

A Hadoop interview examines a candidate from different angles from the big data perspective. When you appear for a Hadoop interview, be prepared to face questions on all of its ecosystem components and HDFS is no exception. As HDFS is one of the key components of Hadoop, hence, HDFS interview questions take an important part of any Hadoop interview.
Preparing to become a certified Hadoop professional? Start preparation and get hands-on with our online courses for Hortonworks Certification and Cloudera Certification.
In this blog, we will discuss on some of the important and top HDFS Interview Questions and Answers. Moreover, these Hadoop Interview Questions on HDFS will highlight the core areas of HDFS to focus on.
Most Common HDFS Interview Questions and Answers
1. What is HDFS?
Answer: HDFS stands for Hadoop Distributed File System that stores large datasets in Hadoop. It runs on commodity hardware and is highly fault tolerant. HDFS follows Master/Slave architecture where a number of machines run on a cluster. The cluster comprises of a Namenode and multiple slave nodes known as DataNodes in the cluster.
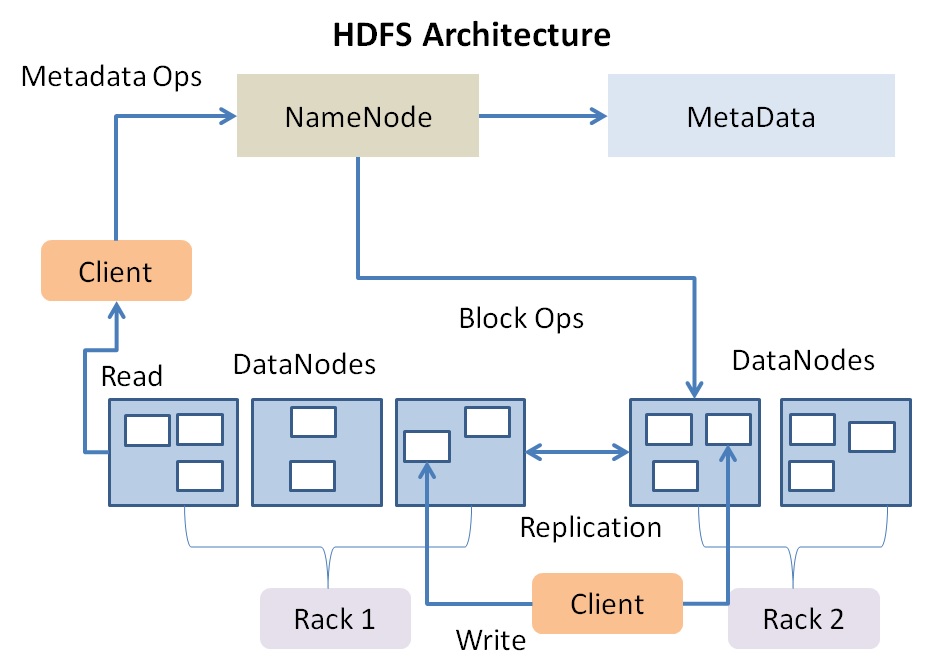
The Namenode stores meta-data, i.e., the number of Data Blocks, their replicas, locations, and other details. On the other hand, Data Node stores the actual data and performs read/write requests as per client’s request.
2. What are the different components of HDFS?
Answer: HDFS has three components:
- Namenode
- DataNode
- Secondary Namenode
3. What is the default block size of DataBlock in HDFS DataNode?
Answer: The default block size of DataBlock in Hadoop 1.x is 64MB, and in Hadoop 2.x it is 128MB.
4. Explain the service of NameNode in Hadoop.
Answer: NameNode plays the role of Master node in HDFS. It contains two vital information:
- Regarding Hadoop metadata and file system tree
- The in-memory mapping between data blocks and data node
NameNode contains the metadata information like file permission, file replication factor, block size, file creation time, owner information of the file, and the mapping between blocks of the file and the data nodes.
5. What is fsimage and editlogs in HDFS?
Answer: The metadata of Hadoop files is stored in a file in HDFS Namenode memory which is known as fsimage.
When any change is done to the Hadoop filesystem like adding or removing a file etc. it is not immediately written to fsimage rather it is maintained in a separate file on disk which is called editlog. When a name node starts, the editlog is synced with the old fsimage file, and a new copy is updated.
