

Big Data and Cloud Computing combination is the latest trend nowadays, and Hadoop is another name for Big Data. So, it’s the right time to understand the enabling of Apache Hadoop in Cloud Computing.
Hadoop has spawned the foundation for many other big data technologies and tools. When industries need virtually unlimited scalability for large data, Hadoop supports a diverse range of workload types. However, with the exponential growth of big data, storage cost and maintainability is a prime question considering the budget of the companies.
Are you a fresher who wants to start a career in Big Data Hadoop? Read our previous blog on how to start Learning Hadoop for Beginners.
Hence, Apache Hadoop in Cloud computing is the latest trend that today’s industry follow. Big data processing on cloud platforms is especially effective for scenarios where an enterprise wants to save the cost by accelerating the analytic jobs for faster results to bring down the cluster.
In this blog, we will discuss how we can enable Apache Hadoop in Cloud computing instance.
Key considerations for Enabling Apache Hadoop in Cloud Computing Environment
Before you configure Apache Hadoop environment in the cloud below points should be measured:
- Security in the public cloud is a concern for Apache Hadoop cloud deployment. Hence, every enterprise must evaluate the security criteria before moving Hadoop cluster data as Hadoop provides very limited security.
- The main purpose of Apache Hadoop is data analysis. Hence, Apache Hadoop in cloud computing deployment must support the tools associated with the Hadoop ecosystem, especially analytics and data visualization tools.
- Data transmission in a cloud is chargeable. Hence, the place from where data is being loaded to the cloud is an important factor. The cost differs in case the data is going to be loaded from an internal system which is not on the cloud or if the data is already in the cloud.
How to Configure Apache Hadoop Environment in the Cloud?
To start with Apache Hadoop cloud configuration, you must have Linux platform installed in the cloud. Here we will discuss how to configure single node cluster of Apache Hadoop in cloud computing using pseudo mode. We have considered AWS EC2 as the cloud environment here.
Pre-requisites to configure Apache Hadoop environment in the cloud
- An AWS account in an active state
- Available private and public keys for the EC2 instance
- Running Linux instance.
- PuTTy installed and set up on the Linux
Want to enhance your enterprise capabilities? Start using Big Data and Cloud Computing together that makes a perfect combination.
Next, to enable Apache Hadoop in Cloud computing environment following steps need to be executed in two phases.
Phase1: Connect to EC2 instance using PuTTy
Step 1: Generate the private key for PuTTy
As you need to connect EC2 instance with PuTTY to configure Apache Hadoop environment, you need a private key for PuTTy which will support AWS private key format (.pem). Using tools like PuTTYyGen we can convert .pem format into the .ppk format which is PuTTY supported. Once the PuTTy private key is generated, using SSH client we can connect to the EC2 instance.
Step2: Start PuTTy session for EC2 instance
Once you start your PuTTy session to connect with EC2, you need to authenticate the connection first. To do so, in the category panel select connection and SSH and then expand it. Next, select Auth and then browse for the .ppk and open it.
Step3: Provide the permission
For the first time user of the instance, it will ask for the permission. Provide the login name as ec2-user. Once you press enter, it will start your session.
Phase 2: Configuring Apache Hadoop in cloud computing
Before you proceed to configure Apache Hadoop environment in EC2 instance make sure you have downloaded the following software beforehand:
- Java Package
- Hadoop Package
Next, follow the below steps:
Step 1: Create a Hadoop User on EC2 instance
You need to add a new Hadoop user in your EC2 instance. To do so, you need to have root access. It can be obtained by using the following command:
![]()
Once you have the root access you can create a new user by using the below command:

Now add a password to the added user

Next to make the new user as sudo user, type visudo and make the entry to visudo file for the user whizlabs below the line “Allow root to run any commands anywhere.”
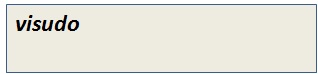
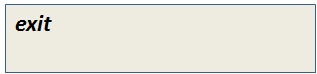
Step 2: Exit from the root
Go back to the EC2 user and log in to the new user by entering the below commands

Step 3: Transfer the Hadoop and Java dump on the EC2 instance
Java should be installed before you install Hadoop on EC2 instance. Hence, you need to copy the downloaded zip versions of Hadoop and Java from Windows machine to EC2 instance using file transfer tools like WinSCP or FileZilla. To copy the files through these tools –
- Launch the tool.
- Enter the hostname and username of the EC2 instance and port number. Here the default port number will be 22.
- Expand the ssh category and authenticate it using the PuTTy private key (.ppk) file.
- Once you are logged in to the EC2 instance locate the Hadoop and Java .zip files from your local system and transfer them.
- Once you get the files available into the instance use the command ls to confirm their availability.
- You need to install Hadoop and Java using the new user you have created for Hadoop. Hence copy the files with the whizlabs user through below commands –


- Next, unzip the files using the below commands
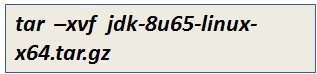

