

Choosing a programming language over another in the big data field is very much project specific and depends on the project goal. However, whatever may be the goal Python and Big Data is an inseparable combination when we consider a programming language for big data development phase.
It is a crucial decision because once you start developing your project in a language, it is difficult to migrate in another language. Moreover, not all big data projects have the same goal. For example, in a big data project, the goal may be simply manipulating data or building analytics while in others it could be for the Internet of Things (IoT).
Also CHECK: Python for Beginners – A detailed Course with FREE hands-on labs
Furthermore, Python is not limited to big data only and widely used in other technical fields as well which adds its usefulness. IEEE Spectrum has also ranked Python as the number one programming language. In this blog, we will discuss on few reasons why Python and Big Data combination is a favorite choice for big data professionals.
Python and Big Data: A Perfect Combination
Python is a general-purpose programming language that enables programmers to write fewer lines of code and make it more readable. It has scripting features and besides that uses many advanced libraries such as NumPy, Matplotlib, and SciPy which makes it useful for scientific computing.
Python is an excellent tool and a perfect fit as a python big data combination for data analysis for the below reasons:
-
Open-source
Python is an open-source programming language that is developed using a community-based model. It can be run on Windows and Linux environments. In addition to that, you can port it to other platforms as it supports multiple platforms.
-
Library Support
Python is widely used for scientific computing in both academic and multiple industry fields. Python consists of a large number of well-tested analytics libraries which include packages like
- Numerical computing
- Data analysis
- Statistical analysis
- Visualization
- Machine learning
-
Speed
As Python is a high-level language, it has many benefits which accelerate the code development. It enables prototyping ideas which makes coding fast while maintaining the great transparency between code and its execution. As a result of the code transparency both the maintenance of the code and the process of adding it to the code base in a multi-user development environment becomes easy.
-
Scope
Python is an object-oriented programming language which also supports advanced data structures such as lists, sets, tuples, dictionaries and many more. It supports many scientific computing operations like matrix operations, data frames, etc. These abilities within the Python enhance the scope to simplify and speed up data operations.
-
Data Processing Support
Python provides advanced support for image and voice data due to its inbuilt features of supporting data processing for unstructured and unconventional data which is a common need in big data when analyzing social media data. This is another reason for making Python and big data useful to each other.
Also Read : Top Python Interview Questions and Answers | 2023
5 Reasons why Python is Perfect-fit for Big Data
Python is considered as one of the best data science tool for the big data job. Python and big data are the perfect fit when there is a need for integration between data analysis and web apps or statistical code with the production database. With its advanced library supports it helps to implement machine learning algorithms. Hence, in many big data aspects, Python and big data complement each other.
1. It’s a bag of powerful scientific packages
Python big data combination is backed by its robust library packages which fulfill analytical and data science needs and makes it a popular choice in big data applications.
Some of its popular libraries which make Python and big data useful together are:
-
Pandas
Pandas is a library which helps in data analysis. Besides that, it provides the required data structure and operations for data manipulation on time series and numerical tables.
-
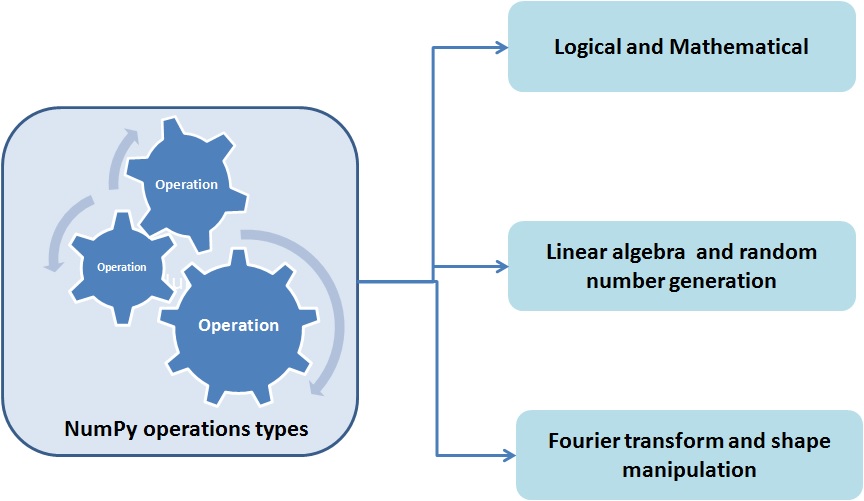
NumPy
NumPy is the fundamental package of Python which makes possible scientific computing. It provides the support for linear algebra, random number crunching, Fourier transforms. Also, it supports multi-dimensional arrays, matrices with its extensive library of high-level mathematical functions.
