

Many new terms emerge every day in the technological landscape, which present new opportunities for businesses. The birth of serverless architecture is also one of the notable technological innovations in recent times. It is important to note that serverless is a rapidly escalating trend in the cloud computing arena.
According to a 2018 report, almost 46% of IT decision-makers are using and reviewing serverless computing. Another 35% of the IT decision-makers focus on evaluating the implications with serverless computing. In addition, almost 39% of IT decision-makers use a combination of PaaS, serverless technologies, and containers. Among the respondents, 42% report that they use a combination of serverless and containers and 43% report using a combination of serverless and PaaS.
The following discussion would dive into answers for ‘what is serverless architecture’ in detail. The important highlights of the discussion include an in-depth reflection on the difference between server and serverless architecture and other aspects. The other aspects include patterns in serverless computing architecture, features of serverless computing, and different use cases. Furthermore, the discussion would also present a brief outline of the advantages and setbacks associated with serverless computing architecture.
Millions of cloud professionals have enhanced their career with Whizlabs Cloud Computing Certifications training courses and practice tests. Check now!
Why serverless?
Let’s wind back our clocks a bit! Before the existence of the cloud, servers were the most crucial concern for developers in building software or applications. The costs and efforts for procuring servers and establishing them alongside the maintenance requisites were highly intensive for enterprises. With the entry of the cloud, enterprises did not have to worry anymore about the resources and higher operational costs. So, the necessity for serverless architecture becomes quite evident in such scenarios. The cloud is not anymore about backend services. Now, applications are just loosely coupled components on the cloud, and a major share of processing happens outside an application’s framework.
Defining serverless
Many misconceptions arise regarding the response to ‘what is serverless architecture.’ Various people assume that serverless means the lack of any server involvement. On the contrary, serverless computing actually means that developers don’t have to focus on server management anymore. As a result, developers don’t have to invest efforts in implementation, maintenance, debugging, and monitoring of the infrastructure. Subsequently, developers could focus extensively on the business goals intended by the applications. The popularity of serverless architecture is rightly visible in its adoption by various big names in the contemporary business environment. Netflix, AOL, and Reuters are some of the names that have boarded the serverless bandwagon.
Now, we have a frail bit of clarity regarding the basic nature of serverless computing architecture. So, what exactly is serverless computing? Basically, serverless architecture is a cloud computing execution model that involves dynamic management of server allocation and provisioning by the cloud provider. Serverless applications run on stateless compute containers that are ephemeral and event-triggered. Serverless applications last only for one invocation, and the cloud provider fully manages them.
The architecture of serverless applications draws our attention towards a notable term, i.e., “Functions as a Service (FaaS).” Serverless applications depend on a combination of client-side logic, third-party services, and cloud-hosted remote procedure calls. Some of the notable cloud services with serverless computing abilities include AWS Lambda, Azure Functions, Google Cloud Functions, IBM OpenWhisk, and Auth0 Webtask.
2020 is expected to bring new trends and changes in the world of cloud computing. Let’s have a look at the emerging cloud cloud trends 2020.
Understanding FaaS
Did we miss out on something till now? In the previous paragraph, we came across the term “Function as a Service” (FaaS), didn’t we? Well, let’s just say that FaaS is an implementation of serverless architectures! FaaS allows the deployment of individual functions or a part of business logic. FaaS start within milliseconds alongside providing the benefit of processing individual requests within a 300-second timeout. An outline of the key features of FaaS could help us in enriching our knowledge about serverless architectures further.
However, what is the principles on which FaaS works? The first principle of FaaS directly implies the complete management of servers. The second principle of FaaS focuses on invocation-based billing. The third and final principle of FaaS refers to event-driven nature and instantaneous scalability. The following properties of Function as a Service (FaaS) can explain further about the comprehensiveness of serverless computing.
- The independent, server-side, logical functions help in arranging different units of logic for taking input arguments, operating on the output, and presenting the final output.
- The serverless architecture is unique because of the stateless nature. As a result, two invocations of the same function would execute on two different containers.
- FaaS design also involves functionalities for starting up quickly and shutting down immediately.
- The triggering of functions by events from other cloud services is a promising aspect for assuming FaaS as the glue for holding different services in a cloud environment together.
- In addition, FaaS also delivers the benefit of scalability by default. The initialization of multiple containers with stateless functions can help in allowing multiple functions to run for addressing incoming requests.