6. The default block size in Unix and Linux is 4KB, then why HDFS block size is set to 64MB or 128MB?
Answer: A Block is the smallest unit of data that is stored in a file system. Hence if we consider the default block size of Linux/Unix for data storing in Hadoop then for a massive set of data (petabytes) it will take a large number of blocks. Consequently, the metadata amount will increase significantly causing performance issue of NameNode. So, in Hadoop 1.x the default block size is 64MB and in Hadoop 2.x it is set to 128MB.
Are you a fresher aspired to make a career in Hadoop? Read our previous blog that will help you to start learning Hadoop for beginners.
7. What happens when the NameNode starts?
Answer: When the NameNode starts it performs the following operations:
- From last saved FsImage and the editlog file, it loads the file system namespace into its main memory.
- Creates the new fsimage file by merging the previous fsimage and editslog file to create new file system namespace.
- Receives information about block locations from all DataNodes.
8. What is Safe mode in Hadoop?
Answer: Safe mode indicates the maintenance state of the NameNode. During the safe mode, the HDFS cluster becomes read-only. Hence, no modification is allowed in the filesystem. Also, you cannot delete or replicate any data block in this mode.
9. If you change the block size in HDFS what happens to the existing data?
Answer: If we change the block size in HDFS it will not affect the existing data.
10. What is HDFS replication? What is the default replication factor?
Answer: HDFS is designed to be fault tolerant to prevent data loss. Hence, HDFS maintains three copies of each DataBlock in different racks and in different data nodes which is known as replication.
The default replication factor is 3.
11. What is the Secondary NameNode?
Answer: Hadoop metadata is stored in NameNode main memory and disk. Mainly two files are used for this purpose –
- Editlogs
- Fsimage
Any updates done to HDFS are entered in the editlogs. As the number of entries increases the file size grows automatically, however, the file size for the fsimage file remains the same. When the server gets restarted, the contents of the editlogs file are written into the fsimage file which is then loaded into main memory which is time-consuming. The more the editlogs file size, the more time it will take to load into fsimage causing an extended downtime.
To avoid such prolonged downtime, a helper node for NameNode which is known as Secondary NameNode is used which periodically copies the contents from editlogs to fsimage and copy the new fsimage file back to the NameNode.
12. How does NameNode handle DataNode failure?
Answer: HDFS architecture is designed in a way that every DataNodes periodically send heartbeat to the NameNode to assure it is in working mode. When the NameNode does not receive any heartbeat from a particular DataNode, it considers that DataNode as dead or non-functional and transfer all the respective DataBlock to some other active DataNode which is already replicated with it.
Preparing a for Hadoop Developer interview? Understand the Hadoop Developer Job Responsibilities first.
Advance HDFS Interview Questions
So, moving forward, here we cover few advance HDFS interview questions along with the frequently asked HDFS interview questions.
13. How data/file read operation is performed in HDFS?
Answer: HDFS NameNode is the placeholder for all the file information and their actual locations in the slave nodes. The below steps are followed in the read operation of a file:
- When a file needs to be read, the file information is retrieved from NameNode by DistributedFileSystem instance.
- NameNode checks whether that particular file exists and the user has the access for the file
- Once the above-mentioned criteria are met, the NameNode provides the token to the client, for authentication to get the file from DataNode.
- NameNode provides the list of all Block detail and related data nodes of the file
- DataNodes are then sorted as per their proximity to the client.
- DistributedFileSystem returns an input stream to the client called as FSDataInputStream so that client can read data from it.
- FSDataInputStream works as a wrapper to the DFSInputStream, which is responsible for managing NameNode and DataNode and I/O.
- As the Client calls read () on the stream, the DFSInputStream connects to the closet DataNode block and data is returned to the client via stream. The read () operation is repeatedly called till the end of the first block is completely read.
- Once the first block is completely read, the connection with that DataNode is closed.
- Next, the DFSInputStream again connects to the next possible DataNode for the next block, and it continues until the file is completely read.
- Once the entire file is read, FSDataInputStream calls the close () operation to close the connection.
14. Is concurrent write into HDFS file possible?
Answer: No, HDFS does not allow concurrent writing. Because when one client receives permission by NameNode for writing on data node block, the particular block gets locked till the finish of the write operation. Hence, no other client can write on the same block.
