

Defined by 3Vs that are velocity, volume, and variety of the data, big data sits in a separate row from the regular data. Though big data was the buzzword for the last few years for data analysis, the new fuss about big data analytics is to build up a real-time big data pipeline. In a single sentence, to build up an efficient big data analytic system for enabling organizations to make decisions on the fly.
In a real-time big data pipeline, you need to consider factors like real-time fraud analysis, log analysis, predicting errors to measure the correct business decisions.
Enroll Now: Apache Kafka Fundamentals Training Course
Hence, to process such high-velocity massive data on a real-time basis, the highly reliable data processing system is the demand of the hour. There are many open-source tools and technologies available in the market to perform real-time big data pipeline operations. In this blog, we will discuss the most preferred ones – Apache Hadoop, Apache Spark, and Apache Kafka.
Why is Real-time Big Data Pipeline So Important Nowadays?
It is estimated that by 2020 approximately 1.7 megabytes of data will be created every second. This results in an increasing demand for real-time and streaming data analysis. For historical data analysis descriptive, prescriptive, and predictive analysis techniques are used. On the other hand, for real-time data analysis, streaming data analysis is the choice. The main benefit of real-time analysis is one can analyze and visualize the report on a real-time basis.
Through real-time big data pipeline, we can perform real-time data analysis which enables the below capabilities:
- Helps to make operational decisions.
- The decisions built out of the results will be applied to business processes, different production activities, and transactions in real-time.
- It can be applied to prescriptive or pre-existing models.
- Helps to generate historical and current data concurrently.
- Generates alerts based on predefined parameters.
- Monitors constantly for changing transactional data sets in real-time
Note: If you are preparing for a Hadoop interview, we recommend you to go through the top Hadoop interview questions and get ready for the interview.
What are the Different Features of a Real-time Big Data Pipeline System?
A real-time big data pipeline should have some essential features to respond to business demands, and besides that, it should not cross the cost and usage limit of the organization.
Features that a big data pipeline system must have:
High volume data storage: The system must have a robust big data framework like Apache Hadoop.
Messaging system: It should have publish-subscribe messaging support like Apache Kafka.
Predictive analysis support: The system should support various machine learning algorithms. Hence it must have required library support like Apache Spark MLlib.
The flexible backend to store result data: The processed output must be stored in some database. Hence, a flexible database preferably NoSQL data should be in place.
Reporting and visualization support: The system must have some reporting and visualization tool like Tableau.
Alert support: The system must be able to generate text or email alerts, and related tool support must be in place.
Do you know Spark RDD (Resilient Distributed Datasets) is the fundamental data structure of Apache Spark?
Why are Apache Hadoop, Apache Spark, and Apache Kafka the Choices for Real-time Big Data Pipeline?
There are some key points that we need to measure while selecting a tool or technology for building a big data pipeline which is as follows:
- Components
- Parameters
Components of a big data pipeline are:
- The messaging system.
- Message distribution support to various nodes for further data processing.
- Data analysis system to derive decisions from data.
- Data storage system to store results and related information.
- Data representation and reporting tools and alerts system.
Important parameters that a big data pipeline system must have –
- Compatible with big data
- Low latency
- Scalability
- A diversity that means it can handle various use cases
- Flexibility
- Economic
The choice of technologies like Apache Hadoop, Apache Spark, and Apache Kafka addresses the above aspects. Hence, these tools are the preferred choice for building a real-time big data pipeline.
Apache Spark is one of the most popular technology for building Big Data Pipeline System. Here is everything you need to know to learn Apache Spark.
What are the Roles that Apache Hadoop, Apache Spark, and Apache Kafka Play in a Big Data Pipeline System?
In a big data pipeline system, the two core processes are –
- The messaging system
- The data ingestion process
The messaging system is the entry point in a big data pipeline and Apache Kafka is a publish-subscribe messaging system work as an input system. For messaging, Apache Kafka provide two mechanisms utilizing its APIs –
- Producer
- Subscriber
Using the Priority queue, it writes data to the producer. Then the data is subscribed by the listener. It could be a Spark listener or any other listener. Apache Kafka can handle high-volume and high-frequency data.
