

Preparing for the AWS Certified Solutions Architect Associate Exam? Here we’ve a list of free AWS Solutions Architect Exam Questions and Answers for you to prepare well for the AWS Solution Architect exam. This practice exam questions are very similar to the practice questions in the real exam format.
AWS certification training plays an important role in the journey of AWS certification preparation as it validates your skills in depth. Also, the aws practice questions play an important role in getting you ready for the real time examination.
If you are planning to prepare for the AWS architect certification, you can start with going through these free sample questions created by Whizlabs team.
AWS Solutions Architect Associate Exam Questions
AWS Certified Solutions Architect Associate exam is for those who are performing the role of solutions architect with at least one year of experience in designing scalable, available, robust, and cost-effective distributed applications and systems on the AWS platform.
AWS Solutions Architect Associate (SAA-C03) exam validates your knowledge and skills for
- Architecting and deploying robust and secure applications on the AWS platform using AWS technologies
- Defining a solution with the use of architectural design principles based on customer requirements
- Providing guidance for the implementation on the basis of best practices to the organization over the project lifecycle.
Free AWS Certification Exam Questions
While preparing for the AWS certification exam, you may find a number of resources for the preparation such as AWS documentation, AWS whitepapers, AWS books, AWS Videos, and AWS FAQs. But the practice matters a lot if you are determined to clear the exam on your first attempt.
So, our expert team has curated a list of aws solutions architect practice exam questions with correct answers and detailed explanations for the AWS Certification exam. The same pattern we have followed in Whizlabs most popular AWS Certified Solutions Architect Associate Practice Tests so that you could identify and understand which option is correct and why.
To pass the exam, you’ll need to have a good understanding of AWS services and how to use them to solve common customer problems.
The best way to prepare for the exam is to get AWS Hands on-Labs experience with AWS services & also to get real time experience on AWS Sandbox. This can be done by using the AWS console, getting hands-on experience with AWS CLI, or using the AWS SDKs. Additionally, there are practice exam and online resources that can help you prepare for the exam.
Try these AWS Solutions Architect Associate exam questions SAA-C03 now and check your preparation level. Let’s see how many of these AWS Solutions Architect questions you can solve at Associate-level! Let’s get started!
You can download the AWS solutions architect-associate exam questions pdf for the easy download and reference.
1) You are an AWS Solutions Architect. Your company has a successful web application deployed in an AWS Auto Scaling group. The application attracts more and more global customers. However, the application’s performance is impacted. Your manager asks you how to improve the performance and availability of the application. Which of the following AWS services would you recommend?
A. AWS DataSync
B. Amazon DynamoDB Accelerator
C. AWS Lake Formation
D. AWS Global Accelerator
Answer: D
AWS Global accelerator provides static IP addresses that are anycast in the AWS edge network. Incoming traffic is distributed across endpoints in AWS regions. The performance and availability of the application are improved.
Option A is incorrect: Because DataSync is a tool to automate the data transfer and does not help to improve the performance.
Option B is incorrect: DynamoDB is not mentioned in this question.
Option C is incorrect: Because AWS Lake Formation is used to manage a large amount of data in AWS which would not help in this situation.
Option D is CORRECT: Check the AWS Global Accelerator use cases. The Global Accelerator service can improve both application performance and availability.
2) Your team is developing a high-performance computing (HPC) application. The application resolves complex, compute-intensive problems and needs a high-performance and low-latency Lustre file system. You need to configure this file system in AWS at a low cost. Which method is the most suitable?
A. Create a Lustre file system through Amazon FSx.
B. Launch a high-performance Lustre file system in Amazon EBS.
C. Create a high-speed volume cluster in an EC2 placement group.
D. Launch the Lustre file system from AWS Marketplace.
Answer: A
The Lustre file system is an open-source, parallel file system that can be used for HPC applications. Refer to http://lustre.org/ for its introduction. In Amazon FSx, users can quickly launch a Lustre file system at a low cost.
Option A is CORRECT: Amazon FSx supports Lustre file systems and users pay for only the resources they use.
Option B is incorrect: Although users may be able to configure a Lustre file system through EBS, it needs lots of extra configurations, Option A is more straightforward.
Option C is incorrect: Because the EC2 placement group does not support a Lustre file system.
Option D is incorrect: Because products in AWS Marketplace are not cost-effective. For Amazon FSx, there are no minimum fees or set-up charges. Check its pricing in Amazon FSx for Lustre Pricing.
Read Now: Amazon Braket
3) You host a static website in an S3 bucket and there are global clients from multiple regions. You want to use an AWS service to store cache for frequently accessed content so that the latency is reduced and the data transfer rate is increased. Which of the following options would you choose?
A. Use AWS SDKs to horizontally scale parallel requests to the Amazon S3 service endpoints.
B. Create multiple Amazon S3 buckets and put Amazon EC2 and S3 in the same AWS Region.
C. Enable Cross-Region Replication to several AWS Regions to serve customers from different locations.
D. Configure CloudFront to deliver the content in the S3 bucket.
Answer: D
CloudFront is able to store the frequently accessed content as a cache and the performance is optimized. Other options may help on the performance however they do not store cache for the S3 objects.
Option A is incorrect: This option may increase the throughput however it does not store cache.
Option B is incorrect: Because this option does not use cache.
Option C is incorrect: This option creates multiple S3 buckets in different regions. It does not improve the performance using cache.
Option D is CORRECT: Because CloudFront caches copies of the S3 files in its edge locations and users are routed to the edge location that has the lowest latency.
4) Your company has an online game application deployed in an Auto Scaling group. The traffic of the application is predictable. Every Friday, the traffic starts to increase, remains high on weekends and then drops on Monday. You need to plan the scaling actions for the Auto Scaling group. Which method is the most suitable for the scaling policy?
A. Configure a scheduled CloudWatch event rule to launch/terminate instances at the specified time every week.
B. Create a predefined target tracking scaling policy based on the average CPU metric and the ASG will scale automatically.
C. Select the ASG and on the Automatic Scaling tab, add a step scaling policy to automatically scale-out/in at fixed time every week.
D. Configure a scheduled action in the Auto Scaling group by specifying the recurrence, start/end time, capacities, etc.
Answer: D
The correct scaling policy should be scheduled scaling as it defines your own scaling schedule. Refer to https://docs.aws.amazon.com/autoscaling/ec2/userguide/schedule_time.html for details.
Option A is incorrect: This option may work. However, you have to configure a target such as a Lambda function to perform the scaling actions.
Option B is incorrect: The target tracking scaling policy defines a target for the ASG. The scaling actions do not happen based on a schedule.
Option C is incorrect: The step scaling policy does not configure the ASG to scale at a specified time.
Option D is CORRECT: With scheduled scaling, users define a schedule for the ASG to scale. This option can meet the requirements.
5) You are creating several EC2 instances for a new application. For better performance of the application, both low network latency and high network throughput are required for the EC2 instances. All instances should be launched in a single availability zone. How would you configure this?
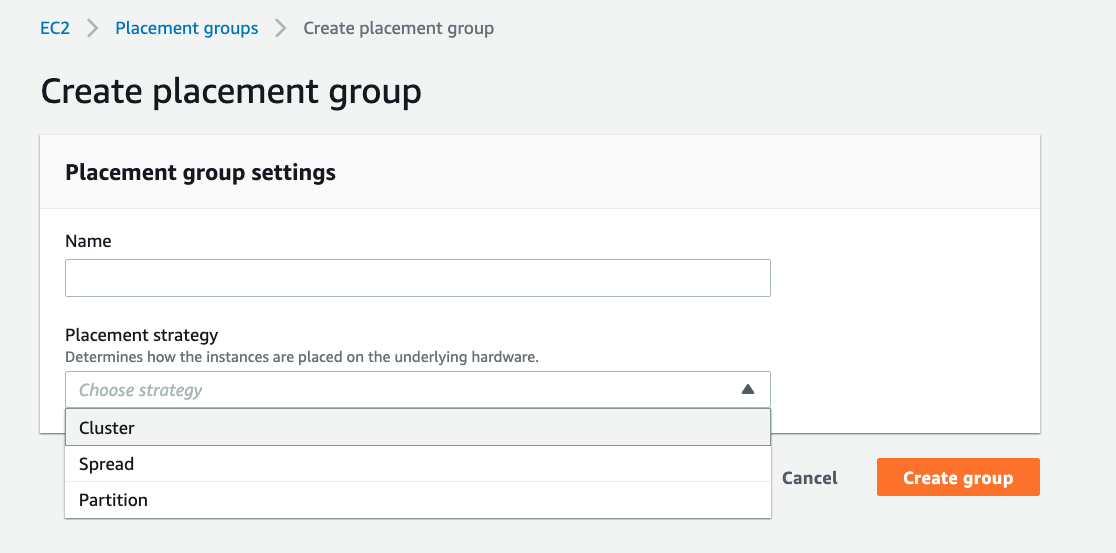
A. Launch all EC2 instances in a placement group using a Cluster placement strategy.
B. Auto-assign a public IP when launching the EC2 instances.
C. Launch EC2 instances in an EC2 placement group and select the Spread placement strategy.
D. When launching the EC2 instances, select an instance type that supports enhanced networking.
Answer: A
The Cluster placement strategy helps to achieve a low-latency and high throughput network. The reference is in https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html#placement-groups-limitations-partition.
Option A is CORRECT: The Cluster placement strategy can improve network performance among EC2 instances. The strategy can be selected when creating a placement group:

Option B is incorrect: Because the public IP cannot improve network performance.
Option C is incorrect: The Spread placement strategy is recommended when a number of critical instances should be kept separate from each other. This strategy should not be used in this scenario.
Option D is incorrect: The description in the option is inaccurate. The correct method is creating a placement group with a suitable placement strategy.
Also Read: AWS OpsWorks
6) You need to deploy a machine learning application in AWS EC2. The performance of inter-instance communication is very critical for the application and you want to attach a network device to the instance so that the performance can be greatly improved. Which option is the most appropriate to improve the performance?
A. Enable enhanced networking features in the EC2 instance.
B. Configure Elastic Fabric Adapter (EFA) in the instance.
C. Attach high-speed Elastic Network Interface (ENI) in the instance.
D. Create an Elastic File System (EFS) and mount the file system in the instance.
Answer: B
With Elastic Fabric Adapter (EFA), users can get better performance if compared with enhanced networking (Elastic Network Adapter) or Elastic Network Interface. Check the differences between EFAs and ENAs in https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa.html.
Option A is incorrect: Because with Elastic Fabric Adapter (EFA), users can achieve a better network performance than enhanced networking.
Option B is CORRECT: Because EFA is the most suitable method for accelerating High-Performance Computing (HPC) and machine learning application.
Option C is incorrect: Because Elastic Network Interface (ENI) cannot improve the performance as required.
Option D is incorrect: The Elastic File System (EFS) cannot accelerate inter-instance communication.
7) You have an S3 bucket that receives photos uploaded by customers. When an object is uploaded, an event notification is sent to an SQS queue with the object details. You also have an ECS cluster that gets messages from the queue to do the batch processing. The queue size may change greatly depending on the number of incoming messages and backend processing speed. Which metric would you use to scale up/down the ECS cluster capacity?
A. The number of messages in the SQS queue.
B. Memory usage of the ECS cluster.
C. Number of objects in the S3 bucket.
D. Number of containers in the ECS cluster.
Answer: A
In this scenario, the SQS queue is used to store the object details which is a highly scalable and reliable service. ECS is ideal to perform batch processing and it should scale up or down based on the number of messages in the queue. Details please check https://github.com/aws-samples/ecs-refarch-batch-processing.
Option A is CORRECT: Users can configure a CloudWatch alarm based on the number of messages in the SQS queue and notify the ECS cluster to scale up or down using the alarm.
Option B is incorrect: Because memory usage may not be able to reflect the workload.
Option C is incorrect: Because the number of objects in S3 cannot determine if the ECS cluster should change its capacity.
Option D is incorrect: Because the number of containers cannot be used as a metric to trigger an auto-scaling event.
10) When creating an AWS CloudFront distribution, which of the following is not an origin?
A. Elastic Load Balancer
B. AWS S3 bucket
C. AWS MediaPackage channel endpoint
D. AWS Lambda
Answer: D

Explanation: AWS Lambda is not supported directly as the CloudFront origin. However, Lambda can be invoked through API Gateway which can be set as the origin for AWS CloudFront. Read more here: https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/Introduction.html
14) Your organization is building a collaboration platform for which they chose AWS EC2 for web and application servers and MySQL RDS instance as the database. Due to the nature of the traffic to the application, they would like to increase the number of connections to RDS instances. How can this be achieved?
A. Login to RDS instance and modify database config file under /etc/mysql/my.cnf
B. Create a new parameter group, attach it to the DB instance and change the setting.
C. Create a new option group, attach it to the DB instance and change the setting.
D. Modify setting in the default options group attached to the DB instance.
Answer: B
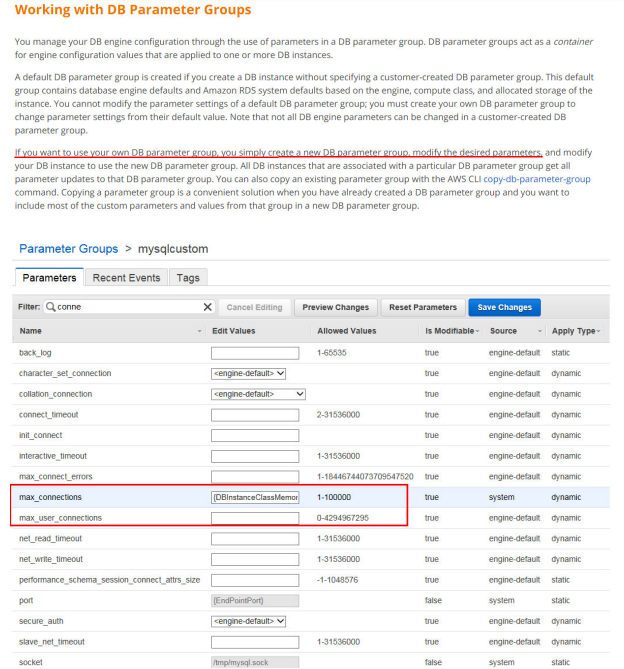
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups
15) You will be launching and terminating EC2 instances on a need basis for your workloads. You need to run some shell scripts and perform certain checks connecting to the AWS S3 bucket when the instance is getting launched. Which of the following options will allow performing any tasks during launch? (choose multiple)
A. Use Instance user data for shell scripts.
B. Use Instance metadata for shell scripts.
C. Use AutoScaling Group lifecycle hooks and trigger AWS Lambda function through CloudWatch events.
D. Use Placement Groups and set “InstanceLaunch” state to trigger AWS Lambda functions.
Answer: A, C
Option A is correct.
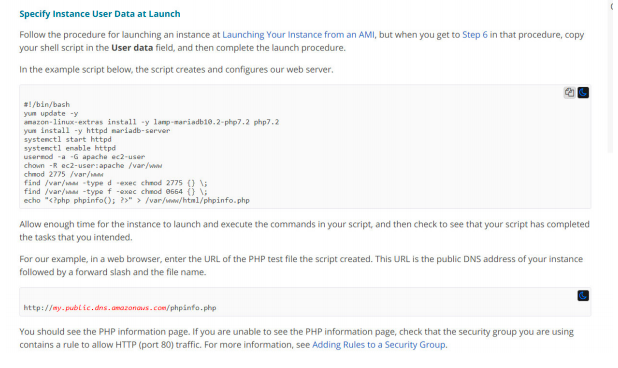
Option C is correct.
16) Your organization has an AWS setup and planning to build Single Sign-On for users to authenticate with on-premise Microsoft Active Directory Federation Services (ADFS) and let users log in to the AWS console using AWS STS Enterprise Identity Federation. Which of the following services do you need to call from AWS STS service after you authenticate with your on-premise?
A. AssumeRoleWithSAML
B. GetFederationToken
C. AssumeRoleWithWebIdentity
D. GetCallerIdentity
Answer: A

https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRoleWithSAML.html
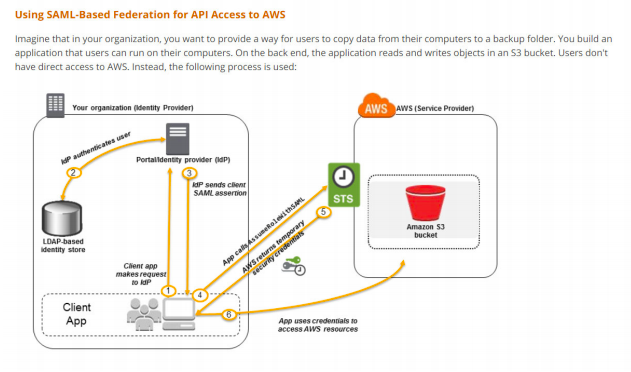
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_saml.html
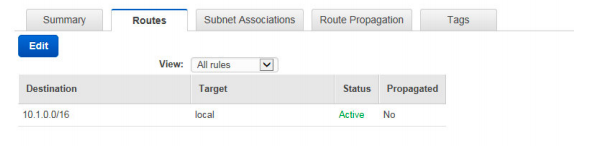
18) Your organization was planning to develop a web application on AWS EC2. Application admin was tasked to perform AWS setup required to spin EC2 instance inside an existing private VPC. He/she has created a subnet and wants to ensure no other subnets in the VPC can communicate with your subnet except for the specific IP address. So he/she created a new route table and associated with the new subnet. When he/she was trying to delete the route with the target as local, there is no option to delete the route. What could have caused this behavior?
A. Policy attached to IAM user does not have access to remove routes.
B. A route with the target as local cannot be deleted.
C. You cannot add/delete routes when associated with the subnet. Remove associated, add/delete routes and associate again with the subnet.
D. There must be at least one route on the route table. Add a new route to enable delete option on existing routes.
Answer: B

