all resources are still placed into a single template as before.
Option B is CORRECT because, with nested stacks, the whole stack is divided into different stacks. And the outputs from one stack in the nested stack group can be used as inputs to another stack.
Option C is incorrect because the description is wrong as there is no “AWS::CloudFormation::SubStack” resource. Nested stacks should be used instead.
Option D is incorrect because StackSet is used to create stacks across multiple accounts and regions with a single operation. StackSet is not required in this scenario.
Domain : Deployment, Provisioning, and Automation
Q5 : A leading Financial firm has deployed its stock trading application on Amazon EC2 instance in an Auto Scaling Group behind Application Load Balancer. The software Team has developed a new version of this application & are seeking your support to deploy this new version to production. The Operations head has instructed for a deployment using Elastic Beanstalk which should not have any service impact on the application & should be able to quickly rollback in case of failure during deployment. Also post-deployment, initially only 10% of traffic should be diverted to the new version.
Which of the deployment policies can be used to meet the requirement?
A. Use Traffic splitting deployment policy.
B. Use Rolling deployment policy.
C. Use Immutable deployment policy.
D. Use Rolling with an additional batch deployment policy.
Correct Answer: A
Explanation
In the Traffic splitting deployment policy, AWS Elastic Beanstalk launches a full set of EC2 Instance in a new Auto Scaling group for the new version of the application. Post deployment, a certain percentage of traffic can be diverted to a new setup. This policy is easy for rollback. As in case of any failure, traffic can be diverted to the old version which is not modified during deployment of the new version. In the above case, the firm is looking for a new application version to be deployed without any service impact & with 10% traffic to the new version with quick rollback. For this requirement, a traffic splitting deployment policy is best suited.
Option B is incorrect as although this deployment is suitable for deployment without any service impact to the existing application. Still, it’s not suitable for a quick rollback in case of deployment failure.
Option C is incorrect as with this deployment option, traffic splitting between old & new versions is not possible.
Option D is incorrect as this deployment option is not suitable for quick rollback.
For more information on deploying applications with deployment policies with AWS Elastic Beanstalk, refer to the following URLs : https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features.rolling-version-deploy.html, https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features.deploy-existing-version.html
Domain : Deployment, Provisioning, and Automation
Q6 : You have an EC2 instance (i-01234567890123456) in production that has a software issue. To troubleshoot the issue, you need to take an AMI from the instance using AWS CLI. When the image is being created, the instance must not be rebooted. Otherwise, some running scripts will be interrupted. Which of the following AWS CLI commands would you use?
A. aws ec2 create-image \
–instance-id i-01234567890123456 \
–name “My_Image” \
–reboot
B. aws ec2 create-image \
–instance-id i-01234567890123456 \
–name “My_Image” \
–no-reboot
C. aws ec2 create-image \
–instance-id i-01234567890123456 \
–name “My_Image” \
–no-dry-run
D. aws ec2 create-image \
–instance-id i-01234567890123456 \
–name “My_Image”
Correct Answer: B
Explanation
Option A is incorrect because, with the “–reboot” option, Amazon EC2 will shut down and reboot the instance when taking the image.
Option B is CORRECT because the “–no-reboot” option ensures that the EC2 instance does not reboot during image creation.
Option C is incorrect because the “–no-dry-run” option is a boolean attribute to control whether the operation is executed or not. It does not avoid rebooting the instance.
Option D is incorrect because when no option is provided, the EC2 will reboot the instance while creating the image. This behavior is not as expected.
References: https://docs.aws.amazon.com/cli/latest/reference/ec2/create-image.html, https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html
Domain : Security and Compliance
Q7 : You’re planning to allow an Administrator to set up an EC2 Instance. The EC2 Instance will host an application that would need access to a DynamoDB table. Which of the following policy permissions is required to ensure that this implementation can be carried out securely?
A. A trust policy that allows the EC2 Instance to assume a role.
B. A trust policy that allows the user to assume a role.
C. An IAM permission policy that allows the user to assume a role.
D. An IAM permission policy that allows the user to pass a role.
Correct Answers: A and D
Explanation
This is mentioned in the AWS Documentation.
Options B and C are incorrect because the trust policy is used with AWS services to assume a role and the IAM permission policy is used with the user to pass a role.
For more information on IAM roles and pass roles, please refer to the below URL: https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_use_passrole.html
Domain : Reliability and Business Continuity
Q8 : A global financial institution is using AWS cloud infrastructure for its three-tier web application. This is a critical application & any outage would incur a huge financial loss to this institute. They have deployed EC2 instance & Amazon DynamoDB in us-west1 & ap-northeast-1. For EC2 instance, high availability is already considered by the Infrastructure team. IT Head is looking for your support to make database tables fully redundant & failure of the database in one region should not impact the working of web applications.
Which of the following will provide a solution for having a highly available database between these two regions?
A. Copy Data from source DynamoDB table to destination region DynamoDB using Amazon EBS snapshots.
B. Copy Data from source DynamoDB table to destination region DynamoDB using Amazon S3 buckets.
C. Use code to replicate data changes for DynamoDB tables between these two regions.
D. Create a DynamoDB global table to replicate DynamoDB tables between different regions.
Correct Answer: D
Explanation
Amazon DynamoDB Global table can be used to replicate data from one region to another region automatically.
Options A, B, C are incorrect as although this would work, this will add additional admin work for replicating data between regions.
For more information on the Amazon DynamoDB Global table, refer to the following URL: https://aws.amazon.com/dynamodb/global-tables/
Domain : Security and Compliance
Q9 : A global pharma company has provided access to external vendors of the documents stored in the Amazon S3 bucket owned by an R & D account within the AWS Organizations. All accesses to the bucket need to be immediately removed as the vendors are no longer affiliated with the company. As a SysOps administrator, you applied SCP at the OU level to which the R&D account is part, denying all access to the Amazon S3 bucket. Based on AWS CloudTrail Logs external vendors can still access the S3 bucket.
What could be possible reasons for users still have access to the Amazon S3 bucket?
A. SCP does not apply to users outside the AWS Organizations.
B. SCP needs to be applied at account level instead of OU level.
C. SCP needs to be applied at root level instead of OU level.
D. IAM Policy needs to be created for users to explicitly deny access to Amazon S3 bucket along with SCP.
Correct Answer: A
Explanation
SCP affects the ‘principals’ of all accounts within the organization. It does not apply to external users having permission to resources but is not part of the accounts within the AWS Organizations. In the above case, the Amazon S3 bucket is owned by R&D accounts with the AWS Organizations. But users accessing this bucket are external users not part of the R & D account.