Once the data is available in a messaging system, it needs to be ingested and processed in a real-time manner. Apache Spark makes it possible by using its streaming APIs. Also, Hadoop MapReduce processes the data in some of the architecture.
Apache Hadoop provides an ecosystem for the Apache Spark and Apache Kafka to run on top of it. Additionally, it provides persistent data storage through its HDFS. Also for security purpose, Kerberos can be configured on the Hadoop cluster. Since components such as Apache Spark and Apache Kafka run on a Hadoop cluster, thus they are also covered by this security features and enable a robust big data pipeline system.
How to Build Big Data Pipeline with Apache Hadoop, Apache Spark, and Apache Kafka?
There are two types of architecture followed for the making of real-time big data pipeline:
- Lambda architecture
- Kappa architecture
Lambda Architecture
There are mainly three purposes of Lambda architecture –
- Ingest
- Process
- Query real-time and batch data
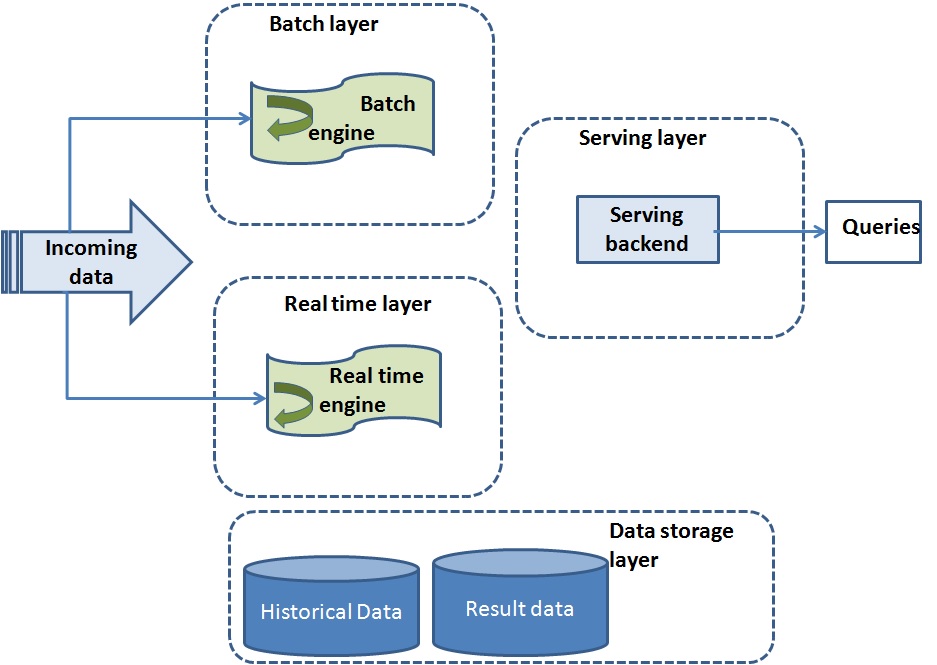
Single data architecture is used for the above three purposes. This architecture consists of three layers of lambda architecture
- Speed layer
- Serving layer
- Batch layer
These layers mainly perform real-time data processing and identify if any error occurs in the system.
How does Lambda Architecture Work?
- From the input source data enters into the system and routed to the batch layer and speed layer. The input source could be a pub-sub messaging system like Apache Kafka.
- Apache Hadoop sits at the batch layer and along with playing the role of persistent data storage performs the two most important functions:
- Manages the master dataset
- Pre-compute the batch views
- Serving layer indexes the batch views which enables low latency querying. NoSQL database is used as a serving layer.