https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Route_Tables.html#RouteTa
20) Organization ABC has a requirement to send emails to multiple users from their application deployed on EC2 instance in a private VPC. Email receivers will not be IAM users. You have decided to use AWS Simple Email Service and configured from email address. You are using AWS SES API to send emails from your EC2 instance to multiple users. However, email sending getting failed. Which of the following options could be the reason?
A. You have not created VPC endpoint for SES service and configured in the route table.
B. AWS SES is in sandbox mode by default which can send emails only to verified email addresses.
C. IAM user of configured from email address does not have access AWS SES to send emails.
D. AWS SES cannot send emails to addresses which are not configured as IAM users. You have to use the SMTP service provided by AWS.
Answer: B
Amazon SES is an email platform that provides an easy, cost-effective way for you to send and receive email using your own email addresses and domains.
For example, you can send marketing emails such as special offers, transactional emails such as order confirmations, and other types of correspondence such as newsletters. When you use Amazon SES to receive mail, you can develop software solutions such as email autoresponders, email unsubscribe systems and applications that generate customer support tickets from incoming emails.
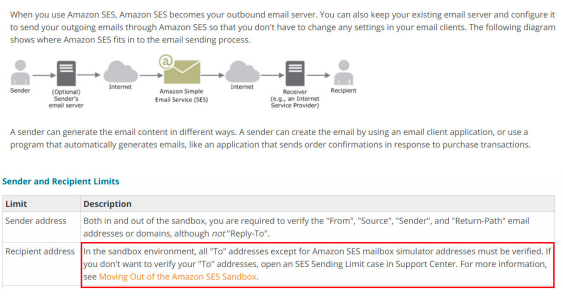
https://docs.aws.amazon.com/ses/latest/DeveloperGuide/limits.html
https://docs.aws.amazon.com/ses/latest/DeveloperGuide/request-production-access.html
21) You have configured AWS S3 event notification to send a message to AWS Simple Queue Service whenever an object is deleted. You are performing a ReceiveMessage API operation on the AWS SQS queue to receive the S3 delete object message onto AWS EC2 instance. For any successful message operations, you are deleting them from the queue. For failed operations, you are not deleting the messages. You have developed a retry mechanism which reruns the application every 5 minutes for failed ReceiveMessage operations. However, you are not receiving the messages again during the rerun. What could have caused this?
A. AWS SQS deletes the message after it has been read through ReceiveMessage API
B. You are using Long Polling which does not guarantee message delivery.
C. Failed ReceiveMessage queue messages are automatically sent to Dead Letter Queues. You need to ReceiveMessage from Dead Letter Queue for failed retries.
D. Visibility Timeout on the SQS queue is set to 10 minutes.
Answer: D
When a consumer receives and processes a message from a queue, the message remains in the queue. Amazon SQS doesn’t automatically delete the message. Because Amazon SQS is a distributed system, there’s no guarantee that the consumer actually receives the message (for example, due to a connectivity issue, or due to an issue in the consumer application). Thus, the consumer must delete the message from the queue after receiving and processing it.

22) You had set up an internal HTTP(S) Elastic Load Balancer to route requests to two EC2 instances inside a private VPC. However, one of the target EC2 instance is showing Unhealthy status. Which of the following options could not be a reason for this?
A. Port 80/443 is not allowed on EC2 instance’s Security Group from the load balancer.
B. An EC2 instance is in different availability zones than load balancer.
C. The ping path does not exist on the EC2 instance.
D. The target did not return a successful response code
Answer: B
If a target is taking longer than expected to enter the InService state, it might be failing health checks. Your target is not in service until it passes one health check.

https://docs.aws.amazon.com/elasticloadbalancing/latest/application/target-group-health-checks.html
23) Your organization has an existing VPC setup and has a requirement to route any traffic going from VPC to AWS S3 bucket through AWS internal network. So they have created a VPC endpoint for S3 and configured to allow traffic for S3 buckets. The application you are developing involves sending traffic to AWS S3 bucket from VPC for which you planned to use a similar approach. You have created a new route table, added route to VPC endpoint and associated route table with your new subnet. However, when you are trying to send a request from EC2 to S3 bucket using AWS CLI, the request is getting failed with 403 access denied errors. What could be causing the failure?
A. AWS S3 bucket is in a different region than your VPC.
B. EC2 security group outbound rules not allowing traffic to S3 prefix list.
C. VPC endpoint might have a restrictive policy and does not contain the new S3 bucket.
D. S3 bucket CORS configuration does not have EC2 instances as the origin.
Answer: C
Option A is not correct. The question states “403 access denied”. If the S3 bucket is in a different region than VPC, the request looks for a route with NAT Gateway or Internet Gateway. If it exists, the request goes through the internet to S3. If it does not exist, the request gets failed with connection refused or connection timed out. Not with an error “403 access denied”.
Option B is not correct. Same as above, when the security group does not allow traffic, the failure cause will be 403 access denied.
Option C is correct.

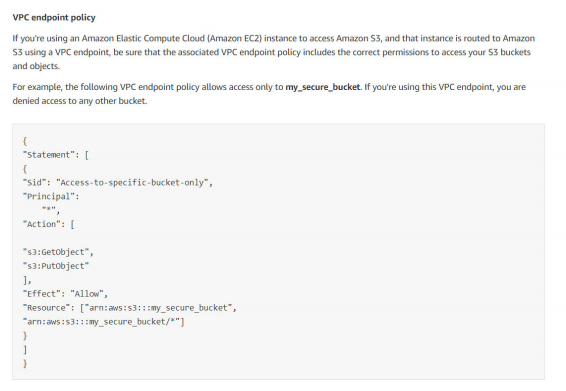
Option D is not correct.
Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources.
In this case, the request is not coming from a web client.
24) You have launched an RDS instance with MySQL database with default configuration for your file sharing application to store all the transactional information. Due to security compliance, your organization wants to encrypt all the databases and storage on the cloud. They approached you to perform this activity on your MySQL RDS database. How can you achieve this?
A. Copy snapshot from the latest snapshot of your RDS instance, select encryption during copy and restore a new DB instance from the newly encrypted snapshot.
B. Stop the RDS instance, modify and select the encryption option. Start the RDS instance, it may take a while to start an RDS instance as existing data is getting encrypted.
C. Create a case with AWS support to enable encryption for your RDS instance.
D. AWS RDS is a managed service and the data at rest in all RDS instances are encrypted by default.
Answer: A
26) You have successfully set up a VPC peering connection in your account between two VPCs – VPC A and VPC B, each in a different region. When you are trying to make a request from VPC A to VPC B, the request fails. Which of the following could be a reason?
A. Cross-region peering is not supported in AWS
B. CIDR blocks of both VPCs might be overlapping.
C. Routes not configured in route tables for peering connections.
D. VPC A security group default outbound rules not allowing traffic to VPC B IP range.
Answer: C
Option A is not correct. Cross-region VPC peering is supported in AWS.
Option B is not correct.
When the VPC IP CIDR blocks are overlapping, you cannot create a peering connection. Question states the peering connection was successful.
Option C is correct.
To send private IPv4 traffic from your instance to an instance in a peer VPC, you must add a route to the route table that’s associated with your subnet in which your instance resides. The route points to the CIDR block (or portion of the CIDR block) of the peer VPC in the VPC peering connection.
https://docs.aws.amazon.com/AmazonVPC/latest/PeeringGuide/vpc-peering-routing.html
Option D is not correct.
A security group’s default outbound rule allows all traffic to go out from the resources attached to the security group.
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_SecurityGroups.html#Defaul
27) Which of the following statements are true in terms of allowing/denying traffic from/to VPC assuming the default rules are not in effect? (choose multiple)
A. In a Network ACL, for a successful HTTPS connection, add an inbound rule with HTTPS type, IP range in source and ALLOW traffic.
B. In a Network ACL, for a successful HTTPS connection, you must add an inbound rule and outbound rule with HTTPS type, IP range in source and destination respectively and ALLOW traffic.
C. In a Security Group, for a successful HTTPS connection, add an inbound rule with HTTPS type and IP range in the source.
D. In a Security Group, for a successful HTTPS connection, you must add an inbound rule and outbound rule with HTTPS type, IP range in source and destination respectively.
Answer: B, C
Security groups are stateful — if you send a request from your instance, the response traffic for that request is allowed to flow in regardless of inbound security group rules. Responses to allowed inbound traffic are allowed to flow out, regardless of outbound rules.
Network ACLs are stateless; responses to allowed inbound traffic are subject to the rules for outbound traffic (and vice versa).
- Option A is not correct. NACL must have an outbound rule defined for a successful connection due to its stateless nature.
- Option B is correct.
- Option C is correct.
- Configuring an inbound rule in a security group is enough for a successful connection due to its stateful nature.
- Option D is not correct.
Configuring an outbound rule for incoming connection is not required in security groups.
- https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_ACLs.html#ACLs
- https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_SecurityGroups.html#VPCSe
Domain : Design Secure Architectures
28) A gaming company stores large size (terabytes to petabytes) of clickstream events data into their central S3 bucket. The company wants to analyze this clickstream data to generate business insight. Amazon Redshift, hosted securely in a private subnet of a VPC, is used for all data warehouse-related and analytical solutions. Using Amazon Redshift, the company wants to explore some solutions to securely run complex analytical queries on the clickstream data stored in S3 without transforming/copying or loading the data in the Redshift.
As a Solutions Architect, which of the following AWS services would you recommend for this requirement, knowing that security and cost are two major priorities for the company?
A. Create a VPC endpoint to establish a secure connection between Amazon Redshift and the S3 central bucket and use Amazon Athena to run the query
B. Use NAT Gateway to connect Amazon Redshift to the internet and access the S3 static website. Use Amazon Redshift Spectrum to run the query
C. Create a VPC endpoint to establish a secure connection between Amazon Redshift and the S3 central bucket and use Amazon Redshift Spectrum to run the query
D. Create Site-to-Site VPN to set up a secure connection between Amazon Redshift and the S3 central bucket and use Amazon Redshift Spectrum to run the query
Answer: C
Explanation
Option A is incorrect because Amazon Athena can directly query data in S3. Hence this will bypass the use of Redshift, which is not the requirement for the customer. They insisted on Amazon Redshift for the query purpose for usage.
Option B is incorrect. Even though it is possible, NAT Gateway will connect Redshift to the internet and make the solution less secure. Plus, this is also not a cost-effective solution. Remember that security and cost both are important for the company.
Option C is CORRECT because VPC Endpoint is a secure and cost-effective way to connect a VPC with Amazon S3 privately, and the traffic does not pass through the internet. Using Amazon Redshift Spectrum, one can run queries against the data stored in the S3 bucket without needing the data to be copied to Amazon Redshift. This meets both the requirements of building a secure yet cost-effective solution.
Option D is incorrect because Site-to-Site VPN is used to connect an on-premises data center to AWS Cloud securely over the internet and is suitable for use cases like Migration, Hybrid Cloud, etc.
References: https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints-s3.html, https://docs.aws.amazon.com/vpn/latest/s2svpn/VPC_VPN.html, https://docs.aws.amazon.com/redshift/latest/dg/c-getting-started-using-spectrum.html
29) The drug research team in a Pharmaceutical company produces highly sensitive data and stores them in Amazon S3. The team wants to ensure top-notch security for their data while it is stored in Amazon S3. To have better control of the security, the team wants to use their own encryption key but doesn’t want to maintain any code to perform data encryption and decryption. Also, the team wants to be responsible for storing the Secret key.
As a Solutions Architect, which of the following encryption types will suit the above requirement?
A. Server-side encryption with customer-provided encryption keys (SSE-C).
B. Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
C. Server-Side Encryption with KMS keys Stored in AWS Key Management Service (SSE-KMS)
D. Protect the data using Client-Side Encryption
Answer: A
Explanation
Data protection refers to the protection of data while in transit (as it travels to and from Amazon S3) and at rest (while it is stored on disks in Amazon S3 data centers).
While data in transit can be protected using Secure Socket Layer/Transport Layer Security (SSL/TLS) or client-side encryption, one has the following options for protecting data at rest in Amazon S3:
Server-Side Encryption – Request Amazon S3 to encrypt your object before saving it on disks in its data centers and then decrypt it when you download the objects.
There are three types of Server-side encryption:
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
Server-Side Encryption with KMS keys Stored in AWS Key Management Service (SSE-KMS)
Server-side encryption with customer-provided encryption keys (SSE-C).
Client-Side Encryption – Encrypt data client-side and upload the encrypted data to Amazon S3. In this case, you manage the encryption process, the encryption keys, and related tools.
In this scenario, the customer is referring to data at rest.
Option A is CORRECT because data security is the top priority for the team, and they want to use their own encryption key. In this option, the customer provides the encryption key while S3 manages encryption – decryption. So there won’t be any operational overhead, yet the customer will have better control in managing the key.
Option B is incorrect because each object is encrypted with a unique key when you use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3). It also encrypts the key itself with a root key that rotates regularly.
This encryption type uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256) GCM, to encrypt your data, but it does not let customers create or manage the key. Hence this is not a choice here.
Option C is incorrect because Server-Side Encryption with AWS KMS keys (SSE-KMS) is similar to SSE-S3 but with some additional benefits and charges for using this service.
There are separate permissions for the use of a KMS key that provides protection against unauthorized access to your objects in Amazon S3.
This option is mainly neglected because AWS still manages the storage of the encryption key or master key (in KMS) while encryption-decryption is managed by the customer. The expectation from the team in the above scenario is just the opposite.

Option D is incorrect because, in this case, one has to manage the encryption process, the encryption keys, and related tools. And it is mentioned clearly above that the team does not want that.
Reference: https://docs.aws.amazon.com/AmazonS3/latest/userguide/serv-side-encryption.html
Domain: Design Cost-Optimized Architectures
30) An online retail company stores a large number of customer data (terabytes to petabytes) into Amazon S3.The company wants to drive some business insight out of this data. They plan to securely run SQL-based complex analytical queries on the S3 data directly and process it to generate business insights and build a data visualization dashboard for the business and management review and decision-making.
You are hired as a Solutions Architect to provide a cost-effective and quick solution to this. Which of the following AWS services would you recommend?
A. Use Amazon Redshift Spectrum to run SQL-based queries on the data stored in Amazon S3 and then process it to Amazon Kinesis Data Analytics for creating a dashboard
B. Use Amazon Redshift to run SQL-based queries on the data stored in Amazon S3 and then process it on a custom web-based dashboard for data visualization
C. Use Amazon EMR to run SQL-based queries on the data stored in Amazon S3 and then process it to Amazon Quicksight for data visualization
D. Use Amazon Athena to run SQL-based queries on the data stored in Amazon S3 and then process it to Amazon Quicksight for dashboard view
Answer: D
Explanation
Option A is incorrect because Amazon Kinesis Data Analytics cannot be used to generate business insights as mentioned in the requirement. It neither can be used for data visualization.
One must depend on some BI tool after processing data from Amazon Kinesis Data Analytics. It is not a cost-optimized solution.
Option B is incorrect primarily due to the cost factors. Using Amazon Redshift for querying S3 data requires the transfer and loading of the data to Redshift instances. It also takes time and additional cost to create a custom web-based dashboard or data visualization tool.
Option C is incorrect because Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. It is mainly used to perform big data analytics, process real-time data streams, accelerate data science and ML adoption. The requirement here is not to build any of such solutions on a Big Data platform. Hence this option is not suitable. It is neither quick nor cost-effective compared to option D.
Option D is CORRECT because Amazon Athena is the most cost-effective solution to run SQL-based analytical queries on S3 data and then publish it to Amazon QuickSight for dashboard view.