Option B is incorrect as Deny permission applied at the OU level will impact all accounts with that OU & no separate policy need to apply at the account level.
Option C is incorrect as SCP will impact all accounts within an OU & does not need to apply at the root level to affect user permissions.
Option D is incorrect as IAM policy needs not to be created along with SCP to deny access. If access is explicitly denied at SCP, users will not be able to access resources.
For more information on Service Control policies, refer to the following URL: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_type-auth.html
Domain : Security and Compliance
Q10 : A team has developed an application that works with a DynamoDB table. Now the application is going to be hosted on an EC2 Instance. Which of the following would you implement to ensure that the application has the relevant permissions to access the DynamoDB table?
A. Create an IAM user with the required permissions and ensure the application runs on behalf of the user on the EC2 instance.
B. Create an IAM group with the required permissions and ensure the application runs on behalf of the group on the EC2 instance.
C. Create an IAM Role with the required permissions and ensure that the Role is assigned to the EC2 Instance.
D. Create Access keys with the required permissions and ensure that the Access keys are embedded in the application.
Correct Answer: C
Explanation
This is also given in the AWS documentation.
Options A and B are incorrect since you need to use IAM Roles.
Option D is incorrect because embedding Access keys is not a secure way to access AWS resources from EC2 Instances.
For more information on managing ID’s in IAM, please refer to the below URL-: https://docs.aws.amazon.com/IAM/latest/UserGuide/id.html
Domain : Security and Compliance
Q11 : The Development Team is planning to use an encrypted Cold HDD Amazon EBS volume with an existing m5.large Amazon EC2 instance for storing application data. While attaching this volume to the Amazon EC2 instance, volume attachment is getting failed & you have been asked to troubleshoot the issue.
What could be a possible reason for this issue?
A. Volume type Cold HDD volume type does not support encryption.
B. Instance type m5. large Amazon EC2 Instances do not support encrypted EBS volume.
C. Default KMS key is used for encryption of Amazon EBS volumes.
D. CMK key status used for encryption is in disabled state.
Correct Answer: D
Explanation
CMK Key used for encryption of Amazon EBS volume should be in Enabled state, else attaching an encrypted Amazon EBS volume to an Amazon EC2 instance fails.
Option A is incorrect as all EBS volumes support encryption.
Option B is incorrect as all current generation EC2 instances support encryption.
Option C is incorrect as using the default key will not affect volume attachment to Amazon EC2 instances. For encryption, either default or custom key can be used.
For more information on Amazon EBS encryption, refer to the following URL https://docs.aws.amazon.com/kms/latest/developerguide/services-ebs.html
Domain : Monitoring, Logging, and Remediation
Q12 : A Multinational bank uses Amazon CloudWatch logs to capture logs from the Amazon EC2 instance on which a critical banking application is deployed. The operations team has created a metric filter for filtering error messages from the logs captured. But intermittently, they are observing no data is getting reported. The Operation Lead has instructed us to check the setting of the metric filters.
What setting can be done with metric filters to resolve this issue?
A. Set Default Value in the metric filter as 0.
B. Set dimensions value in the metric filter as 0.
C. Set metric value in the metric filter as 0.
D. Set filter pattern in the metric filter as 0.
Correct Answer: A
Explanation
Default Value is the value reported when no matching logs are found with a metric filter. By setting Default Value as 0, metric data can always be reported, even if there are no matching metric filters with the captured logs.
Option B is incorrect as dimensions are the key value pair that defines the metric.
Option C is incorrect as this is a metric value based upon matching criteria in the log file.
Option D is incorrect as the filter pattern is the pattern that is specified to match in the log file.
For more information on metric filters with Amazon CloudWatch logs, refer to the following URL: https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/MonitoringLogData.html
Domain : Security and Compliance
Q13 : A start-up firm has created 4 VPC’s – VPC-1, VPC-2, VPC-3 & VPC-4 for deploying its AWS resources. VPC-3 & VPC-4 are used for production environments while VPC-1 & VPC-2 are used for test environments. The Development Team needs to test a new serverless web application using AWS Lambda. IT Head wants you to ensure that Development team users only use VPC-1 & VPC-2 for Lambda functions & no resources are being used from VPC-3 & VPC-4.
Which of the following settings can be configured to meet this requirement?
A. Use IAM Condition keys to specify VPC to be used by Lambda function.
B. Specify VPC ID of VPC-1 & VPC-2 to be used as input parameters to the CreateFunction request.
C. Deny VPC ID of VPC-3 & VPC-4 to be denied as input parameter to the CreateFunction request.
D. Use IAM “aws:SourceVpce” to specify VPC to be used by Lambda function.
Correct Answer: A
Explanation
AWS Lambda uses Condition keys to specify additional permission controls for the Lambda function. Following condition keys are supported in IAM policies.
- lambda:VpcIds – To allow or deny specific VPC to be used by Lambda functions.
- lambda: SubnetIds- To allow or deny a specific subnet in a VPC to be used by Lambda functions.
- lambda:SecurityGroupIds- To allow or deny specific security groups to be used by Lambda functions.
Option B & C are incorrect as VPC ID cannot be specified or denied as an input parameter to the Lambda Function.
Option D is incorrect as “aws:SourceVpce” is not supported by Lambda Function.
For more information on specifying VPC for Lambda Function, refer to the following URL: https://docs.aws.amazon.com/lambda/latest/dg/configuration-vpc.html
Domain : Security and Compliance
Q14 : A company currently has started using the Storage gateway service to extend its storage capacity to the AWS Cloud. There is a mandate that all data should be encrypted at rest by the AWS Storage Gateway. Which of the following would you implement to comply with this request?
A. Create an X.509 certificate that can be used to encrypt the data.
B. Use AWS KMS service to support encryption of the data.
C. Use an SSL certificate to encrypt the data.
D. Use your own master keys to encrypt the data.
Correct Answer: B
Explanation
The AWS Documentation mentions the following.
AWS Storage Gateway uses AWS Key Management Service (AWS KMS) to support encryption. Storage Gateway is integrated with AWS KMS. So, you can use the customer master keys (CMKs) in your account to protect the data that Storage Gateway receives, stores, or manages. Currently, you can do this by using the AWS Storage Gateway API.
All other options are invalid since the right way to encrypt the data is via using KMS keys.
As per AWS docs, Storage Gateway supports AWS KMS to encrypt data stored in AWS by all gateway types. This includes virtual tapes managed by Tape Gateway, in-cloud volumes and EBS Snapshots created by Volume Gateway, and files stored as objects in Amazon Simple Storage Service (S3) by File Gateway.