Step 4: Configure Apache Hadoop environment
To set the necessary environment variables for Hadoop and Java, you need to update .bashrc file in the Linux. From /home/whizlabs which is the home directory here type the below command

To enable environmental variable workable use the command
![]()
Step 5: Create NameNode and DataNode directories
Use the below commands for the NameNode and DataNode storage locations:
![]()
![]()
Step 6: Modify the directory permissions to 755
Use the below commands
![]()
![]()
Step 7: Change the directory location to the Hadoop installation directory
Use the below command
![]()
Step 8: Add the Hadoop home and Java Home path in Hadoop-env.sh
Use the below command to open hadoop-env.sh file
![]()
[Update Java classpath and version as per your installed version].
Step 9: Update Hadoop configuration details
Add the configuration properties in the below-mentioned files:
core-site.xml file
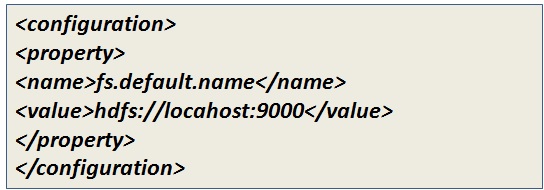
hdfs-site.xml file
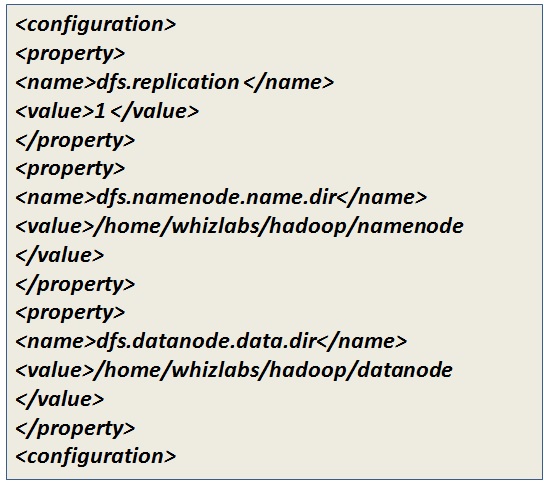
yarn-site.xml

Step 10: Change the configuration properties of mapred-site.xml
Using the below command copy the content of mapred-site.xml template into mapred-site.xml

Add the below property in the file:

Step 11: ssh key generation for the Hadoop user
Follow the below steps for ssh key generations:

Step 12: Format the Namenode
Before you start the daemons, you need to format the namenode and change its location to the Hadoop location using the below commands:

Step 13: Start all the daemons in Hadoop
To bring up Hadoop in the running state you need to start the daemons in the below orders:

And you are all set with Apache Hadoop in the cloud.
Benefits of Apache Hadoop in Cloud Computing
The primary benefit of Cloud computing is – it enables business agility for enterprises, data scientists, and developers with unlimited scalability. It provides effective cost measurement with no upfront hardware costs. Besides that, it is cost-effective as it follows a pay-as-you-go model.
Apache Hadoop in cloud computing leverages many benefits as follows:
1. The scale of data analytics needs
With the enhanced data analysis requirement within the enterprises,7 to expand the capacity of Hadoop clusters is the need of the hour. While setting up the hardware for this could take weeks or months, the deployment in the cloud takes a few days. As a result, overall data processing scales fast and meets the business needs.
2. Lower cost for innovation
To configure Apache Hadoop environment in the cloud is a low capacity investment which does not charge for any upfront hardware cost. Apache Hadoop in cloud computing is specifically an ideal solution for the startups with big data analytics.
3. Pay specific to your need
Apache Hadoop cloud is suitable for the use cases when the requirement is to spin up the job to get the results and then stop or shut down the system. This is a flexible spending feature of the cloud as this only asks to pay for the compute and usage on the go basis.
4. Use the optimum infrastructure for the job
Not all the big data processing needs the same hardware infrastructure as memory, I/O, compute resources, etc. In cloud computing, you can select the suitable instance type for an optimal infrastructure for the solution.
5. Using cloud data as the source
Nowadays with the more usage of IoT and cloud, most enterprises prefer to store data in the cloud making it the primary source of data. As big data is all about large volumes of data, Apache Hadoop in cloud computing makes a lot of sense.
6. Makes your operations simple
The cloud computing technology provisions various types of clusters of Apache Hadoop with different characteristics and configurations, which is suitable for a particular set of jobs. This lowers the burden of administrative tasks for an enterprise from managing multiple clusters or implementing multi-tenant policies.
Final Verdict
To conclude, setting up Apache Hadoop in cloud computing requires hands-on skills on both Apache Hadoop and AWS. You must be comfortable and aware of both the technologies and techniques.
Whizlabs leverages the best level of theoretical and hands-on knowledge through its Hadoop certification training and Cloud Computing Certification training. Browse through our courses and build up your technical ground with us!
Have any questions? Just mention in the comment section below or submit here, we’ll be happy to respond back.
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
