
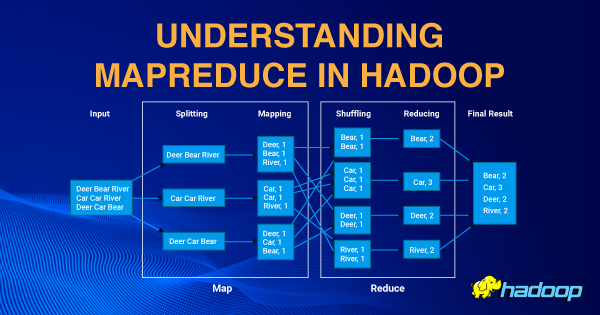
MapReduce is the core component of processing in a Hadoop Ecosystem as it provides logic of processing the data . MapReduce is a software framework that is used for processing large datasets in parallel across computer clusters so that the output results are obtained efficiently. The following article provides an understanding of MapReduce in Hadoop.

What is MapReduce in Hadoop?
One of the main components of Hadoop is MapReduce. MapReduce is a massively parallel data processing framework that processes faster, scalable and fault-tolerant data of a distributed environment. MapReduce can process a large volume of data in parallel, by dividing a task into independent sub-tasks. Hadoop can run MapReduce programs written in various languages such as Java, Ruby, Python, and C++.
The MapReduce works by breaking the processing into two tasks: the map task and the reduce task. As the name MapReduce implies, the reduce task takes place after the map task has been completed. Each task has key-value pairs as input and output, the types of which may be chosen by the programmer.
Map takes a set of data and converts it into another set of data, where individual elements are broken down into key-value pairs. Then the reduce task receives the output from a map as an input which is in key-value pairs and combines those data into a smaller set of key-value pairs.
The MapReduce architecture
MapReduce architecture has the following two daemon processes:
- JobTracker: Master process
- TaskTracker: Slave process
JobTracker: JobTracker is the master process and is responsible for coordinating and completing a MapReduce job in Hadoop. The main functionality of JobTracker is resource management, tracking resource availability, and keeping track of our requests.
TaskTracker: TaskTracker is the slave process to the JobTracker.TaskTracker sends heartbeat messages to JobTracker every 3 seconds to inform JobTracker about the free slots and sends the status about the task and checks if any task has to be performed
The MapReduce phases
MapReduce frameworks have multiple steps and processes or tasks. MapReduce jobs are complex and involve multiple steps; some steps are performed by Hadoop with default behavior and can be overridden if needed.
The MapReduce program is executed in three main phases: mapping phase, shuffling and sorting phase, and reducing phase. There is also an optional phase known as the combiner phase.
- Mapping phase
This is the first phase of the program. There are two steps in this phase: splitting and mapping. The input file is divided into smaller equal chunks for efficiency which are called input splits. Since the Mappers understand (key, value) pairs only so Hadoop uses a RecordReader that uses TextInputFormat to transform input splits into key-value pairs.
In MapReduce, parallelism will be achieved by Mapper. For each Input split, a new instance of the mapper is instantiated. The mapping step contains a coding logic that is applied to these data blocks. In this step, the mapper processes the key-value pairs and produces an output of the same form (key-value pairs).
- Shuffle and sorting phase
Shuffle and sort are intermediate steps in MapReduce between Mapper and Reducer, which is handled by Hadoop and can be overridden if required. The Shuffle process aggregates all the Mapper output by grouping key values of the Mapper output and the value will be appended in a list of values. So, the Shuffle output format will be a map <key, List<list of values>>. The key from the Mapper output will be consolidated and sorted.
- Reducer phase
The output of the shuffle and sorting phase is used as the input to the Reducer phase and the Reducer will process on the list of values. Each key could be sent to a different Reducer. Reducer can set the value, and that will be consolidated in the final output of a MapReduce job and the value will be saved in HDFS as the final output.
Let us try to understand MapReduce with the help of a simple example :
In this example, we will count the number of occurrences of all the unique words in a text file.
Let’s consider that we have a word file that contains some text. Although here we are considering a single file as an example in real-world scenarios, Hadoop deals with large and more complex files.