If AWS KMS is not used, all data stored in AWS by the Storage Gateway service is encrypted with Amazon S3-Managed Encryption Keys (SSE-S3) by default.
Hence option B is the correct choice.
For more information on storage gateway encryption, please refer to the below URL: https://docs.aws.amazon.com/storagegateway/latest/userguide/encryption.html
Domain : Monitoring, Logging, and Remediation
Q15 : Your company has just set up DynamoDB tables. They need monitoring reports to be made available on how much Read and Write Capacity is being utilized. This would help to get a good idea of how much the tables are being utilized. How can you accomplish this?
A. Use Cloudwatch logs to see the amount of Read and Write Capacity being utilized.
B. Use Cloudwatch metrics to see the amount of Read and Write Capacity being utilized.
C. Use Cloudtrail logs to see the amount of Read and Write Capacity being utilized.
D. Use AWS Config logs see the amount of Read and Write Capacity being utilized.
Correct Answer: B
Explanation
The below tables show the metrics available for DynamoDB.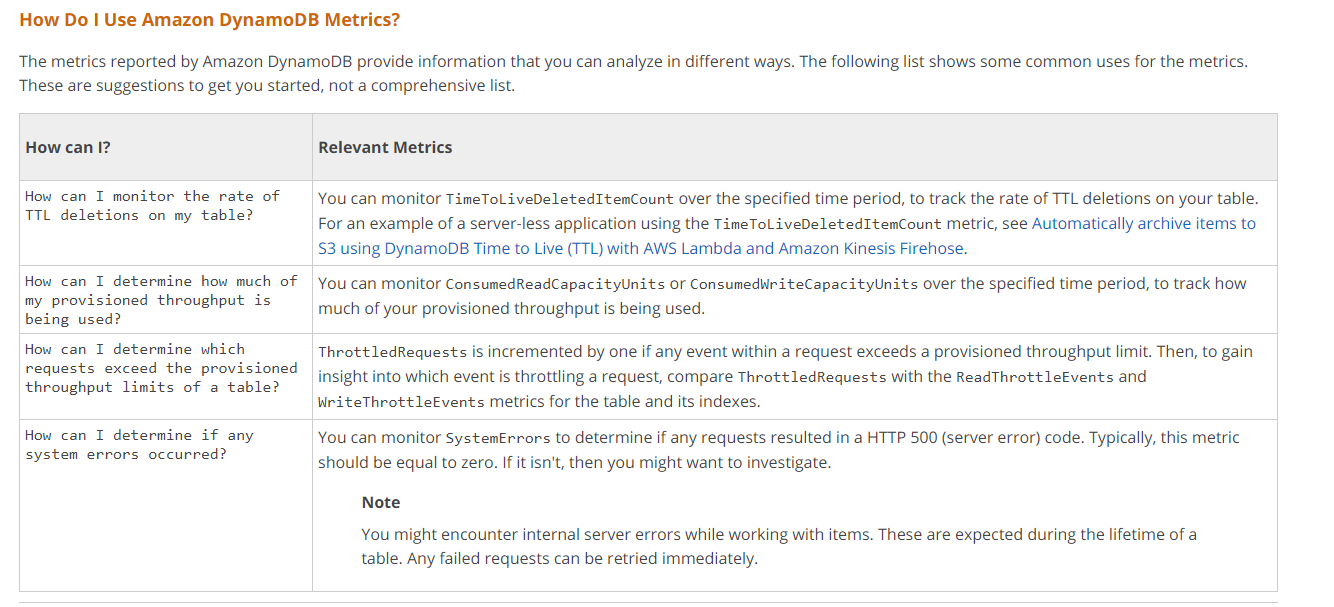
Option A is incorrect since the logs will not give the consumption of the Read and Write Capacity.
Option C is incorrect since cloudtrail is only used for API monitoring.
Option D is incorrect since this is only used for configuration management.
For more information on monitoring with Cloudwatch, please refer to the below URL: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/monitoring-cloudwatch.html
Domain : Reliability and Business Continuity
Q16 : Your team currently has an Autoscaling Group defined in AWS used to manage the EC2 Instances for an application dynamically. Now there are some issues with the application. The team needs to debug the problem. What can be done to ensure that this requirement can be fulfilled?
A. Delete the Autoscaling Group so that you can investigate the underlying Instances.
B. Delete the Launch Configuration so that you can investigate the underlying Instances.
C. Suspend the scaling process so that you can investigate the underlying Instances.
D. Use the AWS Config to take a configuration snapshot of the Instances and then investigate the underlying Instances.
Correct Answer: C
Explanation
The AWS Documentation mentions the following.
You can suspend and then resume one or more of the scaling processes for your Auto Scaling group. This can be useful when you want to investigate a configuration problem or other issue with your web application and then make changes to your application without invoking the scaling processes.
Amazon EC2 Auto Scaling can suspend processes for Auto Scaling groups that repeatedly fail to launch instances. This is known as an administrative suspension, and most commonly applies to Auto Scaling groups trying to launch instances for over 24 hours but have not succeeded in launching any instances. You can resume processes suspended for administrative reasons.
Options A and B are incorrect since you should not delete either the Autoscaling Group or the Launch Configuration. This will disrupt the architecture of the application.
Option D is incorrect since this is not possible with the AWS Config service.
For more information on suspending and resuming autoscaling processes, please visit the following URL- https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-suspend-resume-processes.html
Domain : Deployment, Provisioning, and Automation
Q17 : You have an EC2 Instance which is an EBS backed Instance. An application hosted on this instance is having issues. To resolve the issue, the best bet is to upgrade the instance to a higher instance type. How can you achieve this?
A. Directly change the instance type from the AWS Console.
B. Stop the Instance and then change the Instance Type.
C. Detach the underlying EBS volumes and then change the Instance Type.
D. Detach the underlying ENI and then change the Instance Type.
Correct Answer: B
Explanation
According to the AWS Documentation, EBS-backed instances must be stopped before changing the instance type.
Options A, C and D are invalid for the scenario.
For more information on Resizing EC2 Instances, please refer to the below URL: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-resize.html
Domain : Reliability and Business Continuity
Q18 : Your team is planning to use AWS Backup to centralize the backup of various AWS and on-premises services. The backups are required to be separated into different categories and saved in different containers. Each container should have its own AWS Key Management Service (AWS KMS) key to encrypt backups. How would you achieve this requirement?
