

Hadoop has already proved its huge potential in the Big data industry by providing better insights on data to make the business grow. With its unbeatable Big data processing capability using batch processing it has redefined Big data domain. Since Apache Spark stepped into Big data industry, it has met the enterprises’ expectations in a better way regarding data processing, querying, and generating analytics reports in a faster way. Here’s why Apache Spark Faster.
Apache Spark is widely considered as the future of Big Data Platform. In this blog, we will discuss the various aspects of why Apache Spark is gaining more importance in the big data industry.
Also Read: An Introduction to Apache Spark
Apache Spark Improves Business in Big Data Industry
The primary importance of Apache Spark in the Big data industry is because of its in-memory data processing that makes it high-speed data processing engine compare to MapReduce.
Apache Spark has huge potential to contribute to Big data related business in the industry. The different business advantages it carries are –
- It is an ideal tool for companies that focus on Internet of Things. Spark can handle many analytics challenges because of its low-latency in-memory data processing capability. Besides that, it has well-built libraries for machine learning and graph analytics algorithms.
- By utilizing Spark, organizations can enable themselves to analyze data coming from IoT sensors. It becomes possible as Spark can easily process continuous streams of low-latency data. Hence, organizations can create real-time dashboards and explore data to monitor and optimize their business.
- With its high-level libraries for data streaming, machine learning, SQL queries, graph analysis, Spark helps Big data scientists to create complex workflows easily. This not only ensures less coding but also the faster insights on organization’s big data analysis.
- Data scientists can prototype solutions easily using Spark which led to better feedback.
- Fog computing is going to be the next biggest thing after IoT for de-centralized data processing. Apache Spark has the power of analyzing the huge amount of distributed data. As a result, it will help organizations to work on making IoT based applications for new businesses.
- Spark can work on top of existing Hadoop Distributed File System (HDFS), and it works well with Hadoop. Hence, organizations don’t need to build a new set up for Spark. Using the same data and cluster they can deploy Spark on the same Hadoop cluster. It is a more noticeable cost-saving enhancement for the organizations.
- As Spark is compatible with many programming languages like Java, Scala, Python, R, etc., it is easy to use and require less coding. Moreover, there is a significant community of programmers for Spark. Hence, organizations don’t need to hire expensive resources separately.
Know the Apache Spark Technology Underneath and Its Features
Apache Spark is a Big data processing interface which provides not only programming interface in the data cluster but also adequate fault tolerance and data parallelism. This open-source platform is efficient in speedy processing of massive datasets.
Big data processing needs superior abilities which Apache Spark provides better than Hadoop MapReduce.
The features of Apache Spark are as follows:

An Integrated Framework
Apache Spark delivers a better-integrated framework which supports all ranges of Big data formats like batch data, text data, real-time streaming data, graphical data, etc.
Data Processing Speed
Spark processes data in a cyclic data flow and in-memory data sharing way using its execution engine. Interestingly Spark engine supports its DAG(Directed Acrylic Graph) mechanism which carries out multiple jobs with the same set of data. As a result, Spark can process data almost 100 times faster than Hadoop MapReduce.
Multiple Programming Language Support
Apache Spark lets programmers write applications using Python, Clojure, Scala or Java as it has the inbuilt support of over 80 high-level operators.
Enhanced Support for Multiple Operations
Spark provides numerous essential supports related to data processing in big data industry like –
- For streaming data
- SQL queries
- Graphic data processing,
- Machine learning,
- MapReduce operations.
Multi-platform Support
Apache Spark provides extended interoperability regarding its running platform or supported data structure. Spark supports applications running in –
- cloud
- standalone cluster mode
Besides, that Spark can access varied data structures
- HBase
- Tachyon
- HDFS
- Cassandra
- Hive
- Hadoop data source
Spark can be deployed on
- A distributed framework such as YARN or Mesos
- Standalone server