15. What are the challenges in existing HDFS architecture?
Answer: Existing HDFS architecture consists of only one NameNode which contains the single Namespace and multiple DataNodes that hold the actual data. This architecture works well with limited cluster size. However, if we try to increase the cluster size, we come across few challenges.
- As the Namespace and Blocks are tightly coupled, other services cannot easily utilize the storage capacity of Blocks efficiently.
- With a single Namenode, if we want to add more DataNodes in the cluster, it will create huge metadata. Here we can scale DataNodes horizontally. However, we cannot scale up Namenode in the same manner. This is a Namespace Scalability issue.
- The current HDFS file system has a performance limitation related to the throughput. Because a single name node supports only 60000 concurrent tasks.
- We cannot get isolated namespace for a single application as HDFS deployments happen on a multi-tenant environment and multiple applications or organizations share a single cluster.
16. What is HDFS Federation?
Answer: In the existing HDFS architecture horizontal scaling up of the Namenode is not possible. Hadoop Federation is the procedure through which several independent NameNodes are horizontally scaled up without any inter coordination.
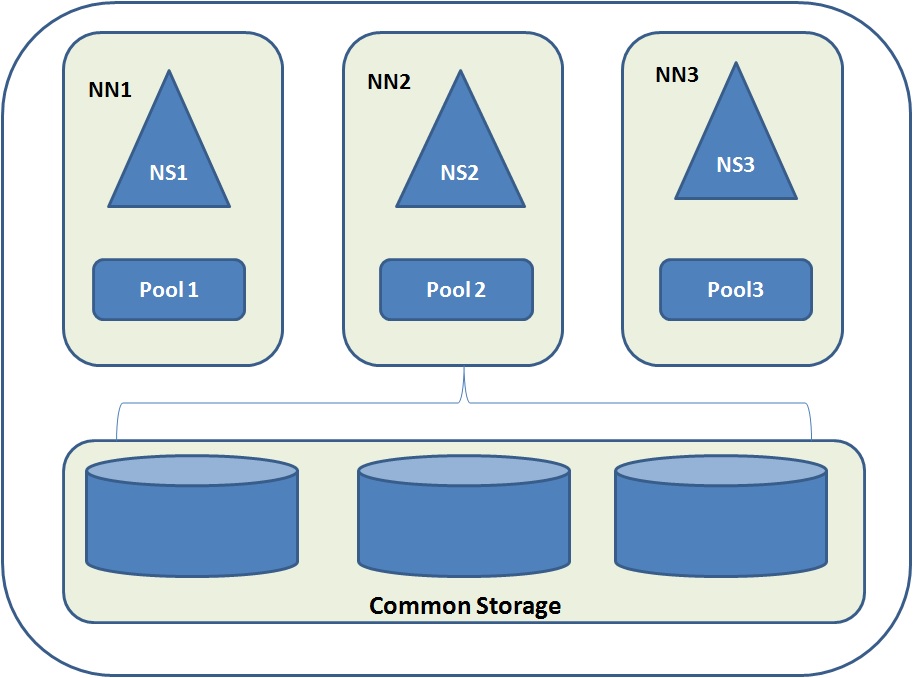
In HDFS federation architecture, DataNodes are present at the bottom layer and works as common storage. Each DataNode registers itself with all the NameNodes in the cluster. Here many NameNodes manage many Namespaces whereas each Namespace has its own Block pool. A Block pool is a set of Blocks and belongs to a single Namespace.
Bottom line, hope the above mentioned HDFS interview questions will help you to prepare for the Hadoop interview. However, HDFS is the most important component of Hadoop, and you should gain the complete understanding of its architecture and configuration to explore it better. Hence, we highly recommend you to build up your knowledge base with industry recognized Hadoop certification courses like Cloudera or HortonWorks.
Whizlabs offer two Big Data Hadoop certification courses which are highly recognized and appraised in the industry and provide a thorough understanding of Hadoop with theory and hands on. These are –
HDP Certified Administrator (HDPCA) Certification
Cloudera Certified Associate Administrator (CCA-131) Certification
Join us today and achieve the success for tomorrow as a Hadoop professional!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