A. Organize backups into different S3 buckets and enable Server-Side Encryption with SSE-KMS.
B. Organize backups into different AWS Backup vaults with their own KMS keys.
C. Organize backups with different tags and associate a KMS key with each tag.
D. Organize backups with different backup plans and configure a dedicated KMS key for each backup plan.
Correct Answer: B
Explanation
Option A is incorrect because users cannot organize backups into S3 buckets. AWS Backups use vaults to store the backups.
Option B is CORRECT because users should create several AWS Backup vaults and choose a different KMS key for each vault. Please check the following snapshot on how to create a Backup vault: Option C is incorrect because users cannot associate KMS keys with tags for AWS Backup. This option is not applicable.
Option C is incorrect because users cannot associate KMS keys with tags for AWS Backup. This option is not applicable.
Option D is incorrect because users cannot associate a KMS key when configuring a backup plan.
References: https://docs.aws.amazon.com/aws-backup/latest/devguide/vaults.html, https://docs.aws.amazon.com/aws-backup/latest/devguide/whatisbackup.html
Domain : Monitoring, Logging, and Remediation
Q19 : The team is configuring a WAF ACL to filter the ingress traffic for a new Application Load Balancer. The team needs to check which requests were blocked, allowed, or counted and whether the requests matched the WAF ACL rule properly. Which of the following options is suitable?
A. In the CloudWatch metrics, view the request details for the WAF ACL.
B. In the AWS WAF console, enable request sampling for the WAF ACL and view the detailed data of the sample requests.
C. Enable VPC flow logs, create a log filter for the WAF ACL, and view the request details.
D. Enable WAF logs and save the logs in an S3 bucket. Use Athena to analyze the details for the WAF ACL rule.
Correct Answer: B
Explanation
Option A is incorrect because there are no request details in the WAF CloudWatch metrics.
Option B is CORRECT because, for each sampled request, users can get the request details and determine whether the rule works as expected.
Option C is incorrect because VPC flow logs will not contain the request details filtered by the WAF ACL rule.
Option D is incorrect because WAF logs can only be forwarded to a Kinesis Data Firehose instead of an S3 bucket. There is no need to use Athena as well.
References: https://docs.aws.amazon.com/waf/latest/developerguide/web-acl-testing.html#web-acl-testing-view-sample, https://aws.amazon.com/waf/faqs/
Domain : Deployment, Provisioning, and Automation
Q20 : You are a Systems Administrator for a company. There is a need to host a vendor-based product on an EC2 Instance. Due to the nature of the product’s licensing model, you need to ensure that you have control over the number of cores of the underlying hardware. In such a case, which of the following would you consider?
A. Reserved Instances
B. Dedicated Instances
C. Spot Instances
D. Dedicated Hosts
Correct Answer: D
Explanation
The AWS Documentation mentions the following.
Amazon EC2 Dedicated Hosts allow you to use your eligible software licenses from vendors such as Microsoft and Oracle on Amazon EC2. An Amazon EC2 Dedicated Host is a physical server fully dedicated for your use, so you can help address corporate compliance requirements.
An important difference between a Dedicated Host and a Dedicated instance is that a Dedicated Host gives you additional visibility and control over how instances are placed on a physical server. You can consistently deploy your instances to the same physical server over time. As a result, Dedicated Hosts enable you to use your existing server-bound software licenses and address corporate compliance and regulatory requirements.
Because this is clearly mentioned in the documentation, all other options are invalid.
For more information on dedicated hosts, please refer to the below URL: https://aws.amazon.com/ec2/dedicated-hosts/
Domain : Cost and Performance Optimization
Q21 : Your company has a set of resources defined in AWS. They have a particular budget per month and want to be notified if they are coming close to that budget regarding the usage costs for the underlying resources. How could you achieve this requirement?
A. Create an alarm based on the costing metrics for a collection of resources.
B. Create a billing alarm from within Cloudwatch.
C. Create a billing alarm from within Cost Explorer.
D. Create a billing alarm from within IAM.
Correct Answer: B
Explanation
This is given in the AWS Documentation.
You can monitor your estimated AWS charges using Amazon CloudWatch. When you enable the monitoring of estimated charges for your AWS account, the estimated charges are calculated and sent several times daily to CloudWatch as metric data.
Option A is invalid because you cannot get cost as a metric specifically in Cloudwatch.
Options C and D are invalid because the billing alarm needs to be created from Cloudwatch.
For more information on monitoring charges with AWS Cloudwatch, please refer to the below URL: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.htm
Domain : Monitoring, Logging, and Remediation
Q22 : There is a three-tier Web Application behind an Application Load Balancer. Auto Scaling Group is created for EC2 to dynamically scale-out when CPU utilization is higher than 75%. All these EC2 instances are spread across multiple AZ’s of the eu-central-1 region. The operational Director is looking for an aggregate CPU utilization for all EC2 instances part of this Auto Scaling group. Which of the following CloudWatch Metric setting can be done to meet this requirement?
A. Enable “CPU Utilization” metric for each EC2 instance in Auto Scaling Group & aggregate these values to get CPU utilization for all EC2 instances.
B. Enable “CPU Utilization” metric for each EC2 instance within each Availability zone for Auto Scaling Group to display aggregate CPU utilization for all EC2 instances.
C. Enable “CPU Utilization” metric for EC2 with dimension as “AutoScalingGroupName” to display aggregate CPU utilization for all EC2 instances.
D. Enable “CPU Utilization” metric for EC2 within each Availability Zone with dimension as “AutoScalingGroupName” to display aggregate CPU utilization for all EC2 instances.
Correct Answer: C
Explanation
For getting an aggregate metric for all EC2 instances in an Auto Scaling group, dimension as “AutoScalingGroupName” can be used. In the above case, metric “CPUUtilization” can be set for EC2 instance with dimension as “AutoScalingGroupName” to aggregate CPU utilization for all EC2 instances across availability zones. The following are dimensions can be set for each metric.
- AutoScalingGroupName
- ImageId
- InstanceId
- InstanceType
Option A is incorrect as the aggregation of “CPU Utilization” for each EC2 Instance in an Auto Scaling Group is not required as the same can be displayed using AutoScalingGroupName Dimension.
Option B is incorrect as the aggregation of “CPU Utilization” for each EC2 Instance per Availability Zone in an Auto Scaling Group is not required. The same can be displayed using AutoScalingGroupName Dimension.
Option D is incorrect as there is no need to create Metrics per Availability Zone. While choosing dimension as Auto Scaling Group, it will select all EC2 instances in that group irrespective of Availability Zone.