References: https://aws.amazon.com/kinesis/data-analytics/?nc=sn&loc=1, https://docs.aws.amazon.com/athena/latest/ug/when-should-i-use-ate.html, https://docs.aws.amazon.com/quicksight/latest/user/welcome.html
Domain : Design Cost-Optimized Architectures
31) An organization has archived all their data to Amazon S3 Glacier for a long term. However, the organization needs to retrieve some portion of the archived data regularly. This retrieval process is quite random and incurs a good amount of cost for the organization. As expense is the top priority, the organization wants to set a data retrieval policy to avoid any data retrieval charges.
Which one of the following retrieval policies suits this in the best way?
A. No Retrieval Limit
B. Free Tier Only
C. Max Retrieval Rate
D. Standard Retrieval
Answer: B
Explanation
Option A is incorrect because No Retrieval Limit, the default data retrieval policy, is used when you do not want to set any retrieval quota. All valid data retrieval requests are accepted. This retrieval policy incurs a high cost to your AWS account for each region.
Option B is CORRECT because using a Free Tier Only policy, you can keep your retrievals within your daily AWS Free Tier allowance and not incur any data retrieval costs. And in this policy, S3 Glacier synchronously rejects retrieval requests that exceed your AWS Free Tier allowance.
Option C is incorrect because you use Max Retrieval Rate policy when you want to retrieve more data than what is in your AWS Free Tier allowance. Max Retrieval Rate policy sets a bytes-per-hour retrieval-rate quota. The Max Retrieval Rate policy ensures that the peak retrieval rate from all retrieval jobs across your account in an AWS Region does not exceed the bytes-per-hour quota that you set. Max Retrieval rate policy is not in the free tier.
Option D is incorrect because Standard Retrieval is a process of data retrieval from S3 Glacier that takes around 12 hours to retrieve data. This retrieval type is chargeable and incurs costs on the AWS account per region wise.