Important Features That Make Apache Spark a Better Choice
Apache Spark Data Streaming is Superior to Traditional Systems
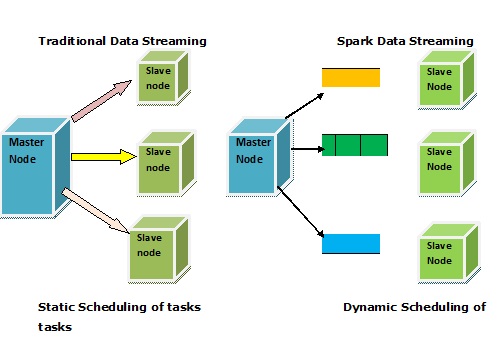
Given below is a figure displaying why Spark streaming is superior to traditional systems:
Traditionally data streaming follows static task scheduling. On the other hand in Spark data streaming it is dynamic scheduling of tasks which make the overall processing faster.
Apache Spark Structured Streaming for Infinite Data Streaming
Structured Streaming is the part of Spark 2.x which is a higher-level API. It helps in creating a more natural abstraction for writing applications. Using Structure Streaming, developers can create infinite streaming data frames as well datasets. With Structured Streaming, a user can efficiently handle message delivery.
Structured streaming facilitates users with the Catalyst query optimizer. Moreover, it can run in an interactive manner. As a result, it allows users to perform SQL queries for live streaming data.
Though structured streaming is still a new venture in Apache Spark, it is the future of data streaming.
Enterprise can Use Apache Spark on the Top of Existing Hadoop Structure
Apache Spark can be considered as an enhancement on the existing Hadoop infrastructure of a company for a speedy Big Data processing. One can easily deploy Apache Spark applications. It can run on existing Hadoop v1 and v2 cluster using an existing Hadoop Distributed File System(HDFS).
Though HDFS works as the primary data storage by Spark, it can work with other data sources compatible with Hadoop like HBase, Cassandra, etc.
Apache Spark: A New Dimension in Big data Industry for Data Scientists
Apache Spark shows an arena for the data scientists where they can build sophisticated data analysis models. The volume and type of data they can use for such analysis were beyond imagination before Spark.
Visualization is an integral part while dealing with data analysis for business purposes. This is more important for Big data analysis. Spark Core helps data scientists to create such reports and dashboards using Java, Python, R scripts, etc.
Spark’s Machine Learning Capability may Help in Data Lake Flow
Recent organization trends towards data lake which is millions of pieces of data need predictive and automatic rules on accessibility. It not only enhances the business agility but also escapes manual interventions.
Apache Spark with its inbuilt machine learning algorithms can help in this data lake processing.
Spark Edges Over Other Open Source Projects in Enterprise Adoption
Among all the Apache open source projects, Apache Spark has become the most in-demand technology in Big data industry across multiple verticals. In the current market scenario, there is an increasing demand to support BI related workloads with Spark SQL and Hadoop.
Moreover, there is a strong open source community support for Spark which makes increasing adoption rate of Spark by the enterprises.
Can Learning Spark Benefit You as a Professional?
In a single sentence – Yes, walk with the pace of technology!
- Coming years are all set to witness an increasing demand for Spark Developers
As Spark has proved itself as a smarter alternative to MapReduce, enterprises more prefer to adopt it. Hence, besides Hadoop developers, demands for the Spark developers are high in the market.
There are increasing needs for permanent as well as contractual positions for Spark developers in the market. IT professionals can leverage this upcoming skill set gap by pursuing a certification in Apache Spark.
- Apache Spark offers impressive pay packages
Since Spark developers are significantly in demand, chances of getting a job in this field his high. The average salary for an Apache Spark Developer in the US is $133,021 per annum which is almost 29% above Indian salary. However, if you convert the amount it is nothing less than the best pay package in the IT industry.
Bottom Line
Spark is being widely used in Big data industry for interactive scaling out batch data processing requirements. In addition to that, it is expected to play a key role in the next generation BI applications. Thus it is wise to take holistic, hands-on training in Spark to excel in the Big data industry. Moreover, it will boost productivity in case they are new to Scala programming.
Learning Spark as certification preparation also covers coding in Python, R, Java, etc. Whizlabs offers aspiring Hadoop and Big data professionals complete training guides for Cloudera and HortonWorks Hadoop related certifications. Our HDP Certified Developer (HDPCD) Spark Certification covers all the technical details of Spark along with hands-on. It will meticulously help anyone to grab the concepts.
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