For more information on Aggregating Statistics by Auto Scaling group, refer to the following URL: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/GetMetricAutoScalingGroup.html
Domain : Networking and Content Delivery
Q23 : Your company has 2 AWS accounts which has individual VPC’s. These VPC’s need to communicate with each other. The AWS accounts are in different regions. The VPC’s have non-overlapping CIDR blocks. Which of the following would be a cost-effective connectivity option?
A. Use VPN connections.
B. Use VPC peering between the 2 VPC’s.
C. Use AWS Direct Connect.
D. Use a NAT gateway.
Correct Answer: B
Explanation
The AWS Documentation mentions the following.
A VPC peering connection is a networking connection between two VPCs that enables you to route traffic between them privately. Instances in either VPC can communicate with each other as if they are within the same network. You can create a VPC peering connection between your own VPCs, with a VPC in another AWS account, or with a VPC in a different AWS Region.
AWS uses the existing infrastructure of a VPC to create a VPC peering connection; it is neither a gateway nor a VPN connection and does not rely on a separate piece of physical hardware. There is no single point of failure for communication or a bandwidth bottleneck.
Options A and C are incorrect since VPC peering is easier to establish.
Option D is incorrect since this is used for instances in the private subnet to communicate with the Internet.
For more information on VPC peering, please refer to the below URL: https://docs.aws.amazon.com/vpc/latest/userguide/vpc-peering.html
Domain : Deployment, Provisioning, and Automation
Q24 : You have a fleet of Linux EC2 Instances. They need to have a shared data store, where the file system needs to be mounted on a fleet of instances. The size of the items will vary from 1KB to 300 MB. The maximum size of the data store will be 3TB. The data needs to have a consistent read view. There are few changes to the data with reasonably no conflicts. Which of the following would be the ideal data store for the fleet of Instances?
A. Elastic File System
B. Amazon S3
C. Amazon EBS Volumes
D. Amazon DynamoDB
Correct Answer: A
Explanation
The following is mentioned in the AWS Documentation when it comes to the features of EFS.
Amazon EFS file systems can automatically scale from gigabytes to petabytes of data without needing to provision storage. Tens, hundreds, or even thousands of Amazon EC2 instances can simultaneously access an Amazon EFS file system. Amazon EFS provides consistent performance to each Amazon EC2 instance.
Amazon EFS provides a file system interface, file system access semantics (such as strong consistency and file locking), and concurrently-accessible storage for up to thousands of Amazon EC2 instances.
Option B is invalid since this is used for object-level storage that is available from the Internet.
Option C is invalid since this is used for local block-level storage for EC2 Instances.
Option D is invalid since this is used for the NoSQL database and ideally not suitable for such large item data sizes.
For more information on the EFS file system, please refer to the below URL: https://aws.amazon.com/efs/faq/
Domain : Monitoring, Logging, and Remediation
Q25 : You are working as SysOps Administrator for a financial firm. As per the legal team’s guidelines, you need to save all customer transactions for seven years for compliance & audit purpose. You created a vault for storing archives in S3 Glacier.
You also need to ensure that no changes or deletion is made to these archives for seven years but need to ensure that files can be accessed multiple times for read purpose. Which of the following policy can be enforced to meet this requirement?
A. Vault Access Policy
B. S3 Bucket policy
C. Glacier Control Policy
D. Vault Lock Policy
Correct Answer: D
Explanation
A vault lock policy can be locked to prevent future changes, providing strong enforcement for your compliance controls. You can use the vault lock policy to deploy regulatory and compliance controls, requiring tight controls on data access.
Option A is incorrect as the vault access policy is used to implement access controls that are not compliance related, temporary, and subject to frequent modification.
Option B is incorrect as the S3 bucket policy is used to grant permission to your Amazon S3 resources.
Option C is incorrect as there is nothing as Glacier control policy.
For more information on Vault Access Policy & Vault lock Policy, refer to the following URL: https://docs.aws.amazon.com/amazonglacier/latest/dev/access-control-resource-based.html
Domain: Monitoring, Logging, and Remediation
Q26: Operations Team has observed that few critical vaults are deleted from the Amazon S3 Glacier using AWS CLI. Operation Head is looking for details of the users who perform these operations. They are seeking help from you specifically to get the time of deletion & source IP address.
Which service can be used to get the required information ?
A. Create an Amazon CloudTrail trail to log data events.
B. Create an Amazon CloudTrail trail to log all events.
C. Create an AWS Config rule.
D. Create AWS Trusted Advisor checks.
Correct Answer : B
Explanation: Amazon S3 Glacier is integrated with Amazon CloudTrail. A CloudTrail trail can be created to log all events to Amazon S3 buckets. All the API actions made to vault like describe vault, delete vault, create vaults in Amazon S3 Glacier are captured in these logs. Logs consist of details like time of activity as well as details of users which includes account id, user name, arn etc.
Data Events provides insights into data plane operations on the resources which includes operations such as Amazon S3 object level APIs and Lambda function invoke API. For logging operations made to Amazon S3 Glacier, data events are not required.
Option A is incorrect as Amazon CloudTrail trail with data events is required for Amazon S3 to log objects levels events. It’s not required to log actions made to vaults in Amazon S3 Glacier.
Option C is incorrect as AWS Config rule cannot be used to get details of the changes made to Amazon S3 Glacier vaults.
Option D is incorrect as AWS Trusted Advisor cannot be used to get details of the changes made to Amazon S3 Glacier vaults.
For more information on Amazon CLoudTrail logs for Amazon S3 Glacier, refer to the following URL,
https://docs.aws.amazon.com/amazonglacier/latest/dev/audit-logging.html
https://aws.amazon.com/cloudtrail/faqs/
Domain: Reliability and Business Continuity
Q27: An IT company has deployed a file gateway as a VM in an on-premise HA enabled VMware vSphere cluster. To provide redundancy, this file gateway needs to be configured as HA and will be used to upload data to Amazon S3 bucket.
What additional prerequisite is necessary for using the HA feature of file Gateway ?
A. Multiple S3 buckets in a single AZ.
B. A shared datastore.
C. Multiple S3 buckets in different AZ.
D. Cluster with vSphere DRS mode enabled.
Correct Answer: B
Explanation: To use the HA feature of Storage Gateway, VMware environment must provide the following:
- A cluster with vSphere HA enabled
- A shared datastore
Option A is incorrect as Multiple S3 buckets in a single AZ is not a prerequisite for using HA feature of file gateway within a VMware environment.
Option C is incorrect as S3 bucket in different AZ is not a prerequisite for using HA feature of file gateway within a VMware environment.
Option D is incorrect as vSphere DRS mode is for load-balancing , it’s not required for using HA feature of file gateway within a VMware environment.