References: https://aws.amazon.com/premiumsupport/knowledge-center/glacier-retrieval-fees/, https://docs.aws.amazon.com/AmazonS3/latest/userguide/restoring-objects-retrieval-options.html, https://docs.aws.amazon.com/amazonglacier/latest/dev/data-retrieval-policy.html
Domain: Design High-Performing Architectures
32) A gaming company planned to launch their new gaming application that will be in both web and mobile platforms. The company considers using GraphQL API to securely query or update data through a single endpoint from multiple databases, microservices, and several other API endpoints. They also want some portions of the data to be updated and accessed in real-time.
The customer prefers to build this new application mostly on serverless components of AWS.
As a Solutions Architect, which of the following AWS services would you recommend the customer to develop their GraphQL API?
A. Kinesis Data Firehose
B. Amazon Neptune
C. Amazon API Gateway
D. AWS AppSync
Answer: D
Explanation
Option A is incorrect because Amazon Kinesis Data Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch, etc. It cannot create GraphQL API.
Option B is incorrect. Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications. It is a database and cannot be used to create GraphQL API.
 Option C is incorrect because Amazon API Gateway supports RESTful APIs (HTTP and REST API) and WebSocket APIs. It is not meant for the development of GraphQL API.
Option C is incorrect because Amazon API Gateway supports RESTful APIs (HTTP and REST API) and WebSocket APIs. It is not meant for the development of GraphQL API.
Option D is CORRECT because with AWS AppSync one can create serverless GraphQL APIs that simplify application development by providing a single endpoint to securely query or update data from multiple data sources and leverage GraphQL to implement engaging real-time application experiences.
References: https://aws.amazon.com/neptune/features/, https://aws.amazon.com/api-gateway/features/, https://aws.amazon.com/appsync/product-details/
Domain: Design High-Performing Architectures
33) A weather forecasting company comes up with the requirement of building a high-performance, highly parallel POSIX-compliant file system that stores data across multiple network file systems to serve thousands of simultaneous clients, driving millions of IOPS (Input/Output Operations per Second) with sub-millisecond latency. The company needs a cost-optimized file system storage for short-term, processing-heavy workloads that can provide burst throughput to meet this requirement.
What type of file systems storage will suit the company in the best way?
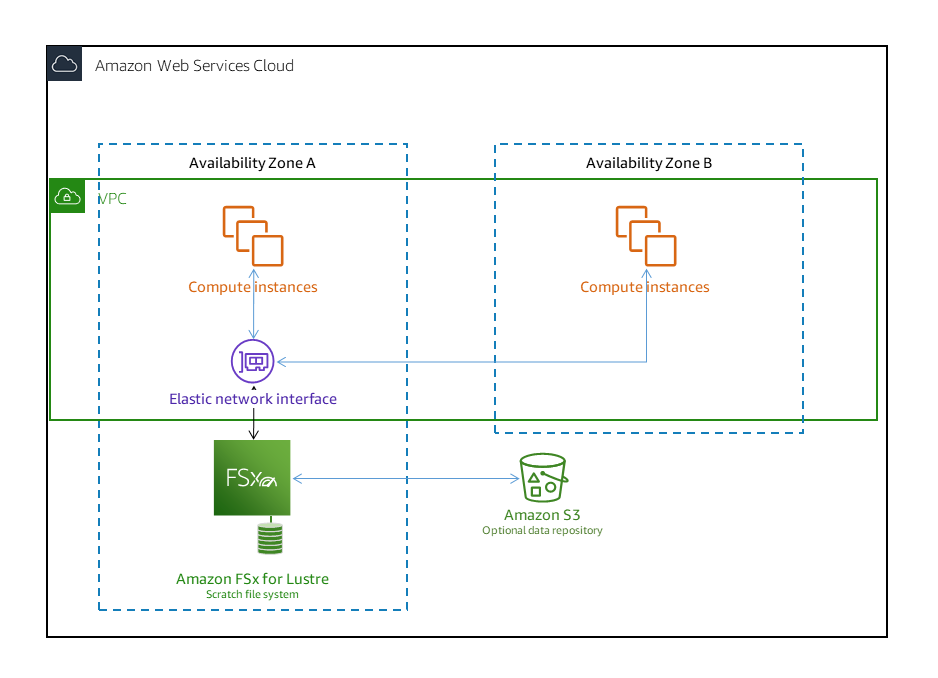
A. FSx for Lustre with Deployment Type as Scratch File System
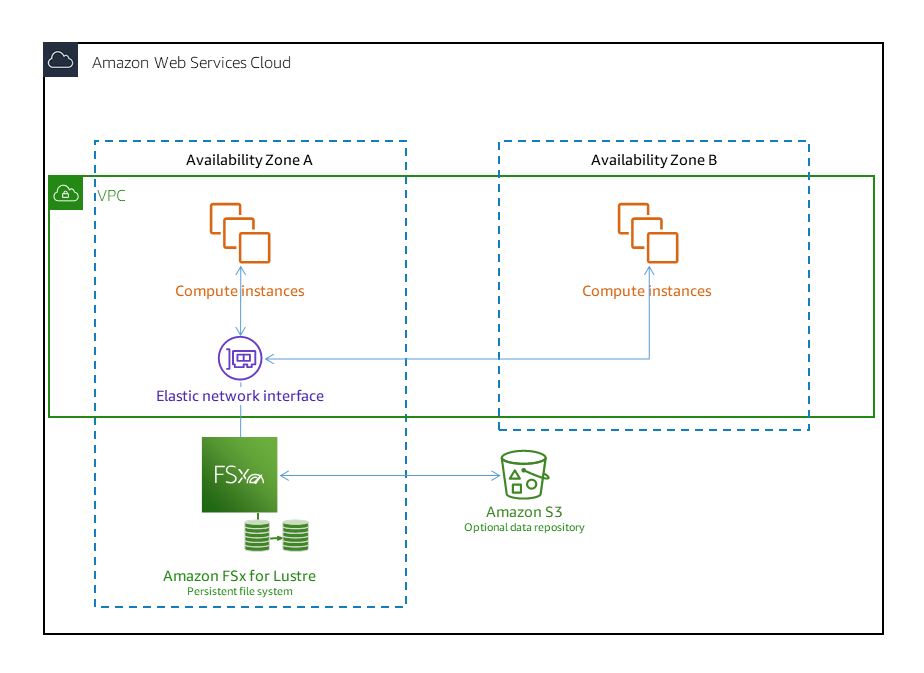
B. FSx for Lustre with Deployment Type as Persistent file systems
C. Amazon Elastic File System (Amazon EFS)
D. Amazon FSx for Windows File Server
Answer: A
Explanation
File system deployment options for FSx for Lustre:
Amazon FSx for Lustre provides two file system deployment options: scratch and persistent.
Both deployment options support solid-state drive (SSD) storage. However, hard disk drive (HDD) storage is supported only in one of the persistent deployment types.
You choose the file system deployment type when you create a new file system using the AWS Management Console, the AWS Command Line Interface (AWS CLI), or the Amazon FSx for Lustre API.
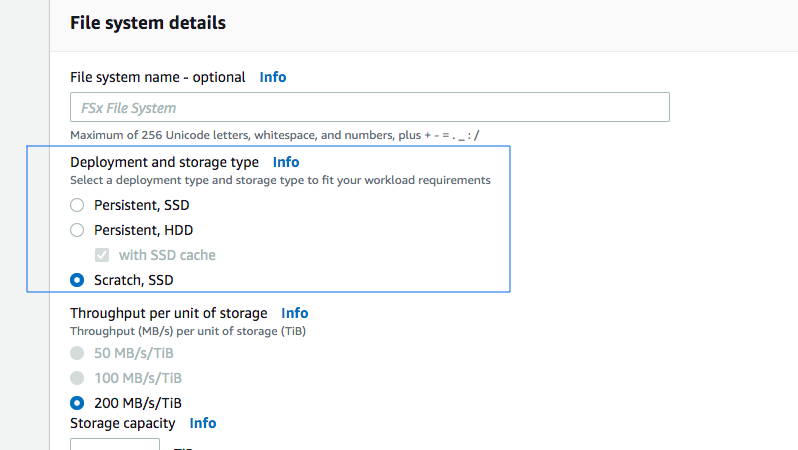
Option A is CORRECT because FSx for Lustre with Deployment Type as Scratch File System is designed for temporary storage and shorter-term data processing. Data isn’t replicated and doesn’t persist if a file server fails. Scratch file systems provide high burst throughput of up to six times the baseline throughput of 200 MBps per TiB storage capacity.
 Option B is incorrect because FSx for Lustre with Deployment Type as Persistent file systems are designed for longer-term storage and workloads. The file servers are highly available, and data is automatically replicated within the same Availability Zone in which the file system is located. The data volumes attached to the file servers are replicated independently from the file servers to which they are attached.
Option B is incorrect because FSx for Lustre with Deployment Type as Persistent file systems are designed for longer-term storage and workloads. The file servers are highly available, and data is automatically replicated within the same Availability Zone in which the file system is located. The data volumes attached to the file servers are replicated independently from the file servers to which they are attached.
 Option C is incorrect because Amazon EFS is not as effective as Amazon FSx for Luster when it comes to HPC design to deliver millions of IOPS (Input/Output Operations per Second) with sub-millisecond latency.
Option C is incorrect because Amazon EFS is not as effective as Amazon FSx for Luster when it comes to HPC design to deliver millions of IOPS (Input/Output Operations per Second) with sub-millisecond latency.
Option D is incorrect. The storage requirement here is for POSIX-compliant file systems to support Linux-based workloads. Hence Amazon FSx for Windows File Server is not suitable here.
Reference: https://docs.aws.amazon.com/fsx/latest/LustreGuide/using-fsx-lustre.html
Domain: Design Resilient Architectures
34) You are a solutions architect working for an online retailer. Your online website uses REST API calls via API Gateway and Lambda from your Angular SPA front-end to interact with your DynamoDB data store. Your DynamoDB tables are used for customer preferences, account, and product information. When your web traffic spikes, some requests return a 429 error response. What might be the reason your requests are returning a 429 response
A. Your Lambda function has exceeded the concurrency limit
B. DynamoDB concurrency limit has been exceeded
C. Your Angular service failed to connect to your API Gateway REST endpoint
D. Your Angular service cannot handle the volume spike
E. Your API Gateway has exceeded the steady-state request rate and burst limits
Answer: A & E
Explanation
Option A is correct. When your traffic spikes, your Lambda function can exceed the limit set on the number of concurrent instances that can be run (burst concurrency limit in the US: 3,000).
Option B is incorrect. When your table exceeds its provisioned throughput DynamoDB will return a 400 error to the requesting service, in this case, API Gateway. This will not result in the propagation of a 429 error response (too many requests) back to the Angular SPA service.
Option C is incorrect. If your Angular service fails to connect to your API Gateway REST endpoint your code will not generate a 429 error response (too many requests).
Option D is incorrect. Since your Angular SPA code runs in the individual user’s web browser, this option makes no sense.
Option E is correct. When your API Gateway request volume reaches the steady-state request rate and bursting limit, API Gateway throttles your requests to protect your back-end services. When these requests are throttled, API Gateway returns a 429 error response (too many requests).
Reference: Please see the Amazon API Gateway developer guide titled Throttle API requests for better throughput (https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html), the Towards Data Science article titled Full Stack Development Tutorial: Integrate AWS Lambda Serverless Service into Angular SPA (https://towardsdatascience.com/full-stack-development-tutorial-integrate-aws-lambda-serverless-service-into-angular-spa-abb70bcf417f), the Amazon API Gateway developer guide titled Invoking a REST API in Amazon API Gateway (https://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-call-api.html), the AWS Lambda developer guide titled Lambda function scaling (https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html), and the Amazon DynamoDB developer guide titled Error Handling with DynamoDB (https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.Errors.html)
Domain: Design High-Performing Architectures
35) You are a solutions architect working for a financial services firm. Your firm requires a very low latency response time for requests via API Gateway and Lambda integration to your securities master database. The securities master database, housed in Aurora, contains data about all of the securities your firm trades. The data consists of the security ticker, the trading exchange, trading partner firm for the security, etc. As this securities data is relatively static, you can improve the performance of your API Gateway REST endpoint by using API Gateway caching. Your REST API calls for equity security request types and fixed income security request types to be cached separately. Which of the following options is the most efficient way to separate your cache responses via request type using API Gateway caching?
A. Payload compression
B. Custom domain name
C. API Stage
D. Query string
Answer: D
Explanation
Option A is incorrect. Payload compression is used to compress and decompress the payload to and from your API Gateway. It is not used to separate cache responses.
Option B is incorrect. Custom domain names are used to provide more readable URLs for the users of your AIPs. They are not used to separate cache responses.
Option C is incorrect. An API stage is used to create a name for your API deployments. They are used to deploy your API in an optimal way.
Option D is correct. You can use your query string parameters as part of your cache key. This allows you to separate cache responses for equity requests from fixed income request responses.
References: Please see the Amazon API Gateway developer guide titled Enabling API caching to enhance responsiveness (https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-caching.html), the Amazon API Gateway REST API Reference page titled Making HTTP Requests to Amazon API Gateway (https://docs.aws.amazon.com/apigateway/api-reference/making-http-requests/), the Amazon API Gateway developer guide titled Enabling payload compression for an API (https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-gzip-compression-decompression.html), the Amazon API Gateway developer guide titled Setting up custom domain names for REST APIs (https://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-custom-domains.html), and the Amazon API Gateway developer guide titled Setting up a stage for a REST API (https://docs.aws.amazon.com/apigateway/latest/developerguide/set-up-stages.html)
Domain: Design Secure Applications and Architectures
36) You are a solutions architect working for a healthcare provider. Your company uses REST APIs to expose critical patient data to internal front-end systems used by doctors and nurses. The data for your patient information is stored in Aurora.
How can you ensure that your patient data REST endpoint is only accessed by your authorized internal users?
A. Run your Aurora DB cluster on an EC2 instance in a private subnet
B. Use a Gateway VPC Endpoint to make your REST endpoint private and only accessible from within your VPC
C. Use IAM resource policies to restrict access to your REST APIs by adding the aws:SourceVpce condition to the API Gateway resource policy
D. Use an Interface VPC Endpoint to make your REST endpoint private and only accessible from within your VPC and through your VPC endpoint
E. Use IAM resource policies to restrict access to your REST APIs by adding the aws:SourceArn condition to the API Gateway resource policy
Answer: C & D
Explanation
Option A is incorrect. Controlling access to your back-end database running on Aurora will not restrict access to your API Gateway REST endpoint. Access to your API Gateway REST endpoint must be controlled at the API Gateway and VPC level.
Option B is incorrect. The Gateway VPC Endpoint is only used for the S3 and DynamoDB services.
Option C is correct. You can make your REST APIs private by using the aws:SourceVpce condition in your API Gateway resource policy to restrict access to only your VPC Endpoint.
Option D is correct. Use a VPC Interface Endpoint to restrict access to your REST APIs to traffic that arrives via the VPC Endpoint.
Option E is incorrect. The aws:SourceArn condition key is not used to restrict access to traffic that arrives via the VPC Endpoint.
References: Please see the Amazon API Gateway developer guide titled Creating a private API in Amazon API Gateway (https://docs.aws.amazon.com/apigateway/latest/developerguide/apigateway-private-apis.html), the Amazon API Gateway developer guide titled Example: Allow private API traffic based on source VPC or VPC endpoint (https://docs.aws.amazon.com/apigateway/latest/developerguide/apigateway-resource-policies-examples.html#apigateway-resource-policies-source-vpc-example), the Amazon Aurora user guide titled Amazon Aurora security (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Security.html), the Amazon Aurora user guide titled Amazon Aurora DB clusters (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.html), the Amazon Aurora user guide titled Aurora DB instance classes (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html), the Amazon API Gateway developer guide titled AWS condition keys that can be used in API Gateway resource policies (https://docs.aws.amazon.com/apigateway/latest/developerguide/apigateway-resource-policies-aws-condition-keys.html), and the Amazon Virtual Private Cloud AWS PrivateLink page titled VPC endpoints (https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints.html)
Domain: Design Resilient Architectures
37) You are a solutions architect working for a data analytics company that delivers analytics data to politicians that need the data to manage their campaigns. Political campaigns use your company’s analytics data to decide on where to spend their campaign money to get the best results for the efforts. Your political campaign users access your analytics data through an Angular SPA via API Gateway REST endpoints. You need to manage the access and use of your analytics platform to ensure that the individual campaign data is separate. Specifically, you need to produce logs of all user requests and responses to those requests, including request payloads, response payloads, and error traces. Which type of AWS logging service should you use to achieve your goals?
A. Use CloudWatch access logging
B. Use CloudWatch execution logging
C. Use CloudTrail logging
D. Use CloudTrail execution logging
Answer: B
Explanation
Option A is incorrect. CloudWatch access logging captures which resource accessed an API and the method used to access the API. It is not used for execution traces, such as capturing request and response payloads.
Option B is correct. CloudWatch execution logging allows you to capture user request and response payloads as well as error traces.
Option C is incorrect. CloudTrail captures actions by users, roles, and AWS services. CloudTrail records all AWS account activity. CloudTrail does not capture error traces.
Option D is incorrect. CloudTrail does not have a feature called execution logging.
References: Please see the Amazon API Gateway developer guide titled Setting up CloudWatch logging for a REST API in API Gateway (https://docs.aws.amazon.com/apigateway/latest/developerguide/set-up-logging.html), and the AWS CloudTrail user guide titled How CloudTrail works (https://docs.aws.amazon.com/awscloudtrail/latest/userguide/how-cloudtrail-works.html)
Domain: Design Secure Applications and Architectures
38) You are a solutions architect working for a social media company that provides a place for civil discussion of political and news-related events. Due to the ever-changing regulatory requirements and restrictions placed on social media apps that provide these services, you need to build your app in an environment where you can change your implementation instantly without updating code. You have chosen to build the REST API endpoints used by your social media app user interface code using Lambda. How can you securely configure your Lambda functions without updating code?
A. Pass environment variables to your Lambda function via the request header sent to your API Gateway methods
B. Configure your Lambda functions to use key configuration
C. Use encryption helpers
D. Use Lambda layers
E. Use Lambda aliases
Answer: B & C
Explanation
Option A is incorrect. Sending environment variables to your Lambda function as request parameters would expose the environment variables as plain text. This is not a secure approach.
Option B is correct. Lambda key configuration allows you to have your Lambda functions use an encryption key. You create the key in AWS KMS. The key is used to encrypt the environment variables that you can use to change your function without deploying any code.
Option C is correct. Encryption helpers make your lambda function more secure by allowing you to encrypt your environment variables before they are sent to Lambda.
Option D is incorrect. Lambda layers are used to package common code such as libraries, configuration files, or custom runtime images. Layers will not give you the same flexibility as environment variables for use in managing change without deploying any code.
Option E is incorrect. Lambda aliases are used to refer to a specific version of your Lambda function. You could switch between many versions of your Lambda function, but you would have to deploy new code to create a different version of your Lambda function.
References: Please see the AWS Lambda developer guide titled Data protection in AWS Lambda (https://docs.aws.amazon.com/lambda/latest/dg/security-dataprotection.html), the AWS Lambda developer guide titled Lambda concepts (https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-concepts.html#gettingstarted-concepts-layer), the AWS Lambda developer guide titled Lambda function aliases (https://docs.aws.amazon.com/lambda/latest/dg/configuration-aliases.html), and the AWS Lambda developer guide titled Using AWS Lambda environment variables (https://docs.aws.amazon.com/lambda/latest/dg/configuration-envvars.html)
Domain: Design Secure Applications and Architectures
39) You are a solutions architect working for a media company that produces stock images and videos for sale via a mobile app and website. Your app and website allow users to gain access only to stock content they have purchased. Your content is stored in S3 buckets. You need to restrict access to multiple files that your users have purchased. Also, due to the nature of the stock content (purchasable by multiple users), you don’t want to change the URLs of each stock item.
Which access control option best fits your scenario?
A. Use CloudFront signed URLs
B. Use S3 Presigned URLs
C. Use CloudFront Signed Cookies
D. Use S3 Signed Cookies
Answer: C
Explanation
Option A is incorrect. CloudFront signed URLs allow you to restrict access to individual files. It requires you to change your content URLs for each customer access.
Option B is incorrect. S3 Presigned URLs require you to change your content URLs. The presigned URL expires after its defined expiration date.
Option C is correct. CloudFront Signed Cookies allow you to control access to multiple content files and you don’t have to change your URL for each customer access.
Option D is incorrect. There is no S3 Signed Cookies feature.
References: Please see the Amazon CloudFront developer guide titled Using signed cookies (https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-signed-cookies.html), the Amazon Simple Storage Service user guide titled Sharing an object with a presigned URL (https://docs.aws.amazon.com/AmazonS3/latest/userguide/ShareObjectPreSignedURL.html), the Amazon Simple Storage Service user guide titled Using presigned URLs (https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-presigned-url.html#PresignedUrlUploadObject-LimitCapabilities), and the Amazon CloudFront developer guide titled Choosing between signed URLs and signed cookies (https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-choosing-signed-urls-cookies.html)
Domain : Design High-Performing Architectures
40) A company is developing a web application to be hosted in AWS. This application needs a data store for session data.
As an AWS Solution Architect, what would you recommend as an ideal option to store session data?
A. CloudWatch
B. DynamoDB
C. Elastic Load Balancing
D. ElastiCache
E. Storage Gateway
Answer: B & D
Explanation
DynamoDB and ElastiCache are perfect options for storing session data.
AWS Documentation mentions the following on Amazon DynamoDB:
Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. It is a fully managed cloud database and supports both document and key-value store models. Its flexible data model, reliable performance, and automatic scaling of throughput capacity make it a great fit for mobile, web, gaming, ad tech, IoT, and many other applications.
For more information on AWS DynamoDB, please visit the following URL: https://aws.amazon.com/dynamodb/
AWS Documentation mentions the following on AWS ElastiCache:
AWS ElastiCache is a web service that makes it easy to set up, manage, and scale a distributed in-memory data store or cache environment in the cloud. It provides a high-performance, scalable, and cost-effective caching solution while removing the complexity associated with the deployment and management of a distributed cache environment.
For more information on AWS Elasticache, please visit the following URL: https://docs.aws.amazon.com/AmazonElastiCache/latest/UserGuide/WhatIs.html
Option A is incorrect. AWS CloudWatch offers cloud monitoring services for the customers of AWS resources.
Option C is incorrect. AWS Elastic Load Balancing automatically distributes incoming application traffic across multiple targets.
Option E is incorrect. AWS Storage Gateway is a hybrid storage service that enables your on-premises applications to use AWS cloud storage seamlessly.
Domain : Design High-Performing Architectures
41) You are creating a new architecture for a financial firm. The architecture consists of some EC2 instances with the same type and size (M5.large). In this architecture, all the EC2 mostly communicate with each other. Business people have asked you to create this architecture keeping in mind low latency as a priority. Which placement group option could you suggest for the instances?
A. Partition Placement Group
B. Clustered Placement Group
C. Spread Placement Group
D. Enhanced Networking Placement Group
Answer: B
Explanation
Option A is incorrect. Partition Placement Groups distribute the instances in different partitions. The partitions are placed in the same AZ, but do not share the same rack. This type of placement group does not provide low latency throughput to the instances.
Option B is CORRECT. Clustered Placement Group places all the instances on the same rack. This placement group option provides 10 Gbps connectivity between instances ( Internet connectivity in the instances has a maximum of 5 Gbps). This option of placement group is perfect for the workload that needs low latency.
Option C is incorrect. Placement Groups place all the instances in different racks in the same AZ. These types of placement groups do not provide low latency throughput to the instances.
Option D is incorrect. Enhanced Networking Placement Group does not exist.
Reference: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Domain : Design High-Performing Architectures
42) Your team is developing a high-performance computing (HPC) application. The application resolves complex, compute-intensive problems and needs a high-performance and low-latency Lustre file system. You need to configure this file system in AWS at a low cost. Which method is the most suitable?
A. Create a Lustre file system through Amazon FSx
B. Launch a high performance Lustre file system in Amazon EBS
C. Create a high-speed volume cluster in EC2 placement group
D. Launch the Lustre file system from AWS Marketplace
Answer: A
Explanation
The Lustre file system is an open-source, parallel file system that can be used for HPC applications. Refer to http://lustre.org/ for its introduction. In Amazon FSx, users can quickly launch a Lustre file system at a low cost.
Option A is CORRECT: Amazon FSx supports Lustre file systems, and users pay for only the resources they use.
Option B is incorrect: Although users may be able to configure a Lustre file system through EBS, it needs lots of extra configurations. Option A is more straightforward.
Option C is incorrect: Because the EC2 placement group does not support a Lustre file system.
Option D is incorrect: Because products in AWS Marketplace are not cost-effective. For Amazon FSx, there are no minimum fees or set-up charges. Check its pricing in
Reference: https://aws.amazon.com/fsx/lustre/pricing/.
Domain : Design High-Performing Architectures
43) A company has an application hosted in AWS. This application consists of EC2 Instances that sit behind an ELB. The following are the requirements from an administrative perspective:
a) Ensure that notifications are sent when the read requests go beyond 1000 requests per minute.
b) Ensure that notifications are sent when the latency goes beyond 10 seconds.
c) Monitor all AWS API request activities on the AWS resources.
Which of the following can be used to satisfy these requirements?
A. Use CloudTrail to monitor the API Activity
B. Use CloudWatch Logs to monitor the API Activity
C. Use CloudWatch Metrics for the metrics that need to be monitored as per the requirement and set up an alarm activity to send out notifications when the metric reaches the set threshold limit
D. Use custom log software to monitor the latency and read requests to the ELB
Answer: A & C
Explanation
Option A is correct. CloudTrail is a web service that records AWS API calls for all the resources in your AWS account. It also delivers log files to an Amazon S3 bucket. The recorded information includes the identity of the user, the start time of the AWS API call, the source IP address, the request parameters, and the response elements returned by the service.
Option B is incorrect because CloudWatch Logs can be used to monitor log files from other services. CloudWatch Logs and CloudWatch are different.
Amazon CloudWatch Logs are used to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources. CloudWatch Logs reports the data to a CloudWatch metric.
Rather you can monitor Amazon EC2 API requests using Amazon CloudWatch.
Option C is correct. Use Cloudwatch Metrics for the metrics that need to be monitored as per the requirement. Set up an alarm activity to send out notifications when the metric reaches the set threshold limit.
Option D is incorrect because there is no need to use custom log software as you can set up CloudWatch alarms based on CloudWatch Metrics.
References: https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html, https://docs.aws.amazon.com/awscloudtrail/latest/APIReference/Welcome.html, https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-cloudwatch-metrics.html
Domain : Design Resilient Architectures
44) You are creating several EC2 instances for a new application. The instances need to communicate with each other. For a better performance of the application, both low network latency and high network throughput are required for the EC2 instances. All instances should be launched in a single availability zone. How would you configure this?
A. Launch all EC2 instances in a placement group using a Cluster placement strategy
B. Auto assign a public IP when launching the EC2 instances
C. Launch EC2 instances in an EC2 placement group and select the Spread placement strategy
D. When launching the EC2 instances, select an instance type that supports enhanced networking
Answer: A
Explanation
The Cluster placement strategy helps to achieve a low-latency and high throughput network.
Option A is CORRECT: The Cluster placement strategy can improve the network performance among EC2 instances. The strategy can be selected when creating a placement group.
 Option B is incorrect: Because the public IP cannot improve the network performance.
Option B is incorrect: Because the public IP cannot improve the network performance.
Option C is incorrect: The Spread placement strategy is recommended when several critical instances should be kept separate from each other. This strategy should not be used in this scenario.
Option D is incorrect: The description in the option is inaccurate. The correct method is creating a placement group with a suitable placement strategy.
Domain : Design High-Performing Architectures
45) You are a solutions architect working for a regional bank that is moving its data center to the AWS cloud. You need to migrate your data center storage to a new S3 and EFS data store in AWS. Since your data includes Personally Identifiable Information (PII), you have been asked to transfer data from your data center to AWS without traveling over the public internet. Which option gives you the most efficient solution that meets your requirements?
A. Migrate your on-prem data to AWS using the DataSync agent using NAT Gateway
B. Create a public VPC endpoint, and configure the DataSync agent to communicate to the DataSync public service endpoints via the VPC endpoint using Direct Connect
C. Migrate your on-prem data to AWS using the DataSync agent using Internet Gateway
D. Create a private VPC endpoint, and configure the DataSync agent to communicate to the DataSync private service endpoints via the VPC endpoint using VPN
Answer: D
Explanation
AWs documentation mentions the following:
While configuring this setup, you’ll place a private VPC endpoint in your VPC that connects to the DataSync service. This endpoint will be used for communication between your agent and the DataSync service.
In addition, for each transfer task, four elastic network interfaces (ENIs) will automatically get placed in your VPC. DataSync agent will send traffic through these ENIs in order to transfer data from your on-premises shares into AWS.
“When you use DataSync with a private VPC endpoint, the DataSync agent can communicate directly with AWS without the need to cross the public internet.“
Option A is incorrect. To ensure your data isn’t sent over the public internet, you need to use a VPC endpoint to connect the DataSync agent to the DataSync service endpoints.
Option B is incorrect. You need to use a private VPC endpoint, not the public VPC endpoint to keep your data away from traveling over the public internet.
Option C is incorrect. Using the Internet Gateway by definition sends your traffic over the public internet, which is the solution as per the requirement.
Option D is correct. Using a private VPC endpoint and the DataSync private service endpoints to communicate over your VPN will give you the non-internet transfer you require.
References: Please see the AWS DataSync user guide titled Using AWS DataSync in a virtual private cloud (https://docs.aws.amazon.com/datasync/latest/userguide/datasync-in-vpc.html), and the AWS Storage Blog titled Transferring files from on-premises to AWS and back without leaving your VPC using AWS DataSync (https://aws.amazon.com/blogs/storage/transferring-files-from-on-premises-to-aws-and-back-without-leaving-your-vpc-using-aws-datasync/)
Domain : Design Resilient Architectures
46) You currently have your EC2 instances running in multiple availability zones in an AWS region. You need to create NAT gateways for your private instances to access internet. How would you set up the NAT gateways so that they are highly available?
A. Create two NAT Gateways and place them behind an ELB
B. Create a NAT Gateway in each Availability Zone
C. Create a NAT Gateway in another region
D. Use Auto Scaling groups to scale the NAT Gateways
Answer: B
Explanation
Option A is incorrect because you cannot create such configurations.
Option B is CORRECT because this is recommended by AWS. With this option, if a NAT gateway’s Availability Zone is down, resources in other Availability Zones can still access internet.
Option C is incorrect because the EC2 instances are in one AWS region so there is no need to create a NAT Gateway in another region.
Option D is incorrect because you cannot create an Auto Scaling group for NAT Gateways.
For more information on the NAT Gateway, please refer to the below URL: https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/vpc-nat-gateway.html
Domain : Design Secure Architectures
47) Your company has designed an app and requires it to store data in DynamoDB. The company has registered the app with identity providers for users to sign-in using third-parties like Google and Facebook. What must be in place such that the app can obtain temporary credentials to access DynamoDB?
A. Multi-factor authentication must be used to access DynamoDB
B. AWS CloudTrail needs to be enabled to audit usage
C. An IAM role allowing the app to have access to DynamoDB
D. The user must additionally log into the AWS console to gain database access
Answer: C
Explanation
Option C is correct. The user will have to assume a role that has the permissions to interact with DynamoDB.
Option A is incorrect. Multi-factor authentication is available but not required.
Option B is incorrect. CloudTrail is recommended for auditing but is not required.
Option D is incorrect. A second log-in event to the management console is not required.
References: https://docs.aws.amazon.com/cognito/latest/developerguide/cognito-user-pools-identity-federation.html, https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_oidc.html, https://aws.amazon.com/articles/web-identity-federation-with-mobile-applications/
Domain : Design High-Performing Architectures
48) A company has a lot of data hosted on their On-premises infrastructure. Running out of storage space, the company wants a quick win solution using AWS. There should be low latency for the frequently accessed data. Which of the following would allow the easy extension of their data infrastructure to AWS?
A. The company could start using Gateway Cached Volumes
B. The company could start using Gateway Stored Volumes
C. The company could start using the Amazon S3 Glacier Deep Archive storage class
D. The company could start using Amazon S3 Glacier
Answer: A
Explanation
Volume Gateways and Cached Volumes can be used to start storing data in S3.
AWS Documentation mentions the following:
You store your data in Amazon Simple Storage Service (Amazon S3) and retain a copy of frequently accessed data subsets locally. Cached volumes offer substantial cost savings on primary storage and minimize the need to scale your storage on-premises. You also retain low-latency access to your frequently accessed data.
This is the difference between Cached and stored volumes:
- Cached volumes – You store your data in S3 and retain a copy of frequently accessed data subsets locally. Cached volumes offer substantial cost savings on primary storage and “minimize the need to scale your storage on-premises. You also retain low-latency access to your frequently accessed data.”
- Stored volumes – If you need low-latency access to your entire data set, first configure your on-premises gateway to store all your data locally. Then asynchronously back up point-in-time snapshots of this data to Amazon S3. “This configuration provides durable and inexpensive off-site backups that you can recover to your local data center or Amazon EC2.” For example, if you need replacement capacity for disaster recovery, you can recover the backups to Amazon EC2.
As described in the answer: The company wants a quick win solution to store data with AWS, avoiding scaling the on-premise setup rather than backing up the data.
In the question, they mentioned that “A company has a lot of data hosted on their On-premises infrastructure.” From On-premises to cloud infrastructure, you can use AWS storage gateways.
Options C and D are incorrect as they are talking about the S3 storage classes, but the requirement is (How) to transfer or migrate your data from On-premises to Cloud infrastructure.
Reference: https://docs.aws.amazon.com/storagegateway/latest/userguide/WhatIsStorageGateway.html
Domain : Design Secure Architectures
49) A start-up firm has a corporate office in New York & a regional office in Washington & Chicago. These offices are interconnected over Internet links. Recently they have migrated a few application servers to EC2 instance launched in the AWS US-east-1 region. The Developer Team located at the corporate office requires secure access to these servers for initial testing & performance checks before go-live of the new application. Since the go-live date is approaching soon, the IT team is looking for quick connectivity to be established. As an AWS consultant, which link option will you suggest as a cost-effective & quick way to establish secure connectivity from on-premise to servers launched in AWS?
A. Use AWS Direct Connect to establish IPSEC connectivity from On-premise to VGW
B. Install a third party software VPN appliance from AWS Marketplace in the EC2 instance to create a VPN connection to the on-premises network
C. Use Hardware VPN over AWS Direct Connect to establish IPSEC connectivity from On-premise to VGW
D. Use AWS Site-to-Site VPN to establish IPSEC VPN connectivity between VPC and the on-premises network
Answer: D
Explanation
Using AWS VPN is the fastest & cost-effective way of establishing IPSEC connectivity from on-premise to AWS. IT teams can quickly set up a VPN connection with VGW in the US-east-1 region so that internal users can seamlessly connect to resources hosted on AWS.
Option A is incorrect as AWS Direct Connect does not provide IPSEC connectivity. It is not a quick way to establish connectivity.
Option B is incorrect as you need to look for a third party solution from AWS Marketplace. And it may not be as cost-efficient as option D.
Option C is incorrect as although this will provide a high performance secure IPSEC connectivity from On-premise to AWS, it is not a quick way to establish connectivity. It may take weeks or months to configure the AWS Direct Connect connection. AWS Direct Connect is also not cost-effective.
For more information on using AWS Direct Connect & VPN, refer to the following URL: https://docs.aws.amazon.com/whitepapers/latest/aws-vpc-connectivity-options/network-to-amazon-vpc-connectivity-options.html
Domain : Design Cost-Optimized Architectures
50) A Media firm is saving all its old videos in S3 Glacier Deep Archive. Due to the shortage of new video footage, the channel has decided to reuse all these old videos. Since these are old videos, the channel is not sure of their popularity & response from users. Channel Head wants to make sure that these huge size files do not shoot up their budget. For this, as an AWS consultant, you advise them to use the S3 intelligent storage class. The Operations Team is concerned about moving these files to the S3 Intelligent-Tiering storage class. Which of the following actions can be taken to move objects in Amazon S3 Glacier Deep Archive to the S3 Intelligent-Tiering storage class?
A. Use Amazon S3 Console to copy these objects from S3 Glacier Deep Archive to the required S3 Intelligent-Tiering storage class
B. Use Amazon S3 Glacier Console to restore objects from S3 Glacier Deep Archive & then copy these objects to the required S3 Intelligent-Tiering storage class
C. Use Amazon S3 console to restore objects from S3 Glacier Deep Archive & then copy these objects to the required S3 Intelligent-Tiering storage class
D. Use the Amazon S3 Glacier console to copy these objects to the required S3 Intelligent-Tiering storage class
Answer: C
Explanation
To move objects from Glacier Deep Archive to different storage classes, first, need to restore them to original locations using the Amazon S3 console & then use the lifecycle policy to move objects to the required S3 Intelligent-Tiering storage class.
Options A & D are incorrect as Objects in Glacier Deep Archive cannot be directly moved to another storage class. These need to be restored first & then copied to the desired storage class.
Option B is incorrect as the Amazon S3 Glacier console can be used to access the vaults and objects in them. But it cannot be used to restore the objects.
For more information on moving objects between S3 storage classes, refer to the following URL: https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Domain : Design Cost-Optimized Architectures
51) You are building an automated transcription service where Amazon EC2 worker instances process an uploaded audio file and generate a text file. You must store both of these files in the same durable storage until the text file is retrieved. Customers fetch the text files frequently. You do not know about the storage capacity requirements. Which storage option would be both cost-efficient and highly available in this situation?
A. Multiple Amazon EBS Volume with snapshots
B. A single Amazon Glacier Vault
C. A single Amazon S3 bucket
D. Multiple instance stores
Answer: C
Explanation
Amazon S3 is the perfect storage solution for audio and text files. It is a highly available and durable storage device.
Option A is incorrect because storing files in EBS is not cost-efficient.
Option B is incorrect because files need to be retrieved frequently so Glacier is not suitable.
Option D is incorrect because the instance store is not highly available compared with S3.
For more information on Amazon S3, please visit the following URL: https://aws.amazon.com/s3/
Domain : Design Cost-Optimized Architectures
52) A large amount of structured data is stored in Amazon S3 using the JSON format. You need to use a service to analyze the S3 data directly with standard SQL. In the meantime, the data should be easily visualized through data dashboards. Which of the following services is the most appropriate?
A. Amazon Athena and Amazon QuickSight
B. AWS Glue and Amazon Athena
C. AWS Glue and Amazon QuickSight
D. Amazon Kinesis Data Stream and Amazon QuickSight
Answer: A
Explanation
Option A is CORRECT because Amazon Athena is the most suitable to run ad-hoc queries to analyze data in S3. Amazon Athena is serverless, and you are charged for the amount of scanned data. Besides, Athena can integrate with Amazon QuickSight that visualizes the data via dashboards.
Option B is incorrect because AWS Glue is an ETL (extract, transform, and load) service that organizes, cleanses, validates, and formats data in a data warehouse. This service is not required in this scenario.
Option C is incorrect because it is the same as Option B. AWS Glue is not required.
Option D is incorrect because, with Amazon Kinesis Data Stream, users cannot perform queries for the S3 data through standard SQL.
References: https://aws.amazon.com/athena/pricing/. https://docs.aws.amazon.com/quicksight/latest/user/create-a-data-set-athena.html.
Domain : Design Cost-Optimized Architectures
53) To manage a large number of AWS accounts in a better way, you create a new AWS Organization and invite multiple accounts. You only enable the “Consolidated billing” out of the two feature sets (All features and Consolidated billing) available in the AWS Organizations. Which of the following is the primary benefit of using Consolidated billing feature?
A. Apply SCPs to restrict the services that IAM users can access
B. Configure tag policies to maintain consistent tags for resources in the organization’s accounts
C. Configure a policy to prevent IAM users in the organization from disabling AWS CloudTrail
D. Combine the usage across all accounts to share the volume pricing discounts
Answer: D
Explanation
Available feature sets in AWS Organizations:
- All features – The default feature set that is available to AWS Organizations. It includes all the functionality of consolidated billing, plus advanced features that give you more control over accounts in your organization.
- Consolidated billing – This feature set provides shared billing functionality but does not include the more advanced features of AWS Organizations.
Option A is incorrect: Because SCP is part of the advanced features which belong to “All features”.
Option B is incorrect: Because tag policies can be applied under the feature set of “All features”.
Option C is incorrect: This is implemented using SCP which is not supported in “Consolidated billing”.
Option D is CORRECT: ‘Consolidated billing’ feature set provides shared billing functionality.
For the differences between “Consolidated billing” and “All features”, refer to the reference below: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_getting-started_concepts.html#feature-set-cb-only
Domain : Design Cost-Optimized Architectures
54) A large manufacturing company is looking to track IoT sensor data collected from thousands of equipment across multiple factory units. This is extremely high-volume traffic that needs to be collected in real-time and should be efficiently visualized. The company is looking for a suitable database in the AWS cloud for storing these sensor data.
Which of the following cost-effective databases can be selected for this purpose?
A. Send sensor data to Amazon RDS (Relational Database Service) using Amazon Kinesis and visualized data using Amazon QuickSight.
B. Send sensor data to Amazon Neptune using Amazon Kinesis and visualized data using Amazon QuickSight.
C. Send sensor data to Amazon DynamoDB using Amazon Kinesis and visualized data using Amazon QuickSight.
D. Send sensor data to Amazon Timestream using Amazon Kinesis and visualized data using Amazon QuickSight.
Answer: D
Explanation
Amazon Timestream is the most suitable serverless time series database for IoT and operational services. It can store trillions of events from these sources. Storing this time series data in Amazon Timestream ensures faster processing and is more cost-effective than storing such data in a regular relational database.
Amazon Timestream is integrated with data collection services in AWS such as Amazon Kinesis, and Amazon MSK, and open-source tools such as Telegraf. Data stored in Amazon Timestream can be further visualized using Amazon QuickSight. It can also be integrated with Amazon Sagemaker for machine learning.
Option A is incorrect as Amazon RDS (Relational Database Service) is best suited for traditional applications such as CRM (customer relationship management) and ERP (Enterprise resource planning). Using Amazon RDS for storing IoT sensor data will be costly and slow as compared to the Amazon Timestream.
Option B is incorrect as Amazon Neptune is suitable for creating graph databases querying large amounts of data. Amazon Neptune is not a suitable option for storing IoT sensor data.
Option C is incorrect as Amazon DynamoDB is suitable for web applications supporting key-value NoSQL databases. Using Amazon DynamoDB for storing IoT sensor data will be costly.
For more information on Amazon Timestream, refer to the following URLs,
https://aws.amazon.com/products/databases/
https://aws.amazon.com/timestream/features/?nc=sn&loc=2
Latest Updated Questions 2023
Domain: Design High-Performing Architectures
55) A start-up firm is using a JSON-based database for content management. They are planning to rehost this database to AWS Cloud from on-premises. For this, they are looking for a suitable option to deploy this database, which can handle millions of requests per second with low latency. Databases should have a flexible schema that can store any type of user data from multiple sources and should effectively process similar data stored in different formats.
Which of the following databases can be selected to meet the requirements?
A. Use Amazon DocumentDB (with MongoDB compatibility) in the AWS cloud to rehost the database from an on-premises location.
B. Use Amazon Neptune in the AWS cloud to rehost the database from an on-premises location.
C. Use Amazon Timestream in AWS cloud to rehost database from an on-premises location.
D. Use Amazon Keyspaces in AWS cloud to rehost database from an on-premises location.
Answer: A
Explanation
Amazon DocumentDB is a fully managed database that supports JSON workloads for content management in the AWS cloud. Amazon DocumentDB supports millions of requests per second with low latency. Amazon DocumentDB has a flexible schema that can store data in different attributes and data values. Due to the flexible schema, it’s best suited for content management which allows users to store different data types such as images, videos, and comments.
With relational databases, for storing different documents, separate tables are required to store different types of documents or need a single table with unused fields as null values. Amazon DocumentDB is a semi-structured database that supports different formats of the documents in the same document without null values.
Option B is incorrect as Amazon Neptune is suitable for creating graph databases querying large amounts of data. It is not a suitable option for content management with different data formats.
Option C is incorrect as Amazon Timestream is suitable for time series databases such as IoT base sensor data, DevOps, or clickstream data. It is not a suitable option for content management with different data formats.
Option D is incorrect as Amazon Keyspaces is a highly available and scalable database supporting Apache Cassandra. It is not a suitable option for content management with different data formats.
For more information on the features of Amazon DocumentDB, refer to the following URLs,
https://aws.amazon.com/documentdb/features/
https://aws.amazon.com/products/databases/
https://docs.aws.amazon.com/documentdb/latest/developerguide/document-database-use-cases.html
Domain: Design High-Performing Architectures
56). A start-up firm has created account A using the Amazon RDS DB instance as a database for a web application. The operations team regularly creates manual snapshots for this DB instance in unencrypted format. The Projects Team plans to create a DB instance in other accounts using these snapshots. They are looking for your suggestion for sharing this snapshot and restoring it to DB instances in other accounts. While sharing this snapshot, it must allow only specific accounts specified by the project teams to restore DB instances from the snapshot.
What actions can be initiated for this purpose?
A. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private. In other Accounts, directly restore to DB instances from the snapshot.
B. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as public. In other Accounts, directly restore to DB instances from the snapshot.
C. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private. In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that copy.
D. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibilityoption as public. In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that copy.
Correct Answer : A
Explanation
DB snapshot can be shared with other authorized AWS accounts which can be up to 20 accounts. These snapshots can be either in encrypted or unencrypted format.
For manual snapshots in an unencrypted format, accounts can directly restore a DB instance from the snapshot.
For manual snapshots in an encrypted format, accounts first need to copy the snapshot and then restore it to a DB instance.
While sharing a manual unencrypted snapshot, all accounts can use this snapshot to restore to the DB instance when DB snapshot visibility is set to public.
While sharing a manual unencrypted snapshot, only specified accounts can restore a DB instance when DB snapshot visibility is set to private.
In the case of manual encrypted snapshots, the only available option for DB snapshot visibility is private, as encrypted snapshots cannot be made public.
Option B is incorrect as marking DB snapshot visibility as the public is not an ideal option since snapshots need to share only with specific accounts. Marking DB snapshot visibility as public will provide all Amazon accounts access to the manual snapshot and will be able to restore DB instances using this snapshot.