- Speed layer deals with the real-time data only. Also in case of any data error or missing of data during data streaming it manages high latency data updates. Hence, batch jobs running in Hadoop layer will compensate that by running MapReduce job at regular intervals. As a result speed layer provides real-time results to a serving layer. Usually, Apache Spark works as the speed layer.
- Finally, a merged result is generated which is the combination of real-time views and batch views.
Apache Spark is used as the standard platform for batch and speed layer. This facilitates the code sharing between the two layers.
Kappa Architecture
Kappa architecture is comprised of two layers instead of three layers as in the Lambda architecture. These layers are –
- Real-time layer/Stream processing
- Serving layer
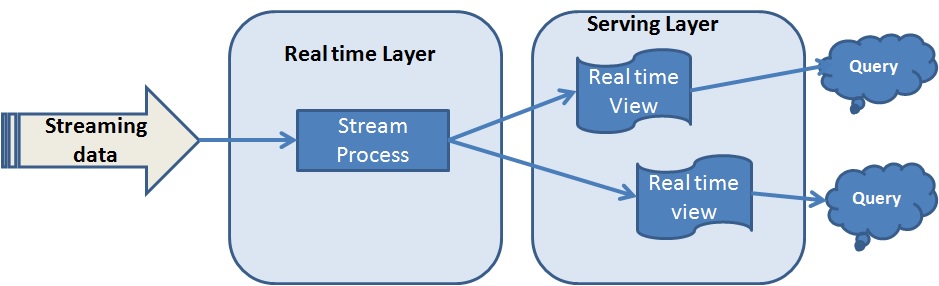
The Flow of Kappa Architecture
- In this case, the incoming data is ingested through the real-time layer via a messaging system like Apache Kafka.
- In the real-time layer or streaming process data is processed. Usually, Apache Spark is used in this layer as it supports both batch and stream data processing.
- The output result from the real-time layer is sent to the serving layer which is a backend system like a NoSQL database.
- Apache Hadoop provides the eco-system for Apache Spark and Apache Kafka.
The main benefit of Kappa architecture is that it can handle both real-time and continuous data processing through a single stream process engine.
As a beginner, it is not so simple to learn Hadoop to build a career in. But we make learning Hadoop for beginners simple, explore how!
How does a Business Get Benefit with Real-time Big Data Pipeline?
If Big Data pipeline is appropriately deployed it can add several benefits to an organization. As it can enable real-time data processing and detect real-time fraud, it helps an organization from revenue loss. Big data pipeline can be applied in any business domains, and it has a huge impact towards business optimization.
Bottom Line
To conclude, building a big data pipeline system is a complex task using Apache Hadoop, Spark, and Kafka. It needs in-depth knowledge of the specified technologies and the knowledge of integration. However, big data pipeline is a pressing need by organizations today, and if you want to explore this area, first you should have to get a hold of the big data technologies.
At Whizlabs, we are dedicated to leveraging technical knowledge with a perfect blend of theory and hands-on practice, keeping the market demand in mind. Hence, we have meticulously selected big data certification courses in our big data stack. You can access from our Hortonworks and Cloudera series of certifications which cover –
HDP Certified Developer (HDPCD) Spark Certification
HDP Certified Administrator (HDPCA) Certification
Cloudera Certified Associate Administrator (CCA-131) Certification
Databricks Certification is one of the best Apache Spark certifications. Explore the world of Hadoop with us and experience a promising career ahead!
Have any questions regarding the big data pipeline? Mention it in the comment box below or submit in Whizlabs helpdesk, we’ll get back to you in no time.
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021

Apache Hadoop, Spark and Kafka are really great tools for real-time big data analytics but there are certain limitations too like the use of database. They are using databases which don’t have transnational data support. For real-time analytics there needs an scalable NoSQL database which have transnational data support.
Hi Deepak..I was building a data pipeline to process the stream data from ibm mq series to spark through kafka…the data will finally reside in hadoop available over hive…o e challange i am facing is in error handing as is the faimed records needs to be persisted so as to make it available in the next run..do you have ideas regarding this?