

Cloud computing has surely changed the world as we know it. However, machine learning is another important topic that is gradually gaining attention. As companies are turning their attention towards the cloud, they also have to focus on responsiveness to customer needs. Therefore, machine learning is quite important for the present times due to the many advantages you can get from it.
Recently we’ve covered an article on introduction to Amazon Machine Learning where we included a bit about AWS SageMaker. AWS SageMaker is a machine learning service; let’s find out more about AWS SageMaker in this article. The discussion would take you through essential aspects of SageMaker, such as its basic definition and how it works. The discussion would also outline the specific procedures for getting started with AWS SageMaker. So, let’s get started with the basics!
Note that if you are preparing for the AWS Machine Learning certification, this knowledge of AWS SageMaker will help you in your AWS Certified Machine Learning Specialty exam preparation.

Amazon SageMaker: What is It?
First of all, many of you might be thinking about Amazon machine learning vs SageMaker. This is where a definition of Amazon SageMaker can introduce some clarity. Amazon machine learning involves the use of multiple AWS resources for identifying patterns in datasets and use them further for developing responsive applications.
On the other hand, AWS SageMaker is a fully managed machine learning service. Data scientists and developers could develop and train machine learning models easily and quickly with the help of SageMaker. Amazon SageMaker also helps in the direct deployment of machine learning models in hosted environments ready for production.
You can find an amazon SageMaker tutorial citing information about the facility of an integrated Jupyter authoring notebook instance. The Jupyter instance helps in access data sources easily for flexible exploration and analysis. As a result, there is no need for managing servers. While defining Amazon SageMaker, let us take a look at another aspect of Amazon machine learning vs. SageMaker.
You can find common machine learning algorithms in SageMaker with the right optimization to deal with excessive data volumes. SageMaker offers adequate support in a distributed environment natively for bring-your-own-algorithms and frameworks. Amazon SageMaker also claims better efficiency with its flexible distributed training options tailored to particular workflows.
Working of Amazon SageMaker
Now that we have explored the basic definition of AWS SageMaker, let us move towards describing how it works! As we all know, Amazon SageMaker is ideal for quick and easy integration of machine learning models in applications. Let us find out how machine learning works with SageMaker according to information from AWS SageMaker documentation.
The discussion would explain the working of Amazon SageMaker in four distinct sections. The first section would deal with the working of machine learning with Amazon SageMaker. The next section would relate to exploring and preprocessing data while the following section would deal with training ML models. The final aspect would involve an illustration of methods for deploying an ML model using AWS SageMaker.
From giving global recognition to providing higher paychecks, an AWS FOUNDATION CERTIFICATION offers a number of benefits. Check out the top benefits of AWS certification that can bring your career one level up.
The basic outline of the machine learning workflow
Every amazon SageMaker tutorial would deal with machine learning at the basic level. Let us find out the basic workflow for creating a machine learning model. Then, we can proceed towards using SageMaker for creating the models. Machine learning involves teaching or instructing a computer to make predictions. First of all, you implement an algorithm and example data for training a model.
Then, you can integrate the model into an application for developing inferences in real-time. A model has to learn from multiple example data items which could be millions in number in general production environment. Also, the machine learning model produces observations within a small time-gap of 100 milliseconds to less than 20 milliseconds. So, let us plan out the machine learning workflow to understand how AWS SageMaker works!
-
Generating example data
The first step in machine learning involves generation of example data. Example data is mandatory for training an ML model. The example data depends on the business problem that is the objective of the model. Therefore, data scientists invest considerable efforts in exploring and preprocessing example data. The process is also known as wrangling of example data and is mandatory before using the data for model training.
You can refer to AWS SageMaker documentation to find three distinct steps in generating example data. First of all, you have to fetch the data through publicly available datasets or in-house example data repositories. You have to pull all the datasets into a single repository. The next step in generating example data involves cleaning the data after a thorough inspection. Data cleaning is highly crucial for ensuring improved model training.
The final step in generating example data involves preparing or transformation of the data. You have to conduct additional data transformations for performance improvement, such as a combination of attributes. In the case of AWS SageMaker, you can use Jupyter notebook in a notebook instance for preprocessing example data. The notebook is ideal for fetching, exploring, and preparing a dataset for model training.
-
Training ML Models