Option C is incorrect as DB instances can be directly restored from the snapshot for a manual unencrypted snapshot. There is no need to create a copy of the snapshot to restore a DB instance.
Option D is incorrect as already discussed, marking DB snapshot visibility as the public is not an ideal option. For a manual unencrypted snapshot, DB instances can be directly restored from the snapshot.
For more information on sharing Amazon RDS snapshots, refer to the following URLs,
https://aws.amazon.com/premiumsupport/knowledge-center/rds-snapshots-share-account/
https://docs.amazonaws.cn/en_us/AmazonRDS/latest/UserGuide/USER_ShareSnapshot.html
Domain: Design Resilient Architectures
57). An electronic manufacturing company plans to deploy a web application using the Amazon Aurora database. The Management is concerned about the disk failures with DB instances and needs your advice for increasing reliability using Amazon Aurora automatic features. In the event of disk failures, data loss should be avoided, reducing additional work to perform from the point-in-time restoration.
What design suggestions can be provided to increase reliability?
A. Add Aurora Replicas to primary DB instances by placing them in different regions. Aurora’s crash recovery feature will avoid data loss post disk failure.
B. Add Aurora Replicas to primary DB instances by placing them in different availability zones. Aurora storage auto-repair feature will avoid data loss post disk failure.
C. Add Aurora Replicas to the primary DB instance by placing them in different regions. Aurora Survivable page cache feature will avoid data loss post disk failure.
D. Add Aurora Replicas to the primary DB instance by placing them in different availability zones. Aurora’s crash recovery feature will avoid data loss post disk failure.
Correct Answer : B
Explanation
Amazon Aurora Database reliability can be increased by adding Aurora Replicas to the primary DB instance and placing them in different Availability zones. Each of the DB clusters can have a primary DB instance and up to 15 Aurora Replicas. In case of primary DB instance failure, Aurora automatically fails over to replicas. Amazon Aurora also uses the following automatic features to enhance reliability,
- Storage auto-repair: Aurora maintains multiple copies of the data in three different Availability zones. This helps in avoiding data loss post disk failure. If any segment of the disk fails, Aurora automatically recovers data on the segment by using data stored in other cluster volumes. This reduces additional work to perform point-in-time restoration post disk failure.
- Survivable page cache: Manage page cache in a separate process than the database. In the event of database failure, the page cache is stored in the memory. Post restarting the database, applications continue to read data from the page cache providing performance gain.
- Crash recovery: Crash recovery can be used for faster recovery post any crash in the database. With the crash recovery feature, Amazon Aurora performs recovery asynchronously on parallel threads enabling applications to read data from the database without binary logs.
Option A is incorrect. Aurora Replicas should be created in different Availability zones and not in different regions for better availability. The crash recovery does not minimize data loss post disk failures.
Option C is incorrect. The Survivable page cache feature provides performance gains but does not minimize data loss post disk failures. Aurora Replicas should be created in different Availability zones and not in different regions.
Option D is incorrect as the crash recovery feature does not minimize data loss post disk failures.
For more information on Amazon Aurora reliability features, refer to the following URL,
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.StorageReliability.html
Domain: Design Cost-Optimized Architectures
58). A financial institute has deployed a critical web application in the AWS cloud. The management team is looking for a resilient solution with RTO/RPO in ten minutes during a disaster. They have budget concerns, and the cost of provisioning the backup infrastructure should not be very high. As a solution architect, you have been assigned to work on setting a resilient solution meeting the RTO/RPO requirements within the cost constraints.
Which strategy is suited perfectly?
A. Multi-Site Active/Active
B. Warm Standby
C. Backup & Restore
D. Pilot Light
Correct Answer : D
Explanation
RTO (Recovery Time Objective) is a period for which downtime is observed post-disaster. It’s the time between the disaster and application recovery to serve full workloads. RPO (Recovery Point Objective) defines the amount of data loss during a disaster. It measures the time window when the last backup was performed, and the time when the disaster happened. Various Disaster recovery solutions can be deployed based on RTO/RPO and budget requirements for critical applications.
The following are options available with Disaster recovery,
- Backup and Restore: Least expensive among all the options but RTO/RPO will be very high in hours. All backup resources will be initiated only after a disaster at the primary location.
- Pilot Light: Less expensive than warm standby and multi-site active/active. RTO/RPO happens in tens of minutes.
In this strategy, a minimum number of active resources are deployed at the backup locations. Resources required for data synchronization between primary and backup locations are only provisioned and are active. Other components such as application servers are switched off and are provisioned post a disaster at the primary location. In the above scenario, Pilot Light is the most suitable option to meet RTO/RPO requirements on a low budget.
- Warm Standby: Expensive Than Pilot Light. RPO/RTO happens in minutes. The application is running at the backup location on scaled-down resource capacity. Once a disaster occurs at the primary location, all the resources are scaled up to meet the desired workload.
- Multi-site active/active: Most expensive. No downtime or data loss is incurred as applications are active from multiple regions.
The following diagram shows the difference between each strategy with respect to RTO/RPO and cost.
Option A is incorrect as with a multi-site active/active approach, RPO/RTO will be the least, but it will incur considerable cost.
Option B is incorrect as, with a Warm Standby approach, RPO/RTO will be in minutes, but it will incur additional costs.
Option C is incorrect as with the Backup & Restore approach, RPO/RTO will be in hours, not in minutes.
For more information on Disaster Recovery, refer to the following URL,
Domain: Design Resilient Architectures
59). A critical application deployed in AWS Cloud requires maximum availability to avoid any outages. The project team has already deployed all resources in multiple regions with redundancy at all levels. They are concerned about the configuration of Amazon Route 53 for this application which should complement higher availability and reliability. Route 53 should be configured to use failover resources during a disaster.
What solution can be implemented with Amazon Route 53 for maximum availability and increased reliability?
A. Associate multiple IP endpoints in different regions to Route 53 hostname. Use a weighted route policy to change the weights of the primary and failover resources. So, all traffic is diverted to failover resources during a disaster.
B. Create two sets of public-hosted zones for resources in multiple regions. During a disaster, update Route 53 public-hosted zone records to point to a healthy endpoint.
C. Create two sets of private hosted zones for resources in multiple regions. During a disaster, update Route 53 private hosted zone records to point to a healthy endpoint.
D. Associate multiple IP endpoints in different regions to Route 53 hostname. Using health checks, configure Route 53 to automatically failover to healthy endpoints during a disaster.
Correct Answer : D
Explanation
Amazon Route 53 uses control planes to perform management-related activities such as creating, updating, and deleting resources.
The Data plane is used for performing core services of Amazon Route 53 such as authoritative DNS service, health checks, and responding to DNS queries in an Amazon VPC.
The Data plane is globally distributed, offering 100% availability SLA. Control plane traffic is optimized for data consistency and may be impacted during disruptive events in the infrastructure.
While configuring failover between multiple sites, data plane functions such as health checks should be preferred instead of control plane functions. In the above case, multiple endpoints in different regions can be associated with Route 53. Route 53 can be configured to failover to a healthy endpoint based upon the health checks which is a data plane function and always available.
Option A is incorrect as updating weights in a weighted routing policy is a control plane function. For additional resiliency during a disaster, use data plane functions instead of control plane functions.
Options B and C are incorrect as creating, updating, and deleting private or public hosted zone records are part of control plane actions. In case of a disaster, control planes might get affected. Data plane functions such as health checks should be used for resources that are always available.
For more information on Amazon Route 53 control and data plane, refer to the following URLs,
Domain: Design Cost-Optimized Architectures
60). An IT company is using EBS volumes for storing projects related work. Some of these projects are already closed. The data for these projects should be stored long-term as per regulatory guidelines and will be rarely accessed. The operations team is looking for options to store the snapshots created from EBS volumes. The solution should be cost-effective and incur the least admin work.
What solution can be designed for storing data from EBS volumes?
A. Create EBS Snapshots from the volumes and store them in the EBS Snapshots Archive.
B. Use Lambda functions to store incremental EBS snapshots to AWS S3 Glacier.
C. Create EBS Snapshots from the volumes and store them in a third-party low-cost, long-term storage.
D. Create EBS Snapshots from the volumes and store them in the EBS standard tier.
Correct Answer: A
Explanation
Amazon EBS has a new storage tier named Amazon EBS Snapshots Archive for storing snapshots that are accessed rarely and stored for long periods.
By default, snapshots created from Amazon EBS volumes are stored in Amazon EBS Snapshot standard tier. These are incremental snapshots. When EBS snapshots are archived, incremental snapshots are converted to full snapshots.
These snapshots are stored in the EBS Snapshots Archive instead of the standard tier. Storing snapshots in the EBS Snapshots archive costs much less than storing snapshots in the standard tier. EBS snapshot archive helps store snapshots for long durations for governance or compliance requirements, which will be rarely accessed.
Option B is incorrect as it will require additional work for creating an AWS Lambda function. EBS Snapshots archive is a more efficient way of storing snapshots for the long term.
Option C is incorrect as using third-party storage will incur additional costs.
Option D is incorrect as all EBS snapshots are stored in a standard tier by default. Storing snapshots that will be rarely accessed in the standard tier will be costlier than storing in the EBS snapshots archive.
For more information on the Amazon EBS snapshot archive, refer to the following URLs,
https://aws.amazon.com/blogs/aws/new-amazon-ebs-snapshots-archive
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/snapshot-archive.html
Domain: Design High-Performing Architectures
Q61). A start-up firm has created account A using the Amazon RDS DB instance as a database for a web application. The operations team regularly creates manual snapshots for this DB instance in unencrypted format. The Projects Team plans to create a DB instance in other accounts using these snapshots. They are looking for your suggestion for sharing this snapshot and restoring it to DB instances in other accounts. While sharing this snapshot, it must allow only specific accounts specified by the project teams to restore DB instances from the snapshot.
What actions can be initiated for this purpose?
A. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private. In other Accounts, directly restore to DB instances from the snapshot.
B. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as public. In other Accounts, directly restore to DB instances from the snapshot.
C. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private. In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that copy.
D. From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as public. In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that copy.
Correct Answer – A
Explanation:
DB snapshot can be shared with other authorized AWS accounts which can be up to 20 accounts. These snapshots can be either in encrypted or unencrypted format.
For manual snapshots in an unencrypted format, accounts can directly restore a DB instance from the snapshot.
For manual snapshots in an encrypted format, accounts first need to copy the snapshot and then restore it to a DB instance.
While sharing a manual unencrypted snapshot, all accounts can use this snapshot to restore to the DB instance when DB snapshot visibility is set to public.
While sharing a manual unencrypted snapshot, only specified accounts can restore a DB instance when DB snapshot visibility is set to private.
In the case of manual encrypted snapshots, the only available option for DB snapshot visibility is private, as encrypted snapshots cannot be made public.
Option B is incorrect as marking DB snapshot visibility as the public is not an ideal option since snapshots need to share only with specific accounts. Marking DB snapshot visibility as public will provide all Amazon accounts access to the manual snapshot and will be able to restore DB instances using this snapshot.
Option C is incorrect as DB instances can be directly restored from the snapshot for a manual unencrypted snapshot. There is no need to create a copy of the snapshot to restore a DB instance.
Option D is incorrect as already discussed, marking DB snapshot visibility as the public is not an ideal option. For a manual unencrypted snapshot, DB instances can be directly restored from the snapshot.
For more information on sharing Amazon RDS snapshots, refer to the following URLs,
https://aws.amazon.com/premiumsupport/knowledge-center/rds-snapshots-share-account/
https://docs.amazonaws.cn/en_us/AmazonRDS/latest/UserGuide/USER_ShareSnapshot.html
Domain: Design Resilient Architectures
62). An electronic manufacturing company plans to deploy a web application using the Amazon Aurora database. The Management is concerned about the disk failures with DB instances and needs your advice for increasing reliability using Amazon Aurora automatic features. In the event of disk failures, data loss should be avoided, reducing additional work to perform from the point-in-time restoration.
What design suggestions can be provided to increase reliability?
A. Add Aurora Replicas to primary DB instances by placing them in different regions. Aurora’s crash recovery feature will avoid data loss post disk failure.
B. Add Aurora Replicas to primary DB instances by placing them in different availability zones. Aurora storage auto-repair feature will avoid data loss post disk failure.
C. Add Aurora Replicas to the primary DB instance by placing them in different regions. Aurora Survivable page cache feature will avoid data loss post disk failure.
D. Add Aurora Replicas to the primary DB instance by placing them in different availability zones. Aurora’s crash recovery feature will avoid data loss post disk failure.
Correct Answer – B
Explanation: Amazon Aurora Database reliability can be increased by adding Aurora Replicas to the primary DB instance and placing them in different Availability zones. Each of the DB clusters can have a primary DB instance and up to 15 Aurora Replicas. In case of primary DB instance failure, Aurora automatically fails over to replicas. Amazon Aurora also uses the following automatic features to enhance reliability,
- Storage auto-repair: Aurora maintains multiple copies of the data in three different Availability zones. This helps in avoiding data loss post disk failure. If any segment of the disk fails, Aurora automatically recovers data on the segment by using data stored in other cluster volumes. This reduces additional work to perform point-in-time restoration post disk failure.
- Survivable page cache: Manage page cache in a separate process than the database. In the event of database failure, the page cache is stored in the memory. Post restarting the database, applications continue to read data from the page cache providing performance gain.
- Crash recovery: Crash recovery can be used for faster recovery post any crash in the database. With the crash recovery feature, Amazon Aurora performs recovery asynchronously on parallel threads enabling applications to read data from the database without binary logs.
Option A is incorrect. Aurora Replicas should be created in different Availability zones and not in different regions for better availability. The crash recovery does not minimize data loss post disk failures.
Option C is incorrect. The Survivable page cache feature provides performance gains but does not minimize data loss post disk failures. Aurora Replicas should be created in different Availability zones and not in different regions.
Option D is incorrect as the crash recovery feature does not minimize data loss post disk failures.
For more information on Amazon Aurora reliability features, refer to the following URL,
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.StorageReliability.html
Domain: Design Cost-Optimized Architectures
63). A financial institute has deployed a critical web application in the AWS cloud. The management team is looking for a resilient solution with RTO/RPO in ten minutes during a disaster. They have budget concerns, and the cost of provisioning the backup infrastructure should not be very high. As a solution architect, you have been assigned to work on setting a resilient solution meeting the RTO/RPO requirements within the cost constraints.
Which strategy is suited perfectly?
A. Multi-Site Active/Active
B. Warm Standby
C.Backup & Restore
D. Pilot Light
Correct Answer – D
Explanation:
RTO (Recovery Time Objective) is a period for which downtime is observed post-disaster. It’s the time between the disaster and application recovery to serve full workloads. RPO (Recovery Point Objective) defines the amount of data loss during a disaster. It measures the time window when the last backup was performed, and the time when the disaster happened. Various Disaster recovery solutions can be deployed based on RTO/RPO and budget requirements for critical applications.
The following are options available with Disaster recovery,
Backup and Restore: Least expensive among all the options but RTO/RPO will be very high in hours. All backup resources will be initiated only after a disaster at the primary location.
Pilot Light: Less expensive than warm standby and multi-site active/active. RTO/RPO happens in tens of minutes.
In this strategy, a minimum number of active resources are deployed at the backup locations. Resources required for data synchronization between primary and backup locations are only provisioned and are active. Other components such as application servers are switched off and are provisioned post a disaster at the primary location. In the above scenario, Pilot Light is the most suitable option to meet RTO/RPO requirements on a low budget.
Warm Standby: Expensive Than Pilot Light. RPO/RTO happens in minutes. The application is running at the backup location on scaled-down resource capacity. Once a disaster occurs at the primary location, all the resources are scaled up to meet the desired workload.
Multi-site active/active: Most expensive. No downtime or data loss is incurred as applications are active from multiple regions.
The following diagram shows the difference between each strategy with respect to RTO/RPO and cost.
Option A is incorrect as with a multi-site active/active approach, RPO/RTO will be the least, but it will incur considerable cost.
Option B is incorrect as, with a Warm Standby approach, RPO/RTO will be in minutes, but it will incur additional costs.
Option C is incorrect as with the Backup & Restore approach, RPO/RTO will be in hours, not in minutes.
For more information on Disaster Recovery, refer to the following URL,
Domain: Design Resilient Architectures
64). A critical application deployed in AWS Cloud requires maximum availability to avoid any outages. The project team has already deployed all resources in multiple regions with redundancy at all levels. They are concerned about the configuration of Amazon Route 53 for this application which should complement higher availability and reliability. Route 53 should be configured to use failover resources during a disaster.
What solution can be implemented with Amazon Route 53 for maximum availability and increased reliability?
A. Associate multiple IP endpoints in different regions to Route 53 hostname. Use a weighted route policy to change the weights of the primary and failover resources. So, all traffic is diverted to failover resources during a disaster.
B. Create two sets of public-hosted zones for resources in multiple regions. During a disaster, update Route 53 public-hosted zone records to point to a healthy endpoint.
C. Create two sets of private hosted zones for resources in multiple regions. During a disaster, update Route 53 private hosted zone records to point to a healthy endpoint.
D. Associate multiple IP endpoints in different regions to Route 53 hostname. Using health checks, configure Route 53 to automatically failover to healthy endpoints during a disaster.
Correct Answer – D
Explanation:
Amazon Route 53 uses control planes to perform management-related activities such as creating, updating, and deleting resources.
The Data plane is used for performing core services of Amazon Route 53 such as authoritative DNS service, health checks, and responding to DNS queries in an Amazon VPC.
The Data plane is globally distributed, offering 100% availability SLA. Control plane traffic is optimized for data consistency and may be impacted during disruptive events in the infrastructure.
While configuring failover between multiple sites, data plane functions such as health checks should be preferred instead of control plane functions. In the above case, multiple endpoints in different regions can be associated with Route 53. Route 53 can be configured to failover to a healthy endpoint based upon the health checks which is a data plane function and always available.
Option A is incorrect as updating weights in a weighted routing policy is a control plane function. For additional resiliency during a disaster, use data plane functions instead of control plane functions.
Options B and C are incorrect as creating, updating, and deleting private or public hosted zone records are part of control plane actions. In case of a disaster, control planes might get affected. Data plane functions such as health checks should be used for resources that are always available.
For more information on Amazon Route 53 control and data plane, refer to the following URLs,
Domain: Design Cost-Optimized Architectures
65). An IT company is using EBS volumes for storing projects related work. Some of these projects are already closed. The data for these projects should be stored long-term as per regulatory guidelines and will be rarely accessed. The operations team is looking for options to store the snapshots created from EBS volumes. The solution should be cost-effective and incur the least admin work.
What solution can be designed for storing data from EBS volumes?
A. Create EBS Snapshots from the volumes and store them in the EBS Snapshots Archive.
B. Use Lambda functions to store incremental EBS snapshots to AWS S3 Glacier.
C. Create EBS Snapshots from the volumes and store them in a third-party low-cost, long-term storage.
D. Create EBS Snapshots from the volumes and store them in the EBS standard tier.
Correct Answer – A
Explanation:
Amazon EBS has a new storage tier named Amazon EBS Snapshots Archive for storing snapshots that are accessed rarely and stored for long periods.
By default, snapshots created from Amazon EBS volumes are stored in Amazon EBS Snapshot standard tier. These are incremental snapshots. When EBS snapshots are archived, incremental snapshots are converted to full snapshots.
These snapshots are stored in the EBS Snapshots Archive instead of the standard tier. Storing snapshots in the EBS Snapshots archive costs much less than storing snapshots in the standard tier. EBS snapshot archive helps store snapshots for long durations for governance or compliance requirements, which will be rarely accessed.
Option B is incorrect as it will require additional work for creating an AWS Lambda function. EBS Snapshots archive is a more efficient way of storing snapshots for the long term.
Option C is incorrect as using third-party storage will incur additional costs.
Option D is incorrect as all EBS snapshots are stored in a standard tier by default. Storing snapshots that will be rarely accessed in the standard tier will be costlier than storing in the EBS snapshots archive.
For more information on the Amazon EBS snapshot archive, refer to the following URLs,
https://aws.amazon.com/blogs/aws/new-amazon-ebs-snapshots-archive
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/snapshot-archive.html
Domain: Design High-Performing Architectures
Q66). A manufacturing firm has a large number of smart devices installed in various locations worldwide. Hourly logs from these devices are stored in an Amazon S3 bucket. Management is looking for comprehensive dashboards which should incorporate usages of these devices and forecast usage trends for these devices.
Which tool is the best suited to get this required dashboard?
A. Use S3 as a source for Amazon QuickSight and create dashboards for usage and forecast trends.
B. Use S3 as a source for Amazon Redshift and create dashboards for usage and forecast trends.
C. Copy data from Amazon S3 to Amazon DynamoDB. Use Amazon DynamoDB as a source for Amazon QuickSight and create dashboards for usage and forecast trends.
D. Copy data from Amazon S3 to Amazon RDS. Use Amazon RDS as a source for Amazon QuickSight and create dashboards for usage and forecast trends.
Correct Answer – A
Explanation:
Amazon QuickSight is a business analytical tool that can be used to build visualizations and perform ad-hoc analysis integrating with ML insights. It can connect to various data sources which can either be in the AWS cloud or in the on-premises network or in any third-party applications.
For AWS it supports various services such as Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon Athena, and Amazon S3 as sources. Based on this data, Amazon QuickSight creates custom dashboards that include anomaly detections, forecasting, and auto-narratives.
In the above case, logs from the devices are stored in Amazon S3. Amazon QuickSight can be used to fetch this data, perform analysis, and generate comprehensive custom dashboards for device usage as well as forecasting device usage.
Option B is incorrect as Amazon Redshift is a data warehousing service for analyzing structured or semi-structured data. It is not a useful tool for creating dashboards.
Option C is incorrect as Amazon S3 can be used directly as a source for Amazon QuickSight. There is no need to copy data from Amazon S3 to Amazon DynamoDB.
Option D is incorrect as Amazon S3 can be used directly as a source for Amazon QuickSight. There is no need to copy data from Amazon S3 to Amazon RDS.
For more information on Amazon QuickSight, refer to the following URL,
https://aws.amazon.com/quicksight/resources/faqs/
Domain: Design High-Performing Architectures
Q67). A company has launched Amazon EC2 instances in an Auto Scaling group for deploying a web application. The Operations Team is looking to capture custom metrics for this application from all the instances. These metrics should be viewed as aggregated metrics for all instances in an Auto Scaling group.
What configuration can be implemented to get the metrics as required?
A. Use Amazon CloudWatch metrics with detail monitoring enabled and send to CloudWatch console where all the metrics for an Auto Scaling group will be aggregated by default.
B. Install a unified CloudWatch agent on all Amazon EC2 instances in an Auto Scaling group and use “aggregation_dimensions” in an agent configuration file to aggregate metrics for all instances.
C. Install unified CloudWatch agent on all Amazon EC2 instances in an Auto Scaling group and use “append-config” in an agent configuration file to aggregate metrics for all instances
D. Use Amazon CloudWatch metrics with detail monitoring enabled and create a single Dashboard to display metrics from all the instances.
Correct Answer – B
Explanation:
Unified CloudWatch agent can be installed on Amazon EC2 instance for the following cases,
- Collect Internal System-level metrics from Amazon EC2 installed as well as from on-premises servers.
- Collect custom metrics from the applications on the Amazon EC2 instance using StatsD and collectd protocols.
- Collect logs from EC2 instances or from on-premises servers for both Windows and Linux OS.
In the case of the Instances which are part of an Auto Scaling group, metrics from all the instances can be aggregated using “aggregation_dimensions” in the agent configuration file.
Option A is incorrect as for retrieving custom level metrics for applications on an Amazon EC2 Instance, a unified CloudWatch agent is required. Amazon CloudWatch metrics with detail monitoring will be capturing metrics every 1 minute but it won’t capture custom application metrics.
Option C is incorrect as the append-config configuration in an agent configuration file can be used to have multiple CloudWatch agent configuration files. This command is not suitable for aggregate metrics from all the instances in an Auto Scaling group.
Option D is incorrect as for retrieving custom level metrics for applications on an Amazon EC2 Instance, a unified CloudWatch agent is required. Dashboards can be used to create a customized view of the metrics, but they won’t aggregate metrics from the instance in an Auto Scaling Group.
For more information on the CloudWatch agent, refer to the following URL,
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html
Domain: Design High-Performing Architectures
Q68). A critical web application is deployed on multiple Amazon EC2 instances which are part of an Autoscaling group. One of the Amazon EC2 instances in the group needs to have a software upgrade. The Operations Team is looking for your suggestions to advise for this upgrade without impacting another instance in the group. Post upgradation the same instance should be part of the Auto Scaling group.
What steps can be initiated to complete this upgrade?
A. Hibernate the instance and perform upgradation in offline mode. Post upgrades start the instance which will be part of the same auto-scaling group.
B. Use cooldown timers to perform upgrades on the instance. Post cooldown timers’ instances would be part of the same auto-scaling group.
C. Put the instance in Standby mode. Post upgrade, move instance back to InService mode. It will be part of the same auto-scaling group.
D. Use lifecycle hooks to perform upgrades on the instance. Once these timers expire, the instance would be part of the same auto-scaling group.
Correct Answer – C
Explanation:
Amazon EC2 instances in an Auto Scaling group can be moved to Standby mode from InService mode. In standby mode, software upgradation or troubleshooting can be performed on the instance. Post upgradation, instances can be again put in InService mode back in the same Auto Scaling group. With instance in a standby mode, Auto Scaling does not terminate this group as a part of health checks or scale-in events.
Option A is incorrect as Hibernate is not supported on an Amazon EC2 instance which is part of an Auto Scaling group. When an instance in an Auto Scaling group is hibernated, the Auto-scaling group marks the hibernated instance as unhealthy, terminates it, and launches a new instance. Hibernating an instance will not be useful for upgrading software on an instance.
Option B is incorrect as cooldown timers are the timers that will prevent launching or terminating instances in an Auto Scaling group till previous activities of launch or termination are completed. This timer provides a time for an instance to be in an active state before the Auto Scaling group adds a new one. This timer would not be useful for troubleshooting an instance.
Option D is incorrect as a Lifecycle hook can help to perform custom actions such as data backups before an instance is terminated or to perform software instances once an instance is launched. This hook is not useful for upgrading a running instance in an Auto Scaling Group and adding back to the original group.
For more information on upgrading the Amazon EC2 instance in an Auto Scaling group, refer to the following URLs,
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-hibernate-limitations.html
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-enter-exit-standby.html
Domain: Design High-Performing Architectures
Hybrid connectivity is built between an on-premises network and VPC using a Site-to-Site VPN. At the on-premises network, a legacy firewall is deployed which allows a single /28 IP prefix from VPC to access the on-premises network. Access to this firewall is blocked and the operations team needs to allow communication from an additional IP pool from VPC. Operations Head is looking for a temporary workaround to enable communication from the new IP pool to the on-premises network.
What connectivity can be deployed to mitigate this issue?
A. Deploy public NAT gateway in a private subnet with IP pool allowed in on-premises firewall. Launch the instance which needs to have communication with the on-premises network in a separate private subnet.
B. Deploy public NAT gateway in a public subnet with IP pool allowed in on-premises firewall. Launch the instance which needs to have communication with the on-premises network in a separate public subnet.
C. Deploy private NAT gateway in a public subnet with IP pool allowed in on-premises firewall.Launch the instance which needs to have communication with the on-premises network in a separate private subnet.
D. Deploy private NAT gateway in a private subnet with IP pool allowed in on-premises firewall. Launch the instance which needs to have communication with the on-premises network in a separate private subnet.
Correct Answer – D
Explanation: Private NAT Gateway can be used to establish connectivity from an instance in a private subnet of the VPC to other VPCs or to an on-premises network. With a private NAT gateway, the source IP address of the instance is replaced with the IP address pool of the private NAT Gateway. In the above scenario, legacy firewalls will allow communication from VPC to on-premises networks only from /28 IP pool.
To establish communication from an instance with a new IP pool, NAT Gateway can be deployed in an /28 IP pool which is allowed in Firewall. The instance will be deployed in a separate private subnet. While communicating with the On-premises network, Instance IP will be replaced with the NAT Gateway IP Pool which is already allowed in a firewall and connectivity will be established without any changes in the firewall.
Diagram showing connectivity from Private subnet to On-premises using a Private NAT gateway,
Option A is incorrect because resources in a VPC require to have communications with an on-premises network and not with the Internet, so a Public NAT gateway is not an ideal option. A Public NAT gateway is placed in a public subnet to provide internet access for resources in private subnets.
Option B is incorrect as the resources in a VPC require to have communications with an on-premises network and not with the Internet, so a Public NAT gateway is not an ideal option. A Public NAT gateway is used to provide internet access for resources in private subnets.
Option C is incorrect as to provide communication from a private subnet to an on-premises network, a private NAT gateway should be placed in a private subnet and not in a public subnet.
For more information on NAT Gateways, refer to the following URL,
https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html
Domain: Design Cost-Optimized Architectures
A third-party vendor based in an on-premises location needs to have temporary connectivity to database servers launched in a single Amazon VPC. The proposed connectivity for these few users should be secure, and access should be provided only to authenticated users.
Which connectivity option can be deployed for this requirement in the most cost-effective way?
A. Deploy an AWS Client VPN from third-party vendor’s client machines to access databases in Amazon VPC.
B. Deploy AWS Direct Connect connectivity from the on-premises network to AWS.
C. Deploy an AWS Managed VPN connectivity to a Virtual Private gateway from an on-premises network.
D. Deploy an AWS Managed VPN connectivity to the AWS Transit gateway from the on-premises network.
Correct Answer – A
Explanation:
AWS Client VPC is a managed client-based VPN for having secure access to resources in VPC as well as resources in on-premises networks. Clients looking for access to these resources use an OpenVPN-based VPN client. Access to resources in VPC is secure over TLS and clients are authenticated before access is granted.
In the above case, since third-party vendors from on-premises need secure temporary connectivity to resources in VPC, AWS Client VPN can be used to provide this connectivity.
Option B is incorrect as since there are only a few users accessing resources from a single VPC for temporary purposes, using AWS Direct Connect will be costly and will require a longer time for deployment.
Option C is incorrect as using Managed VPN for a few users will be costlier than using AWS Client VPN for those few users accessing databases from VPC.
Option D is incorrect as Connectivity to AWS Transit gateway will be useful for accessing resources from multiple VPCs. Also, since only a few users access resources from a single VPC for temporary purposes, AWS Client VPN is a cost-effective option.
For more information on the difference between various options for Hybrid connectivity, refer to the following URL,
https://docs.aws.amazon.com/vpn/latest/clientvpn-admin/scenario-vpc.html
Domain: Design Secure Architectures
A company is storing data in an Amazon S3 bucket which is accessed by global users. Amazon S3 bucket is encrypted with AWS KMS. The company is planning to use Amazon CloudFront as a CDN for high performance. The Operations Team is looking for your suggestions to create an S3 bucket policy to restrict access to the S3 bucket only via specific CloudFront distribution.
How can the S3 bucket policy be implemented to control access to the S3 bucket?
A. Use a Principal element in the policy to match service as CloudFront distribution that contains the S3 origin.
B. Use a Condition element in the policy to allow CloudFront to access the bucket only when the request is on behalf of the CloudFront distribution that contains the S3 origin.
C. Use a Principal element in the policy to allow CloudFront Origin Access Identity (OAI).
D. Use a Condition element in the policy to match service as cloudfront.amazonaws.com.
Correct Answer – B
Explanation:
While using Amazon CloudFront with Amazon S3 as an origin, there are two ways to control access to the S3 bucket via Amazon CloudFront,
- OAI (Origin Access Identity): This is a legacy method that does not support AWS KMS as encryption or dynamic requests to the Amazon S3 and Opt-in regions.
- OAC (Origin Access Control): This is a new method and supports the following three points such as AWS KMS for encryption, dynamic requests to the Amazon S3 and Opt-in regions which are not supported by OAI.
While creating policy for OAC, the principal element should have service as “cloudfront.amazonaws.com” and the condition element should match the CloudFront distribution which contains S3 origin.
Option A is incorrect as the Principal element in the policy should match service as CloudFront and not CloudFront distribution.
Option C is incorrect as using CloudFront Origin Access Identity is a legacy method and does not support the Amazon S3 bucket with AWS KMS server-side encryption.
Option D is incorrect as a Condition element should match CloudFront distribution that contains S3 origin and not the service name as cloudfront.amazonaws.com.
For more information on creating Origin Access Control with Amazon S3, refer to the following URL,
Domain: Design Secure Architectures
A company is using microservices-based applications using Amazon ECS for an online shopping application. For different services, multiple tasks are created in a container using the EC2 launch type. The security team is looking for some specific security controls for the tasks in the containers along with granular network monitoring using various tools for each task.
What networking mode configuration can be considered with Amazon ECS to meet this requirement?
A. Use host networking mode for Amazon ECS tasks.
B. By default, an elastic network interface (ENI) with a primary private IP address is assigned to each task.
C. Use awsvpc networking mode for Amazon ECS tasks.
D. Use bridge networking mode for Amazon ECS tasks.
Correct Answer – C
Explanation:
Amazon ECS with EC2 launch type supports the following networking mode,
- Host Mode: This is a basic mode in which the networking of the container is directly tied to the underlying host.
- Bridge Mode: In this mode, a network bridge is created between host and container networking. This bridge mode allows the remapping of ports between host and container ports.
- None mode: In this mode, networking is not attached to the container. With this mode, containers do not have external connectivity.
- AWSVPC Mode: In this mode, each task is allocated a separate ENI (Elastic Network Interface). Each Task will receive a separate IP address and a separate security group can be assigned to each ENI. This helps to have separate security policies for each task and helps to get granular monitoring for traffic flowing via each task.
In the above scenario, using AWSVPC mode, the security team can assign different security policies for each task as well as monitor traffic from each task distinctly.
Option A is incorrect as with host networking mode, networking of containers uses the network interface of the Amazon EC2 instance on which it’s running. This is a basic network type and each task does not get assigned a different networking mode.
Option B is incorrect as an elastic network interface (ENI) with the primary private IP address is assigned for Fargate task networking, not for ECS task networking.
Option D is incorrect as Bridge mode uses Docker’s built-in virtual network. Containers connected to the bridge can communicate with others. Containers using different bridges cannot communicate with each other while providing isolation. It does not provide each task with a separate networking mode that can be used for security controls and network monitoring.
For more information on Amazon ECS task networking and choosing a network mode, refer to the following URLs,
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-networking.html
https://docs.aws.amazon.com/AmazonECS/latest/bestpracticesguide/networking-networkmode.html
Domain: Design High-Performing Architectures
A start-up firm is planning to deploy container-based applications using Amazon ECS. The firm is looking for the least latency from on-premises networks to the workloads in the containers. The proposed solution should be scalable and should support consistent high CPU and memory requirements.
What deployment can be implemented for this purpose?
A. Create a Fargate launch type with Amazon ECS and deploy it in the AWS Outpost.
B. Create a Fargate launch type with Amazon ECS and deploy it in the AWS Local Zone.
C. Create an EC2 launch type with Amazon ECS and deploy it in the AWS Local Zone.
D. Create an EC2 launch type with Amazon ECS and deploy it in the AWS Outpost.
Correct Answer – D
Explanation: Amazon ECS can be deployed in AWS Outposts to provide the least latency from the on-premises location. With AWS Outposts, the EC2 launch type is only supported with Amazon ECS. EC2 launch type is best suited when there is a requirement of consistent high CPU and memory for container-based applications.
Option A is incorrect as the AWS Fargate launch type is not supported with Amazon ECS deployed in the AWS Outpost.
Option B is incorrect as the AWS Fargate launch type is not supported with Amazon ECS deployed in the AWS Local Zone.
Option C is incorrect as with AWS Local Zones, other services such as Amazon EC2 instances, Amazon FSx file servers, and Application Load Balancers need to be implemented before deploying Amazon ECS in the Local Zones.
With AWS Outposts, native AWS services and infrastructure is enabled which makes it an ideal choice for low latency from on-premises networks.
For more information on the Amazon ECS service on AWS Outposts, refer to the following URL,
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-on-outposts.html
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cluster-regions-zones.html
Domain: Design Secure Architectures
A new application is deployed in an Amazon EC2 instance which is launched in a private subnet of Amazon VPC. This application will be fetching data from Amazon S3 as well as from Amazon DynamoDB. The communication between the Amazon EC2 instance and Amazon S3 as well as with Amazon DynamoDB should be secure and should not transverse over internet links. The connectivity should also support accessing data in Amazon S3 from an on-premises network in the future.
What design can be implemented to have secure connectivity?
A. Access Amazon DynamoDB from an instance in a private subnet using a gateway endpoint. Access Amazon S3 from an instance in a private subnet using an interface endpoint.
B. Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a private NAT gateway.
C. Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a public NAT gateway.
D. Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a gateway endpoint.
Correct Answer – A
Explanation:
Using Gateway endpoints, secure and reliable connectivity can be established from a private subnet in a VPC to Amazon S3 or Amazon DynamoDB. This traffic does not transverse over internet links, but it flows over AWS private links.
Amazon S3 supports two types of VPC endpoints: Gateway Endpoint and Interface Endpoint. Both these connectivity options do not transverse over Internet links which makes them secure and reliable connectivity options. With Interface Endpoint, S3 can also be accessed from an on-premises network along with private subnets in a VPC.
In the above scenario, to access Amazon DynamoDB, the Gateway endpoint can be used while to access Amazon S3 from a private subnet as well as from an on-premises network in the future, the Interface Endpoint can be used.
Accessing Amazon S3 over Interface Endpoints:
Accessing Amazon DynamoDB over Gateway Endpoints:
Option B is incorrect as a private NAT gateway can be used to have communication between VPCs or with on-premises networks. It is not an option to have communication from a private subnet in a VPC to an Amazon S3 or Amazon DynamoDB.
Option C is incorrect as with public NAT Gateway, traffic will transverse over the Internet.
Option D is incorrect as with Gateway endpoint, the on-premises network would not be able to access data in Amazon S3 securely over the private link.
For more information on Gateway Endpoints and Interface Endpoints, refer to the following URL,
https://docs.aws.amazon.com/vpc/latest/privatelink/gateway-endpoints.html
Domain: Design Secure Architectures
A static website named ‘whizexample’ is hosted using the Amazon S3 bucket. JavaScript on the web pages stored in the Amazon S3 bucket needs to make authenticated GET requests to the bucket using the Amazon S3 API endpoint for the bucket, example.s3.us-west-1.amazonaws.com.
What additional configuration will be required for allowing this access?
A. Create CORS configuration with Access-Control-Request-Header as GET using JSON and add CORS configuration to the bucket from the S3 console.
B. Create CORS configuration with Access-Control-Request-Method as GET using JSON and add CORS configuration to the bucket from the S3 console.
C. Create CORS configuration with Access-Control-Request-Method as GET using XML and add CORS configuration to the bucket from the S3 console.
D. Create CORS configuration with Access-Control-Request-Header as GET using XML and add CORS configuration to the bucket from the S3 console.
Correct Answer – B
Explanation:
CORS (Cross Origin resource sharing) is a configuration that allows web applications deployed in one domain to interact with applications in different domains. Enabling CORS on an S3 bucket selectively allows content in the S3 bucket to be accessed.
In the above scenario, when CORS is not enabled, JavaScript will not be able to access content in the S3 bucket using the S3 API endpoint. To allow this access, CORS configuration using JSON needs to be created and added to the S3 bucket from the S3 console.
CORS can be enabled with the following settings,
- Access-Control-Allow-Origin
- Access-Control-Allow-Methods
- Access-Control-Allow-Headers
For successful access, Origin, Methods, and Headers from the requestor should match the values defined in the configuration files. In the above scenario, the GET method should be added to the CORS configuration file.
Option A is incorrect as for GET requests, Access-Control-Allow-Methods should be defined in the configuration file and not the Access-Control-Allow-Headers.
Option C is incorrect as CORS configuration with XML is not supported while configuring CORS using the S3 console.
Option D is incorrect as for GET request, Access-Control-Allow-Methods should be defined in the configuration file and not the Access-Control-Allow-Headers. CORS configuration with XML is not supported while configuring CORS using the S3 console.
For more information on configuring CORS in Amazon S3, refer to the following URLs,
https://docs.aws.amazon.com/AmazonS3/latest/userguide/cors.html
Old Questions
8) You are planning to build a fleet of EBS-optimized EC2 instances for your new application. Due to security compliance, your organization wants you to encrypt root volume which is used to boot the instances. How can this be achieved?
A. Select the Encryption option for the root EBS volume while launching the EC2 instance.
B. Once the EC2 instances are launched, encrypt the root volume using AWS KMS Master Key.
C. Root volumes cannot be encrypted. Add another EBS volume with an encryption option selected during launch. Once EC2 instances are launched, make encrypted EBS volume as root volume through the console.
D. Launch an unencrypted EC2 instance and create a snapshot of the root volume. Make a copy of the snapshot with the encryption option selected and CreateImage using the encrypted snapshot. Use this image to launch EC2 instances.
Answer: D
When launching an EC2 instance, the EBS volume for root cannot be encrypted.