Furthermore, the popular FaaS solutions such as AWS Lambda, Google Cloud Functions and more provide the advantage of full management by the cloud provider.
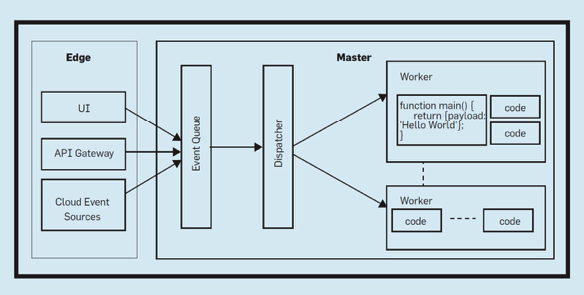
Differences between server and serverless
The functionalities of serverless architecture definitely present favorable propositions for enterprises. However, there are some cases in which serverless does not find any promising outcomes. Therefore, it is essential to understand the difference between server and serverless for finding out the suitable applications of serverless.
Here is a comparison of server and serverless on the basis of various criteria.
1. Cost
The serverless architecture provides a much-needed advantage in the form of cost reduction. As a result, you don’t have to worry about the costs of provisioning and maintaining servers round the clock. Serverless computing billing follows the number of executions. Users get a specific number of seconds for use that differs on the basis of memory capacity required. Similarly, the pricing for every millisecond (MS) varies according to the amount of required memory capacity. Shorter running functions can align effectively with this model having a peak execution time of 300-second.
2. Networking
In terms of networking, serverless computing as a disadvantage. The access to serverless functions only as private APIs requires setting up an API Gateway. As a result, you have an additional roadblock in accessing serverless functions. Therefore, server architecture tends to emerge as a winner here!
3. Dealing with external dependencies
The majority of projects have external dependencies in the form of libraries with functionalities. The functionalities can include image processing, cryptography, and others. Therefore, the libraries become extremely heavy. Lack of system-level access clearly shows that all dependencies should be in the application packaging. So, serverless architecture is ideal for simple applications having limited dependencies. For the case of complex applications, traditional architecture serves as the best bet!
4. Available environments
Serverless is better than server architecture due to the flexibility of establishing different environments easily. Users don’t have to invest efforts in setting up machines for development, staging, and production.
5. Time
The 300-second timeout limit in serverless computing is a huge setback. As a result, highly complex and long-running functions are not ideal for serverless. On the other hand, this setback works in favor of certain examples of serverless applications. The applications under concern, in this case, have different execution times. Furthermore, specific services that demand information from external sources could also be ideal for leveraging the hard timeout limit.
6. Scalability
Another point of difference between serverless and server is the scaling capabilities of the former. Different examples of serverless applications, such as message-driven apps, clearly show that the scaling process is seamless and automatic. However, scalability benefits with serverless come at a price! Users can perceive a lack of control with a serverless scaling process. Therefore, we can clearly note that servers and serverless have their fair share of advantages and cons. The choice of either depends on the use case or the business objectives in concern.
The combination of AI and cloud computing brings favourable outcomes for the business growth. Here we bring the top benefits of using AI in cloud computing!
Serverless Design Patterns
Among all the attention surrounding serverless architecture, it is also important to think of microservices. Microservices serve as one of the foundation elements of cloud computing. The division of large monolithic developments into smaller components known as microservices establishes the foundation of developing applications or software on the cloud. The observation of design trends in microservices can help in understanding serverless architecture patterns.
The following architecture patterns could help in understanding the serverless paradigm in detail:
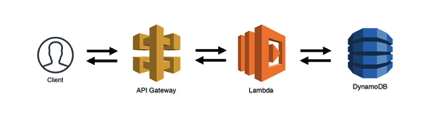
1. Simple Web Service
The simple web service is one of the basic design patterns that are evident in serverless applications. The following image depicts the structure of the simple web service pattern.
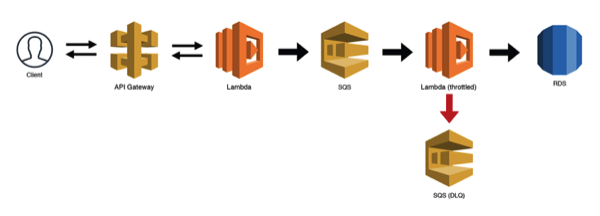
2. Scalable Webhook
The scalable webhook is the second type of common pattern you can find in various serverless use cases. The scalable webhook design is appropriate for Lambda function.