For more information on file gateway in VM environment, refer to the following URL,
Domain: Monitoring, Logging, and Remediation
Q28: A start-up firm is using Amazon S3 file gateway to securely store on-premise data to AWS. The Sysops Team needs to ensure that all cache data is properly uploaded to AWS, so that in the event of disaster there is no impact due to data loss. Operations Lead needs you to share the percentage of data which is not uploaded to AWS.
Which Amazon CloudWatch metric can be checked for this purpose?
- CacheMissPercent
- CacheHitPercent
- CachePercentDirty
- CachePercentUsed
Correct Answer: C
Explanation: CachePercentDirty is an Amazon CloudWatch metric for Amazon S3 File Gateway which provides a percentage of the data which is not uploaded to AWS from local Cache. This metric value should be near to zero to ensure all cache data is properly uploaded to AWS.
Option A is incorrect as CacheMissPercent is an invalid Amazon CloudWatch metric for storage gateway
Option B is incorrect as CacheHitPercent will provide a percentage of a read request handled by the cache. This will not provide details of the content that is uploaded to AWS.
Option D is incorrect as CachePercentUsed will provide the percentage of the cache used, it would not provide details of the content that is uploaded to AWS.
For more information on monitoring performance with Amazon Storage Gateway, refer to the following URL,
Domain: Reliability and Business Continuity
Q29: A digital enterprise is looking for storage options with Amazon EFS for its new gaming application. Files stored will be rarely accessed after upload but should always be readily available. They are looking for the most cost-effective storage options to store these data.
Which storage class is best suited to meet this requirement ?
A. Amazon EFS Standard-IA.
B. Amazon EFS Standard
C. Amazon EFS One Zone
D. Amazon EFS One Zone-IA
Correct Answer : A
Explanation: Amazon EFS Standard-IA storage class can be used to store data that is infrequently accessed but requires high availability & durability. With Amazon EFS Standard-IA storage class, data is stored redundantly across multiple AZ.
Option B is incorrect as since files will be accessed infrequently ,Amazon EFS Standard-IA is more cost-effective than using Amazon EFS Standard storage class.
Option C is incorrect as with Amazon EFS One Zone, there is a risk of data loss when the AZ is unavailable.
Option D is incorrect as with Amazon EFS One Zone-IA, there is a risk of data loss when one AZ is not available.
For more information on storage classes with Amazon EFS , refer to the following URL,
https://docs.aws.amazon.com/efs/latest/ug/storage-classes.html
Domain: Reliability and Business Continuity
Q30: The Development Team is planning to use Amazon FSx for Windows File Server for storing windows-based application data. This critical application needs to be highly available. Operations Lead is concerned about the availability of the data store within Amazon FSx servers.
Which is the correct statement for high availability for Amazon FSx ?
A. Active & Standby Servers for Amazon FSx are placed in single AZ, with synchronous replication between active & standby servers.
B. Active & Standby Servers for Amazon FSx are placed in different AZ, with synchronous replication between active & standby servers.
C. Active & Standby Servers for Amazon FSx are placed in single AZ, with asynchronous replication between active & standby servers.
D. Active & Standby Servers for Amazon FSx are placed in different AZ, with asynchronous replication between active & standby servers.
Correct Answer: B
Explanation: With Multi-AZ deployment, active & standby servers are placed in separate AZ. Data written to an active server is synchronously replicated to standby servers. With Synchronous replication, data is written to active & standby servers simultaneously while with asynchronous replication, there might be lag between data written to active servers & standby servers. Synchronous Replication is advantageous during failover where standby servers are in sync with active servers.
Option A is incorrect as With Multi AZ deployment active & standby servers must be placed in Multi-AZ & not in a single AZ.
Option C is incorrect as With Multi AZ deployment active & standby servers must be placed in Multi-AZ & not in a single AZ.
Option D is incorrect as With Multi-AZ deployment, replication between active & standby servers must be synchronous & not asynchronous.
For more information on high availability for Amazon FSx, refer to the following URL,
https://aws.amazon.com/fsx/windows/features/?nc=sn&loc=2
Domain: Deployment, Provisioning, and Automation
Q31:The Developer team is planning to deploy a new application that will use the Amazon RDS database. This application will be initiating a large number of connections with the database & these connections will be opened at a very high rate. The Database Lead is concerned about the load on DB instance memory & compute resources while using this application. You have been assigned a task to select a service that will reduce the load on the database & improve application performance with RDS.
Which service is best suited to meet this requirement?
- Amazon RDS Proxy
- Amazon RDS Read Replica
- Amazon RDS Multi-AZ
- Amazon RDS Snapshots
Correct Answer –A
Explanation: Amazon RDS Proxy is a fully managed proxy service for Amazon RDS. It allows applications to pool & share connections established with the RDS database. This can help to reduce the load on RDS databases especially for applications that initiate a large number of connections with RDS databases.
Option B is incorrect as Amazon RDS Read Replica allows reading from multiple RDS DB instances. This will not be useful for applications initiating a large number of connections with the Amazon RDS database.
Option C is incorrect as Amazon RDS Multi-AZ provides high availability for Amazon RDS database & failover to standby DB instance in case of failure to primary DB instance. This will not help to improve application performance while accessing RDS databases.
Option D is incorrect as Amazon RDS Snapshots is an invalid option for this case. Snapshots can be used to create DB instances in case of disaster.
For more information on Amazon RDS Proxy, refer to the following URL,
https://aws.amazon.com/rds/proxy/?nc=sn&loc=1
Domain: Reliability and Business Continuity
Q32: A media firm has deployed Amazon RDS across multiple regions. The Operations team has shared an encrypted snapshot of DB instances with multiple accounts. One of the accounts wants to restore DB instances from this snapshot & is seeking your guidance to immediately restore DB instances.
What is the correct option to restore a DB instance?
- Directly restore a DB instance from the encrypted DB snapshot.
- Make a copy of the encrypted DB snapshot & restore the DB instance from the copy.
- Create an unencrypted snapshot from the encrypted DB snapshot & restore the DB instance from the copy.
- Create an unencrypted snapshot from encrypted DB snapshot & directly restore a DB instance from the DB snapshot.
Correct Answer –B
Explanation: To restore a DB instance from shared encrypted snapshots, first need to create a copy of the DB snapshot & then need to create a DB instance from the copy of the snapshot.
Option A is incorrect as DB instances cannot be directly restored from an encrypted DB snapshot. First, a copy needs to be created from an encrypted snapshot & then a DB instance can be restored from the copy.
