

Apache HBase is the open source, non-relational, distributed database in the Hadoop ecosystem. HBase interview questions constitute a considerable part of the Hadoop interview. In this article, we’ll cover some basic and advanced HBase interview questions.
As Hadoop development deals with a lot of database related activities for database sourcing and writing, knowing at least one database skill is essential for the Hadoop developers.
Preparing to become a certified Hadoop professional? Start preparation and get hands-on with our online courses for Hortonworks HDPCA Certification and Cloudera CCA Admin Certification.
Additionally, enterprises prefer to select a non-relational database, and HBase is the perfect one for Hadoop considering many of its features. Hence, facing HBase Interview Questions in any Hadoop job interview is a common phenomenon that every Hadoop professional use to face.
Hence, if you are looking for a portal that will help you to guide for the right set of HBase Interview Questions then you are at the right place! In this blog, we will discuss on some important and top HBase Interview Questions and answers, as well as HBase advanced interview questions which are common in the industry.
Top HBase Interview Questions and Answers
1. What do you know about Apache HBase?
Answer: Apache HBase is the open source Hadoop based non-relational, distributed, database management system. It is ideal for hosting large tables consists of a large number of rows and columns on top of a set of clustered commodity hardware. Moreover, it is the versioned and real-time database that gives the user read/write access. HBase has features like –
- Modular and linear scalability.
- Maintains strict and consistent reads/writes.
- Configurable and automatic sharding of tables
- Automatic support against failover between Region Servers.
- Base classes support to back up Hadoop MapReduce jobs with Apache HBase tables.
- User accessible Java API for client access.
- Bloom Filters and Block cache for real-time queries.
- Server-side filters for query predicate push down
- Thrift gateway with REST-ful Web service to support XML, binary data encoding, and Protobuf.
- An extensible shell which is JRuby-based.
- It supports exporting metrics using the Hadoop metrics subsystem to Ganglia or files or via JMX.
2. What are the different operational commands used in Apache HBase?
Answer: These are: Put, Get, Delete, last, Scan and Increment.
Also Read: Must Read Top 50 Hadoop Interview Questions with Detailed Answers
3. What are the best reasons to choose HBase as DBMS for Hadoop?
Answer: Some of the properties of Apache HBase make it the best choice as DBMS for Hadoop. Here are some of them –
- Scalability
- It is ideal for handling large tables which can fit billions of rows and columns
- Users can read/write on the database on a real-time basis.
- Compatible with Hadoop as both of them are Java based.
- Vast operational support for CRUD operations.
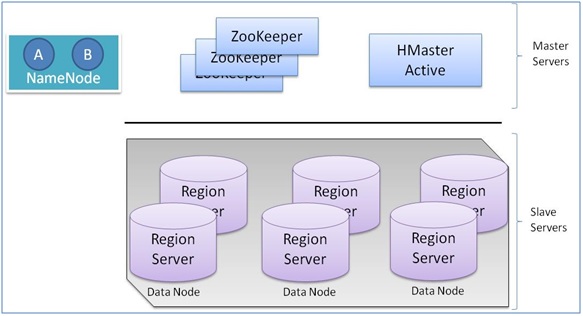
4. What are the different key components of HBase?
Answer: HBase key components are –
- Regions- These are horizontally divided rows of HBase table. This component of HBase contains Hfile and memory data store.
- Region Server-This component monitors the Regions.
- HBase Master or HMaster-This component is responsible for region assignment and also monitors the region server.
- Zookeeper- It acts as the distributed coordination service between the client and HBase Master component and also maintains the server state in the cluster. It monitors which servers are available and alive. In addition to that,it notifies when a server fails to perform.
5. What is Row Key?
Answer: RowKey is a unique identifier in an HBase which is used to logically group the table cells to ensure that all cells with the similar RowKeys are placed on the same server. However, internally RowKey is a byte array.
6. What are the differences between RDBMS and HBase table?
Answer:
- RDBMS is schema-based database whereas HBase is a data model which is does not follow any schema.
- RDBMS supports in-built table partitioning, but HBase supports an automated partitioning.
- RDBMS stores data in normalized format whereas HBase stores de-normalized data.
7. What do you mean by WAL?
Answer: WAL stands for Write Ahead Log. This HBase log records all the changes in the table data irrespective of the mode of change. This log file itself is a standard sequence file. The main utility of this file is to provide data access to the users even after the server crash.
8. What are the different catalog tables in HBase?
Answer: There are two main catalog tables in HBase which are ROOT and META. The purpose of the ROOT table is to track META table, and the META table is for storing the regions in HBase system.
Are you a fresher aspired to make a career in Hadoop? Read our previous blog that will help you to start learning Hadoop for beginners.
9. What are the tombstones markers in HBase and how many tombstones markers are there in HBase?
Answer: When a user deletes a cell in HBase table, though it gets invisible in the table but remains in the server in the form of a marker, which is commonly known as tombstones marker. During compaction period the tombstones marker gets removed from the server.
There are three tombstones markers –
- Version delete
- Family delete
- Column delete
10. Mention about a few scenarios when you should consider HBase as a database?
Answer: Here are a few scenarios –
- When we need to shift an entire database
- To handle large data operations
- When we need frequent inner joins
- When frequent transaction maintenance is a need.
- When we need to handle variable schema.