-
SciPy
SciPy is a widely used library in Big data for scientific and technical computing. SciPy contains different modules for
- Optimization
- Linear algebra
- Integration
- Interpolation
- Special functions
- FFT
- Signal and image processing
- ODE solvers
- Other tasks common in science and engineering
-
Mlpy
Mlpy is a machine learning library which works on top of NumPy/SciPy. Mlpy provides many machine learning methods for problems and helps to find a reasonable compromise between modularity, reproducibility, maintainability, usability, and efficiency.
-
Matplotlib
Matplotlib is a python library which helps in 2D plotting for hardcopy publication formats with an interactive environment across platforms. Matplotlib allows generating plots, bar charts, histograms, error charts, power spectra, scatter plots, and more.
-
Theano
Theano is a Python library for numerical computation. It allows optimizing, defining and makes it possible to evaluate mathematical expressions which could involve multi-dimensional arrays also.
-
NetworkX
NetworkX is a library for studying graphs which helps you to create, manipulate, and study the structure, dynamics, and functions of complex networks.
-
SymPy
SymPy is an effective library for symbolic computation which includes features like –
- Basic symbolic arithmetic
- Calculus
- Algebra
- Discrete mathematics
- Quantum physics.
- Computer algebra capabilities in different formats like as a standalone application, or as a library to other applications, or live application on the web.
-
Dask
Dask is a Python big data library which helps in flexible parallel computing for analytic purpose. From the big data perspective, it works with big data collections like data frames, lists, and parallel arrays or with Python iterators for larger than the memory in a distributed environment.
-
Dmelt
Dmelt or DataMelt is a Python-based library or software which is used in big data analysis for numeric computation and statistical analysis of big data and its scientific visualization.
-
Scikit-learn
scikit-learn is a machine learning library which complements NumPy and SciPy libraries. It has various features like –
- Regression
- Clustering algorithms for vector machines, gradient boosting, random forests-means and DBSCAN,
- Interoperates with the Python libraries like NumPy and SciPy.
-
TensorFlow
TensorFlow is an open-source software library supported by Python for machine learning for a range of tasks. The library is capable of building and training neural networks to
- Detect patterns
- Decipher patterns
- Correlations
- Analogous for the purpose of learning and reasoning.
Python with the libraries mentioned above makes big data scientists’ life easy. For example, with Python library integration with Spark and Scikit-learn data scientists can write code and test with small data sets before it is implemented on Spark cluster. Once the code is verified and works with its desired functionality, they can implement the same on the Spark cluster with a large set of data. This helps to escape them from repetitive code cycles and accelerate business decisions.
There are a number of myths all around regarding Big Data. Let’s go through some common Big Data Myths and Facts behind them.
To use any library, scientists need to search online by tagging ‘Python + [required analytics tool].’ This shows up the testing code with the analytics and required documentation for it along with examples as guidance.
2. Compatible with Hadoop
Hadoop is one of the best Big data tools. As Python big data is compatible, similarly Hadoop and big data are synonymous with each other. Hence, Python has been made inherently compatible with Hadoop to work with big data. Python consists of Pydoop package which helps in accessing HDFS API and also writing Hadoop MapReduce programming. Besides that Pydoop enables MapReduce programming to solve complex big data problems with minimal effort.
3. Easy to Learn
Python is easy to learn as it abstracts many things with its features. As a result, user needs to code fewer lines of code. Besides that it has scripting feature as well. Python is coupled with user-friendly features like code readability, simple syntax, auto identification and association of data types and easy implementation.
4. Scalability
Scalability matters a lot when you are dealing with massive data. Unlike other data science languages like R, MatLab or Stata, Python is much faster. Though there was initial complain about its speed, however, with Anaconda its speed performance has enhanced a lot. This makes Python and big data compatible with each other with a greater scale of flexibility.
5. Large Community Support
Big data analysis often deals with complex problems which need community support for solutions. Python as a language has a large and active community which helps data scientist and programmer with expert support on coding related issues.This is another reason for its popularity.
Preparing for a Big Data interview? Just follow this Big Data Interview Preparation guide and be confident to crack the interview.
Final Words
To conclude, Python and big data together provide a strong computational capability in big data analysis platform. If you are a first-time big data programmer, no doubt it is easy to learn for you than Java or other similar programming languages. Besides that, if you want to pursue Hortonworks or Cloudera big data certifications, this is a prerequisite to learn either Scala or Python.
At Whizlabs besides providing certification guides on Hortonworks HDPCD certification and Cloudera CCA 131 certification, we can help you to ramp up on Python.
Join us today to be expert on Python and big data!
Still, have any question in your mind? Just put a comment below or write here, we’ll respond back in no time..
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021

Very Impressive Python tutorial. The content seems to be pretty exhaustive and excellent and will definitely help in learning Python. I’m also a learner taken up Python training and I think your content has cleared some concepts of mine.
Really Thanks for this blog. It helped me a lot to clear my mind regarding choosing the correct technology. please posing blogs like this. God bless you. Thanks a lot.
Thanks for sharing a very Nice Post and its really helpful
I like this blog its a master peace ! .