Option C is incorrect as there is no need to create an unencrypted DB snapshot, to restore a DB instance from an encrypted DB snapshot.
Option D is incorrect as there is no need to create an unencrypted DB snapshot, to restore a DB instance from an encrypted DB snapshot.
For more information on restoring DB instance from an encrypted DB snapshot, refer to the following URL,
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ShareSnapshot.html
Domain: Networking and Content Delivery
Q33: Amazon CloudFront is used as a CDN (content delivery network) for servers deployed at on-premise data centres. Origin servers deployed at on-premise data centres are adding the Cache-Control header. Management is looking for a setting in Amazon CloudFront which will control cache duration in CloudFront Cache irrespective of the values defined in the Cache-Control header.
Which header can be used with Amazon CloudFront to specify the time for which objects remain in the CloudFront cache?
- Whitelist Headers
- Query String Caching Headers.
- Origin Cache Headers.
- Origin Custom Headers.
Correct Answer –C
Explanation: Object Cache Headers are used to specify the minimum & maximum time an object is cached in an Amazon CloudFront Cache. Values specified in these headers will be used for object caching irrespective of values in Cache-Control headers defined by the origin servers.
Option A is incorrect as these headers will be used to specify which content needs to be cache by Amazon CloudFront.
Option B is incorrect as these headers are used to cache different versions of the content based upon values specified in the query string.
Option D is incorrect as this is an invalid header for specifying the period for object caching in Amazon CloudFront. These headers are used to add custom headers while sending requests to the origin.
For more information on object caching with Amazon CloudFront, refer to the following URL,
Domain: Networking and Content Delivery
Q34: An IT firm has deployed multiple web servers in the AWS cloud for its client. All these web servers perform the same functionality & are using Amazon Route 53 to route internet traffic to these servers. The client is looking for the number of healthy resources from all the web servers & should be notified when the number of healthy web servers count is below three.
Which health checks can be configured with Amazon Route 53?
- Route 53 Application Recovery Controller health checks.
- Health Check monitoring CloudWatch Alarms.
- Health Checks monitoring endpoint.
- Health Checks monitoring other health checks.
Correct Answer –D
Explanation: The client is looking for several healthy resources from all the web servers. For this, health checks can be created to monitor other health checks which in turn can notify when the resource count falls below a threshold value. During configuration, health checks are configured for individual resources without creating any notification. Health checks monitoring status of these health checks are configured which will notify count of healthy resource count.
Option A is incorrect as these health checks will provide insights into the application & will not be useful for the above case.
Option B is incorrect as this health check will monitor the data streams which CloudWatch alarms also monitor. These health checks will not be useful in the above case.
Option C is incorrect as these health checks will monitor individual endpoints. In the above case, the client is looking for consolidated health checks & a count of healthy resources among all the web servers. Health Checks monitoring other health checks is a better option for this requirement.
For more information on health checks with Amazon Route 53, refer to the following URL,
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/health-checks-types.html
Domain: Monitoring, Logging, and Remediation
Q35: An Airlines company is using ELB as a front-end for all web servers deployed in AWS. For audit purposes, the security team is looking for the access logs from ELB. You have been assigned to fetch these logs & also need to share the encryption format used for storing these logs with the security team.
Which is the correct action to share these details?
- Fetch Access Logs stored from Amazon S3 bucket in the same region as that of ELB & encryption format for storing access logs is SSE-S3 encryption.
- Fetch Access Logs stored from Amazon S3 bucket in a different region than ELB & encryption format for storing access logs is SSE-S3 encryption.
- Fetch Access Logs stored from Amazon S3 bucket in a different region than ELB & encryption format for storing access logs is SSE-KMS encryption.
- Fetch Access Logs stored from Amazon S3 bucket in the same region as that of ELB & encryption format for storing access logs is SSE-KMS encryption.
Correct Answer – A
Explanation: Access Logs for ELB captures detailed information about requests sent to ELB. Access Logs are disabled by default & can be optionally enabled. Once enabled, Access logs are stored in an Amazon S3 bucket in the same region as that of ELB. Access Log files are automatically encrypted using SSE-S3 encryption before storing them in the S3 bucket.
Option B is incorrect as ELB Access Logs are stored in the same region Amazon S3 bucket as that of ELB.
Option C is incorrect as ELB Access Logs are encrypted using SSE-S3 encryption keys & not using SSE-KMS keys. Also, ELB Access Logs are stored in the same region Amazon S3 bucket as that of ELB.
Option D is incorrect as ELB Access Logs are encrypted using SSE-S3 encryption keys & not using SSE-KMS keys.
For more information on ELB Access Logs, refer to the following URL,
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/load-balancer-access-logs.html
Domain: Cost and Performance Optimization
Q36: A global digital enterprise is using Amazon EFS for storing data of a mission-critical application. Recently the application is facing performance issues with Amazon EFS. Management is seeking your advice to suggest options to optimize application performance.
Which of the following can be recommended to enhance application performance?
- Use an application that does not use encryption in transit while communicating with Amazon EFS.
- Parallelize applications across multiple Amazon EC2 instances.
- Use EBS optimized Amazon EC2 instance for deploying applications.
- Minimise the I/O size of the application which will lead to an increase in throughput.
Correct Answer –B
Explanation: Amazon EFS can be accessed concurrently by multiple Amazon EC2 instances. Parallelizing application across multiple Amazon EC2 instances leads to access data from Amazon EFS concurrently increasing throughput & in turn enhancing performance.
Option A is incorrect as disabling Encryption in transit does not have any impact on Amazon EFS performance. There is very minimal impact on I/O latency & performance , when encryption is enabled or disabled with Amazon EFS.
Option C is incorrect as to enhance performance with Amazon EFS , applications need not be installed on EBS optimised Amazon EC2 instance.While considering Amazon EC2 instance for application using Amazon EFS, instance size should be selected based upon resource requirement of the application.
Option D is incorrect as throughput for Amazon EFS increases when average I/O size increases & not decreases.
For more information on Amazon EFS Performance, refer to the following URL,
https://docs.aws.amazon.com/efs/latest/ug/performance-tips.html
Domain: Networking and Content Delivery
Q37: An IT Firm is using hybrid connectivity from its on-premise office to AWS using Site-to-Site VPN. The project team is planning to implement AWS Direct Connect connectivity. Management is looking for a difference between Site-to-Site VPN & AWS Direct Connect.
Which is the correct statement for the enhancement provided by AWS Direct Connect over Site-to-Site VPN?
- AWS Direct Connect is an encrypted connection over the public internet.
- AWS Direct Connect is an encrypted private connectivity.