You can launch the instance with unencrypted root volume and create a snapshot of the root volume. Once the snapshot is created, you can copy the snapshot where you can make the new snapshot encrypted.

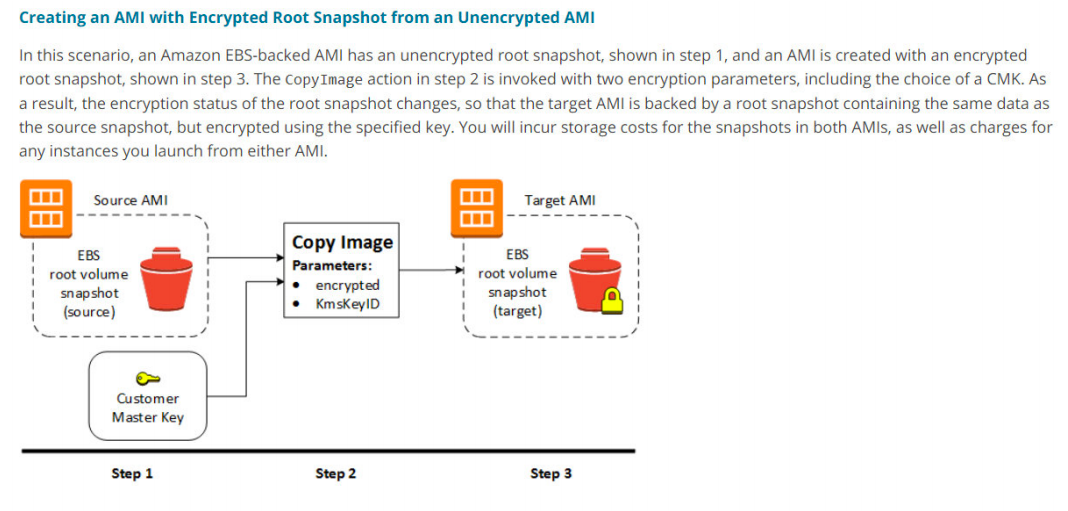
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIEncryption.html#AMIEncryption
9) Organization XYZ is planning to build an online chat application for their enterprise level collaboration for their employees across the world. They are looking for a single digit latency fully managed database to store and retrieve conversations. What would AWS Database service you recommend?
A. AWS DynamoDB
B. AWS RDS
C. AWS Redshift
D. AWS Aurora
Answer: A