The next important aspect in AWS SageMaker machine learning is training a model. You need to focus on the evaluation of the model in this stage. The training of a model involves an algorithm, and the selection of the algorithm involves different factors. Amazon SageMaker provides in-built algorithms that you can use effectively.
Another important requirement for training the ML model refers to compute resources. The size of the training dataset and the desired speed of results helps in determining the requirement of resources. The next important aspect also accounts as a formidable aspect in Amazon machine learning vs. SageMaker which deals with evaluation.
After finishing the AWS online training of the model, you have to evaluate the model for testing the accuracy of the inferences. The AWS SDK for Python (Boto) or high-level Python library in SageMaker help in sending requests for inferences to model. Jupyter notebook helps in training and evaluation of the model.
-
Deploying an ML Model
The final aspect in Amazon SageMaker is deploying the model. Generally, you would re-engineer a model before integration with an application and deploying it. Amazon SageMaker hosting services help in independent deployment of a model without any association with application code.
You have to note that machine learning is a continuous process. Deployment of a model followed by monitoring of inferences, collection of ground truth, and evaluation of a model for drift identification. Following that, you can increase the accuracy of inferences through updating training data and including new ground truth. The new ground truth is involved in the update of training data through retraining of the model with the new dataset. With the increasing availability of example data, retraining model has to be repetitive for better accuracy.
Connecting with AWS experts can help you resolve your queries and give answers to your questions. Follow these Top AWS Influencers on Quora and clear all your doubts.
Machine Learning with AWS SageMaker
Now that we have explored the basic workflow of machine workflow let us observe AWS SageMaker in action! So, let’s have a look and understand the concept of machine learning with SageMaker.
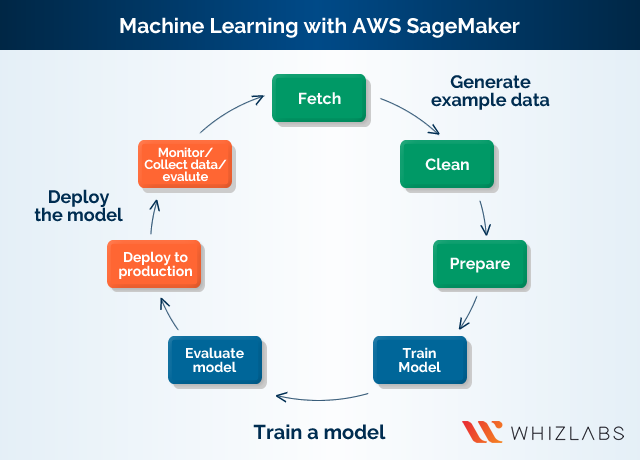
-
Data Preprocessing with SageMaker
The first thing we look at is exploring or preprocessing data using SageMaker. Data preprocessing involves methods. The first method involves using a Jupyter notebook on SageMaker notebook instance.
The notebook instance is ideal for writing code to create model training jobs and to deploy models to SageMaker hosting. The notebook instance also helps in testing and validating your models. Amazon SageMaker batch transform is also an ideal approach for using a model to transform data.
-
Training the ML Model with SageMaker
The comprehensiveness of each step in the use of SageMaker validates amazon SageMaker pricing. The second step in machine learning with SageMaker, after generating example data involves training a model. The first step in training a model involves the creation of a training job. The training job contains specific information such as the URL of Amazon S3, where the training data is stored. Also, training job contains information on the URL of the S3 bucket selected for storing the output.
The training job also contains compute resources ideal for model training. Generally, the compute resources are ML compute instances subject to management by Amazon SageMaker. Most important of all, the training job also includes the Amazon Elastic Container Registry path that stores the training code.
Training a model with Amazon SageMaker involves different options. The first option is to use Amazon SageMaker algorithms or using Apache Spark with SageMaker. You can also use custom algorithms or submit a custom code for training with deep learning frameworks. You could also use algorithms available for subscription on the AWS marketplace.
-
Deploying the Model Using SageMaker
The final stage in our discussion is here! Now, we can learn about deploying a machine learning model in Amazon SageMaker. After the model training process, the deployment can follow two ways. The first route involves establishing a persistent endpoint for obtaining one prediction at a time through SageMaker hosting services.
SageMaker batch transform is ideal for obtaining predictions from an entire dataset. Another important factor which we should not miss out in this introductory discussion for SageMaker is amazon SageMaker pricing. You should note that billing for training and hosting depends on minutes of usage without upfront commitments or minimum fees. It’s not free!

Final Words
On a concluding note, AWS SageMaker is all set to revolutionize the world of computing in the future. The sheer productivity of applications in machine learning will create new prospects for adoption of ML services such as SageMaker. The discussion presented a detailed overview of Amazon SageMaker as an ML service. It is a fully managed service and is designed for developing, training, and deploying machine learning models.
Machine learning is the future of application development. The next important concerns in the discussion were the machine learning workflow and how SageMaker fit into the cast. We were able to learn the importance of preprocessing data and the steps involved in training and deploying models. So, let’s get started right away with machine learning on Amazon SageMaker!
Want to validate your skills on AWS Machine Learning? Prepare yourself for the AWS Certified Machine Learning exam and get ahead towards a better career!
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024