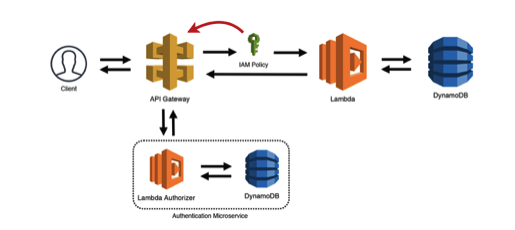
3. Gatekeeper Pattern
The Gatekeeper pattern is an improvement over the simple web service pattern. The pattern uses ‘Lambda Authorizers’ of the API Gateway for connecting a Lambda function with the “Authorization” header. Then, the API Gateway uses the policy for determining its validity for the resource. In this pattern, the API Gateway also caches the IAM policy for a particular period of time. Therefore, this pattern is also known as the ‘Valet Key’ pattern.
4. Internal API
Another prominent mention among serverless architecture patterns is the Internal API. The internal API is generally a web service that does not have an API Gateway frontend. This pattern is applicable only in scenarios where the access to microservice is possible only within the cloud provider’s infrastructure.
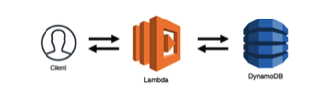
Use cases of serverless computing
The most crucial aspect of this discussion on serverless architecture refers directly to the use cases. As of now, serverless computing has been a vital ingredient in the success of many applications. Serverless provides the flexibility to use serverless and traditional architectures in combination or interchangeably. In practical use cases, non-functional requirements such as cost required degree of control over operations, and application workload characteristics determine the choice of serverless. In terms of cost considerations, serverless computing is ideal for applications having burst workloads. A closer reflection on practical examples of serverless use cases could support our impression of the functionalities of serverless.
- The Coca-Cola Company uses serverless for reducing IT operational costs and faster deployment of services. The most notable use case of serverless for Coca-Cola is the implementation of serverless in its vending machine and loyalty program. As a result, Coca-Cola achieved 65% cost-savings at an average of 30 million hits per month.
- Aegex utilizes serverless for the Xamarin application. Customers can use Xamarin applications for monitoring real-time sensor data from IoT devices.
- Expedia is also another prominent name among use cases of serverless. With over 2.3 billion Lambda calls per month in December 2016 and 6.2 billion requests in 2017, Expedia continues to reap the benefits of serverless. The prominent areas of application for serverless in Expedia’s use case include infrastructure governance and autoscaling. In addition, Expedia also uses serverless for the integration of events for its CI/CD platforms.
- A Cloud Guru uses functions of serverless for performing operations such as triggering group emails and payment processing. As of 2017, the total cost for the delivery of a video course to a user was $0.14.
Apart from these use cases, serverless architecture also finds prominent applications in event-driven applications with flow-like processing patterns. Serverless is also ideal for controlling data flow between two services and simplification of client-side code. Another potential area of application for serverless is clearly evident in the field of scientific computing.
Cloud computing has been a revolutionary technology for businesses. Let’s have a look at the benefits of cloud computing for businesses!
Conclusion
Therefore, a thorough observation of different implications with serverless clearly shows promising opportunities ahead. The future of serverless architecture in the coming years would have to focus on the limitations for capitalizing on opportunities. Let us close this discussion by pointing out the challenges and research opportunities with respect to serverless computing. The programming model in serverless involves multiple functions, thereby creating issues for the identification of bottlenecks and debugging. Furthermore, the application of traditional tools for monitoring and debugging is not valid for serverless applications. So, the need for new tools and approaches becomes essentially evident here!
The possible improvements in this regard may include an extension of the platform with various recovery semantics such as atomicity in the case of serialized function executions. Another prominent setback for serverless is the lack of standards and concerns pertaining to vendor lock-in. Since serverless and FaaS are comparatively new terms in the cloud landscape, there are no specific standards. With the gradual progress in the domain of serverless, new improvements are definitely in order!
Thinking to build your career in cloud computing or aspiring to take your cloud career one level up? Choose a cloud computing certification and join us to get high-quality cloud certification training courses for your preparation.
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024
How to Deploy Microservices with Serverless Architecture?
https://www.decipherzone.com/blog-detail/microservices-serverless-architecture
Businesses around the world are moving away from large and complicated monolithic applications to more flexible systems that can adapt according to the changing needs of the market – Microservices.