Read more here: https://aws.amazon.com/dynamodb/#whentousedynamodb
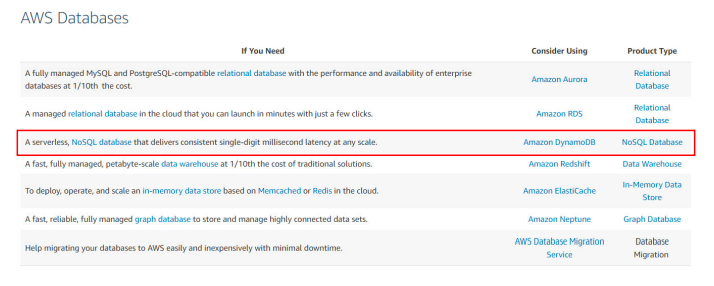
Read more here: https://aws.amazon.com/about-aws/whats-new/2015/07/amazon-dynamodb-available-now-cross-region-replication-triggers-and-streams/
11) Which of the following statements are true with respect to VPC? (choose multiple)
A. A subnet can have multiple route tables associated with it.
B. A network ACL can be associated with multiple subnets.
C. A route with target “local” on the route table can be edited to restrict traffic within VPC.
D. Subnet’s IP CIDR block can be same as the VPC CIDR block.
Answer: B, D
Option A is not correct. A subnet can have only one route table associated with it.
Option B is correct.
Option C is not correct.