Suppose the text file which we are using is called test.txt and it contains the following data:
| Data Hadoop Python
Hadoop Hadoop Java Python Data Apache |
The output which we expect should look like this:
| Apache – 1
Data – 2 Hadoop – 3 Java – 1 Python – 2 |
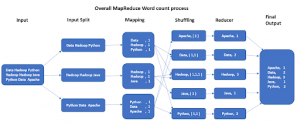
Suppose a user runs a query (count number of occurrences of all the unique words) on our test.txt file. To keep a track of our requests, we use Job Tracker (a master service), the JobTracker traps our request and keeps a track of it.
First, the records are divided into smaller chunks for efficiency, in our case the input is divided into 3 chunks which are called input splits. Since there are three input splits, three different mappers will be used for each split.
Mapper then parses the line, gets a word, and sets <<word>, 1> for each word. In this example, the output of Mapper for a line Java Python Hadoop will be <Java, 1>, <Python, 1>, and <Hadoop, 1>.
All Mappers will have a key as a word and value as hardcoded value 1. The reason for giving a hardcoded value 1 and not any other value is because every word in itself will occur once.
In the next phase ( shuffle and sorting ) the key-value pair output from the Mapper having the same key will be consolidated. So key with ‘Hadoop’, ‘Data’, ‘Java’, and others will be consolidated, and values will be appended as a list, in this case <Java, List<1>>, <Python, List<1,1>>, <Hadoop, List<1, 1, 1, 1>>and so on.
The key produced by Mappers will be compared and sorted. The key and list of values will be sent to the next step in the sorted sequence of the key.
Next, the reducer phase will get <key, List<>> as input, and will just count the number of 1s in the list and will set the count value as output. for example, the output for certain steps are given as follows:
<Java, List<1>> will be < Java, 1>
<Python, List<1, 1>> will be <Python, 2>
<Hadoop, List<1, 1, 1, 1>> will be <Hadoop, 4>
In the end, all the output key/value pairs from the Reducer phase will be consolidated to a file and will be saved in HDFS as the final output.
Hadoop MapReduce Applications
MapReduce is used in many applications let us have a look at some of the applications.
- Entertainment :
A lot of web series and movies are released on various OTT platforms such as Netflix. You might have come across a situation where you can’t decide which movie to watch and you take a look at the suggestions provided by Netflix and then you try one of the suggested series or movies.
Hadoop and MapReduce are used by Netflix to recommend the user some popular movies based on what they watched and which movie they like.
MapReduce can determine how users are watching movies, analyzing their logs and clicks.
- E-commerce:
Many E-commerce companies such as Flipkart, Amazon, and eBay use MapReduce to analyze the buying behavior of the customers based on customers’ interests or their buying behavior. It analyzes records, purchase history, user interaction logs, etc., and provides product recommendation mechanisms for various e-commerce companies.
Frequently Asked Questions (FAQS)
Q) What is Hadoop Map Reduce?
MapReduce processes a large volume of data in parallel, by dividing a task into independent sub-tasks. The MapReduce works by breaking the processing into two tasks: the map task and the reduce task.
Map takes a set of data and converts it into another set of data, where individual elements are broken down into key-value pairs. Then the reduce task receives the output from a map as an input which is in key-value pairs and combines those data into a smaller set of key-value pairs.
Q) What is the input type/format in MapReduce by default?
By default, the type input type in MapReduce is ‘text’.
Q) What do sorting and shuffling do?
Sorting and shuffling are responsible for creating a unique key and a list of values. Making similar keys at one location is known as Sorting. And the process by which the intermediate output of the mapper is sorted and sent across to the reducers is known as Shuffling.
Q) What is Input Split?
Input Split is a logical partition of the data, basically used during data processing in the MapReduce program or other processing techniques.his logical partition of data is processed one per Mapper
Q) What is the JobTracker?
JobTracker is a master process that schedules jobs and tracks the assigned jobs to the Task tracker.
Q) What is the Task Tracker?
Task Tracker is a slave process to the JobTracker. It tracks the task and reports status to JobTracker.
Q) Which programming language can we use to write MapReduce programs?
Java, R, C++, and even Scripting Languages like (Python, PHP).
Q)What is Mapper?
The Mapper processes input records produced by the RecordReader and generate intermediate key-value pairs. The intermediate output is completely different from the input pair
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021