- When an application demands for key-based data retrieval
- When the data is in the form of collections
11. What is the difference between HBase and Hive?
Answer: Apache HBase and Apache Hive have a quite very different infrastructure which is based on Hadoop.
- Apache Hive is a data warehouse that is built on top of Hadoop whereas Apache HBase is a data store which is NoSQL key/value based and runs on top of Hadoop HDFS.
- Apache Hive allows querying data stored on HDFS via HQL for analysis which gets translated to MapReduce jobs. On the contrary Apache HBase operations run on a real-time basis on its database rather than as MapReduce jobs.
- Apache Hive can handle a limited amount of data through its partitioning feature whereas HBase supports handling of a large volume of data through its key/value pairs feature.
- Apache Hive does not have versioning feature whereas Apache HBase provides versioned data.
13. Name some of the important filters in HBase.
Answer: Column Filter, Page Filter, Row Filter, Family Filter, Inclusive Stop Filter
Preparing for a Hadoop interview? Also, go through these HDFS interview questions to prepare well.
14. What is the column family? What is its purpose in HBase?
Answer: Column family is a key in HBase table that represents the logical deviation of data. It impacts the data storage format in HDFS. Hence, every HBase table must have at least one column family.
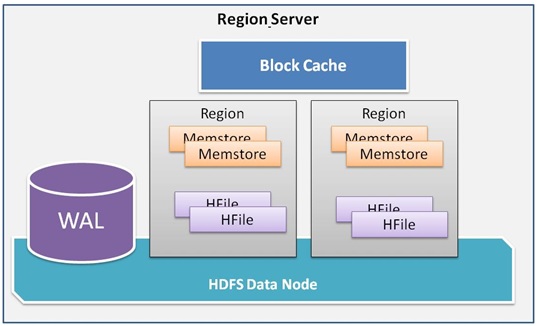
15. What is MemStore?
Answer: The MemStore is a write buffer used in HBase to accumulate data in memory before its permanent write. When the MemStore fills up with data, the contents are flushed to disk and form a new Hfile. There exists one MemStore per column family.
16. What is HFile?
Answer: The HFile is the HBase underlying storage format. Each HFile belongs to a column family whereas a column family may have multiple HFiles. However, a single HFile never contain data for multiple column families.
17. What is BlockCache?
Answer: HBase BlockCache is another data storage used in HBase. It is used to keep the most used data in JVM heap. The main purpose of such data storage is to provide access to data from HFiles to avoid disk reading. Each column family in HBase has its own BlockCache. Similarly, each Block in BlockCache represents the unit of data whereas an Hfile is a sequence of blocks with an index over those blocks.
HBase Advanced Interview Questions and Answers
18. How is data written into HBase?
Answer: Data is written into HBase following several steps. First, when the user updates data in HBase table, it makes an entry to a commit log which is known as write-ahead log (WAL) in HBase. Next, the data is stored in the in-memory MemStore. If the data in the memory exceeds the maximum value, then it is flushed to the disk as HFile. Once the data is flushed users can discard the commit logs.
19. What are the different compaction types in HBase?
Answer: There are two types of compaction:
- Major compaction – Here all the column based HFiles are emerged to create a single HFiles. Once the HFiles are deleted, they are discarded
- Minor compaction– In this case, a single Hfile is created by merging many adjacent small HFiles. The small files are chosen randomly.
20. Can you perform iteration through the rows in HBase? Explain.
Answer: Yes, we can perform iteration through the rows provided the task is not performed in reverse order. As HBase stores column values on a disk, the length must be defined correctly and the values must be written after it. Hence, if we want to perform the iteration in reverse order, we need to store the values one more time which is a compatibility and memory issue of HBase.
Preparing a for Hadoop Developer interview? Understand the Hadoop Developer Job Responsibilities first.
21. How HBase handles the write failure?
Answer: Failure is common in a large distributed system like HBase. However, we can safeguard against data failure using HBase Write Ahead Log (WAL). Every server which belongs to the HBase cluster maintains a WAL to record the changes that happen in HBase data. Unless a new entry in WAL is written against each write, it will not be considered as successful. Furthermore, HBase is supported by the Hadoop Distributed Filesystem (HDFS). Hence, if HBase goes down, the unflushed data from the MemStore will be recovered by using the WAL.
22. While reading the data from HBase, from which three places data will be reconciled before returning the value?
Answer:
1. MemStore: It is the first place to check if there is any pending modification in the system.
2. BlockCache: This is to verify whether the block has been recently accessed.
3. HFiles: Relevant HFiles on disk.
23. When would you not want to use HBase?
Answer:
- When the data access patterns are sequential over immutable data.
- When data is not large.
- When we can use alternative such as Hive.
- When we really require a relational query engine or a normalized schema.
Conclusion
Hope the above mentioned HBase interview questions will help you to prepare for the Hadoop interview. However, to begin with, HBase interview questions, first, you have to know Hadoop. Hence, we highly recommend you to achieve a solid base for Hadoop to relate HBase with the technology. Moreover, your knowledge will help you to make yourself ready to face more HBase interview questions in the actual interview.
Whizlabs offers two certification-specific Hadoop training courses which are highly recognized and appraised in the industry and provide a thorough understanding of Hadoop with theory and hands on. These are –
HDP Certified Administrator (HDPCA) Certification
Cloudera Certified Associate Administrator (CCA-131) Certification
Join us today and achieve the success for tomorrow as a Hadoop professional!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