Option D is correct.
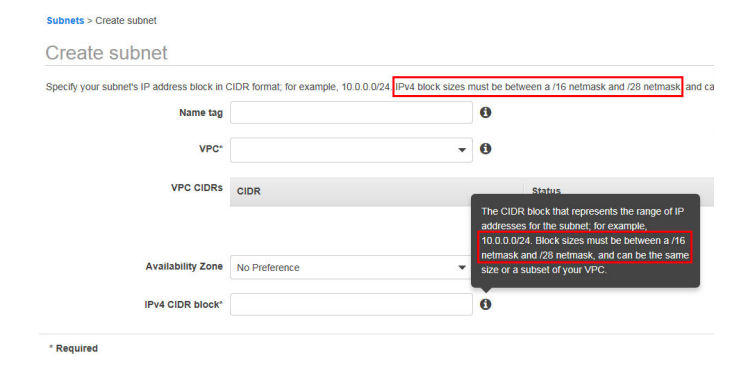
Aspired to learn AWS? Here we bring the AWS CHEAT SHEET that will take you through cloud Computing and AWS basics along with AWS products and services!
12) Organization ABC has a customer base in the US and Australia that would be downloading 10s of GBs files from your application. For them to have a better download experience, they decided to use the AWS S3 bucket with cross-region replication with the US as the source and Australia as the destination. They are using existing unused S3 buckets and had set up cross-region replication successfully. However, when files uploaded to the US bucket, they are not being replicated to Australia bucket. What could be the reason?
A. Versioning is not enabled on the source and destination buckets.
B. Encryption is not enabled on the source and destination buckets.
C. Source bucket has a policy with DENY and the role used for replication is not excluded from DENY.
D. Destination bucket’s default CORS policy does not have source bucket added as the origin.
Answer: C
When you have a bucket policy which has explicit DENY, you must exclude all IAM resources which need to access the bucket.

Read more here: https://aws.amazon.com/blogs/security/how-to-create-a-policy-that-whitelists-access-to-sensitive-amazon-s3-buckets/
For option A, Cross region replication cannot be enabled without enabling versioning. The question states that cross-region replication has been successfully enabled. So this option is not correct.
13) Which of the following is not a category in AWS Trusted Advisor service checks?
A. Cost Optimization
B. Fault Tolerance
C. Service Limits
D. Network Optimization
Answer: D
https://aws.amazon.com/premiumsupport/trustedadvisor/
17) How many VPCs can an Internet Gateway be attached to at any given time?
A. 2
B. 5
C. 1
D. By default 1. But it can be attached to any VPC peered with its belonging VPC.
Answer: C
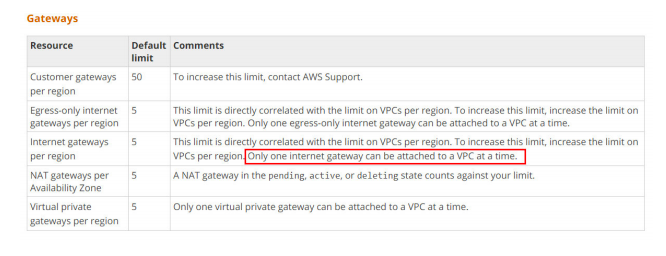
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/amazon-vpc-limits.html#vpc-limits-gateways
At any given time, an Internet Gateway can be attached to only one VPC. It can be detached from the VPC and be used for another VPC.
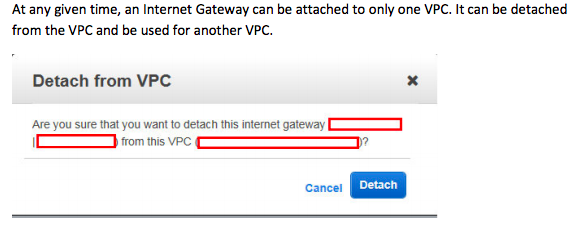
19) Which of the following are not backup and restore solutions provided by AWS? (choose multiple)
A. AWS Elastic Block Store
B. AWS Storage Gateway
C. AWS Elastic Beanstalk
D. AWS Database Migration Hub
E. AWS CloudFormation
Answer: C, E
Option A is snapshot based data backup solution.

Option B, AWS Storage Gateway provides multiple solutions for backup & recovery.
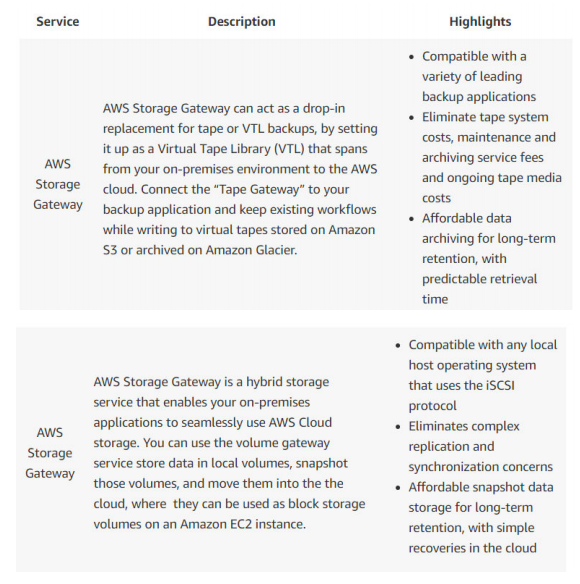
Option D can be used as a Database backup solution.

25) Which of the following is an AWS component which consumes resources from your VPC?
A. Internet Gateway
B. Gateway VPC Endpoints
C. Elastic IP Addresses
D. NAT Gateway
Answer: D
Option A is not correct.
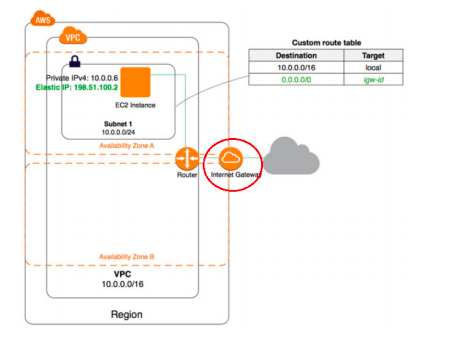
An internet gateway is an AWS component which sits outside of your VPC does not consume any resources from your VPC.
Option B is not correct.
Endpoints are virtual devices. They are horizontally scaled, redundant, and highly available VPC components that allow communication between instances in your VPC and services without imposing availability risks or bandwidth constraints on your network traffic.
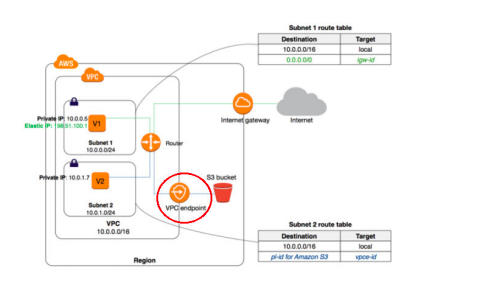
Option C is not correct.
An Elastic IP address is a static, public IPv4 address designed for dynamic cloud computing. You can associate an Elastic IP address with any instance or network interface for any VPC in your account. With an Elastic IP address, you can mask the failure of an instance by rapidly remapping the address to another instance in your VPC.
They do not belong to a single VPC.
Option D is correct.
To create a NAT gateway, you must specify the public subnet in which the NAT gateway should reside. For more information about public and private subnets, see Subnet Routing. You must also specify an Elastic IP address to associate with the NAT gateway when you create it. After you’ve created a NAT gateway, you must update the route table associated with one or more of your private subnets to point Internet-bound traffic to the NAT gateway. This enables instances in your private subnets to communicate with the internet.
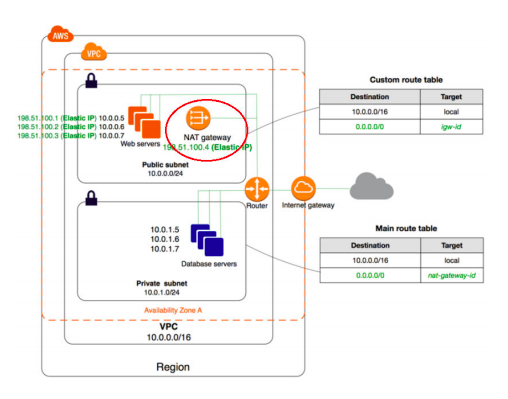
Frequently Asked Questions (FAQs)
How many questions are on AWS Solution Architect Associate exam?
The number of questions in the AWS Architect exam is around 60-70. This number could be varry.
What is passing score for AWS?
The passing score of the exam is around 70-75%. AWS doesn’t officially announce the passing score, but these are based on the exam taker’s experience.
Is AWS Associate Solutions Architect exam hard?
Not very tough. When you compare to Cloud Practitioner exam, it’s harder. However, compare to the SysOps exam, it’s easier.
How many questions are on the AWS Solutions Architect Associate exam?
The number of questions in the AWS Architect exam is around 60-70. This number could be varry.
Summary
So, here we’ve presented 50+ Free AWS Solutions Architect exam questions for the AWS associate certification exam. Definitely, these AWS CSAA practice questions would have helped you to check your preparation level and boost your confidence for the exam. We, at Whizlabs, are aiming to prepare you for the AWS Solution Architect Associate exam (SAA-C03).
Note that these are not aws certification exam dumps. This AWS Solutions Architect Associate practice questions are real exam simulators that would help you to pass the exam in the first attempt. Buying aws exam dumps or brain dumps are not a good idea to pass the exam.
Here is the list of practice questions offered by Whizlabs. These are created by certified experts.
If you have any questions about our aws csaa exam questions, please contact our support at [email protected].
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024

thank you , this is helpfil.
Please refrain from just attaching 2023 when the content was made in 2021 and many things are simply outdated, thank you.