- AWS Direct Connect is a dedicated private connectivity.
- AWS Direct Connect is a dedicated connectivity over the public internet.
Correct Answer –C
Explanation: AWS Direct Connect provides a dedicated private connectivity from an on-premise location to AWS. Since it is a dedicated link, it provides consistent network performance over link speed ranging from 50 Mbps to 100 Gbps.
Option A is incorrect as AWS Direct Connect does not provide encrypted connections over the public internet, AWS Site-to-Site VPN uses IPsec encrypted connectivity over the public internet.
Option B is incorrect as AWS Direct Connect does not provide encrypted connections over private connectivity.
Option D is incorrect as AWS Direct Connect is a dedicated connectivity over private links & not over the public internet.
For more information on AWS Direct Connect, refer to the following URL,
https://aws.amazon.com/directconnect/faqs/
Domain: Networking and Content Delivery
Q38: A start-up firm is planning to set up new hybrid connectivity using AWS Site-to-Site VPN. The Project Team working to set up this connectivity has configured a Customer Gateway device with a public IP address & is looking for a default option to bring up VPN tunnels for this new connectivity.
Which is the default option to bring VPN tunnels UP?
- To bring VPN Tunnel UP, use a network tool at on-premise customer gateway device.
- VPN Tunnels are UP automatically once a Customer Gateway device is configured with a Public IP address.
- AWS should initiate IKE negotiations to bring Tunnel UP.
- Customer Gateway should initiate IKE negotiations to bring Tunnel UP.
Correct Answer –D
Explanation: For AWS Site-to-Site VPN, by default Customer gateway devices initiate IKE negotiations to bring VPN Tunnels UP.
Option A is incorrect as to bring VPN tunnel UP, additional networking tool is not required.
Option B is incorrect as VPN Tunnels are not automatically UP when the Customer gateway is assigned with an IP address. Tunnels are UP when IKE negotiations are initiated from the customer gateway.
Option C is incorrect as AWS can initiate IKE negotiations, but this is not a default option.
For more information on initiating VPN Tunnels, refer to the following URL,
https://docs.aws.amazon.com/vpn/latest/s2svpn/initiate-vpn-tunnels.html
Domain: Reliability and Business Continuity
Q39: A global investment firm has recently deployed web servers in AWS multiple regions. Applications on these servers are critical to the firm & only a few minutes of downtime is acceptable in event of a disaster. Management is looking for a strategy that would provide faster RTO & low RPO with a constrained budget.
Which of the most appropriate disaster recovery strategies can be adopted?
- Multi-Site
- Pilot Light
- Warm Standby
- Backup & Restore
Correct Answer –C
Explanation: RTO (Recovery Time Objective) is a period for which downtime is observed post-disaster. RPO is a recovery point objective that defines the amount of data loss when there is a disaster. With the Warm-Standby disaster recovery strategy, all resources deployed at primary sites are deployed at secondary sites at a minimum size. In case of disaster at the primary site, resources at the secondary site are scaled up to achieve load as that of the primary site.
This strategy provides a faster RTO & low RPO. When the primary site is up & running, resources at the secondary site are not running at full load which lowers cost. It costs lower than that of Multi-site strategy in which both primary & secondary sites are running with resources at full load.
Option A is incorrect as Multi-site will provide zero downtime during a disaster as full production scale resources are running at the secondary sites. But this will incur high costs & since the firm is looking for disaster recovery with a limited budget, this is not a correct option.
Option B is incorrect as the Pilot light strategy will provide RTO in tens of minutes & RPO will be higher as resources will be initiated only once a disaster occurs at the primary site.
Option D is incorrect as the Backup & restore strategy will provide RTO in hours & will incur higher RPO.
For more information on disaster recovery strategies, refer to the following URL,
Domain: Deployment, Provisioning, and Automation
Q40: You are configuring an aggregator to collect AWS Config configuration & compliance data using the AWS Config console. This data needs to be captured from resources deployed in multiple regions & part of multiple accounts. Some of these accounts are part of the AWS Organizations.
What additional permissions are required to capture this data?
- Allow data replication to replicate data from AWS Config Configuration recorder to Aggregator account.
- Allow data replication to replicate data from source account to Management account in an Organization which will push data to the aggregator.
- Allow data replication to replicate data from one region to another region where an aggregator is deployed.
- Allow data replication to replicate data from source accounts to aggregator accounts.
Correct Answer –D
Explanation: An Aggregator resource type is used to collect AWS Config configuration & compliance data from multiple regions & accounts. While configuring Aggregator, data replication needs to be allowed which allows AWS config permission to replicate data from source account to aggregator account.
Option A is incorrect as for aggregating data across multiple regions, data is not required to be replicated between AWS Config Configuration recorder & Aggregator.
Option B is incorrect as aggregating data across multiple regions, data is not required to be replicated between source account & management account in AWS Organizations.
Option C is incorrect as additional permission for replicating data within regions is not required.
For more information on configuring AWS Config Aggregator, refer to the following URL,
https://docs.aws.amazon.com/config/latest/developerguide/setup-aggregator-console.html
FAQ :
How many questions are on the aws SOA-C02 Associate exam?
The SOA-C02 Associate exam consist of a total of 65 questions, with an exam duration of 130 minutes
Are there any practice exams or sample questions available for the AWS SOA-C02 certification exam ?
Yes, there are several resources available for practice exams and sample questions for the AWS SysOps Administrator certification . You can find official practice exams on the AWS Training and Certification website.
Furthermore, you can find numerous websites, such as Whizlabs, along with their aws sysops study guide, sample questions and practice exams to assist you in preparing for the certification exam.
Summary:
Now, you got an idea of what is expected in the AWS SysOps Administrator Associate certification exam and how to prepare for it. Additionally, try out the AWS practice tests which have questions and detailed answers for mastering yourself in AWS SysOps Administration.
- A Tour of Google Cloud Hands-on Labs - December 12, 2023
- Mastering Azure Basics: A Deep Dive into AZ-900 Exam Domains - December 4, 2023
- Exploring the Benefits of Validation Feature in Hands-on Labs - October 10, 2023
- 20+ Free MD-102 Exam Questions on Microsoft Endpoint Administrator - September 27, 2023
- 20+ Free MS-102 Exam Questions on Microsoft 365 Administrator Certification - September 25, 2023
- AWS Certified Developer Salary in 2024 - September 19, 2023
- Guide to SharePoint, OneDrive, and Teams External Sharing in Teams - September 10, 2023
- What is Cross-Tenant Synchronization | MS-700 Certification - August 31, 2023