

It’s cliché to mention how quickly technology evolves. Java has been there for more than two decades in the technology domain as the most “love to hate” technologies out there. If you look closely across the broad spectrum of programming languages, operating systems, and databases, little has changed over the past few years. With the evolution of new technology space with big data and IoT, we can see much advancement.
However, Java is still the backbone for many big data tools for Java developers. Java skills and Java certification can take one’s career to the next level. The Java version history clearly defines the value and success of Java in the domain.
Java is the natural fit for the Big data as some of the core modules of big data tools for Java developers are written in Java. More interestingly most of these big data tools for Java developers are open source. Hence, they are easy to access.
Also Read: Top 10 Open Source Big Data Tools in 2018
In this blog, we will discuss the usefulness of Java for Big data tools and its future. Also, we will focus on big data tools which are mainly based on Java APIs.
What is the future of Java in Big Data?
Although Java has many reasons for not to like it, still programmers turn to it as they find many reasons to learn it. Let’s go over some of the reasons why people want to use it:
- Simplicity: As an Object-oriented language Java offers quite an easy user experience for developers as well as end-users. Java’s inbuilt design is its most significant advantage when compared with other similar object-oriented programming languages. Unlike C++ it has removed the use of pointers and interface.
- Portability: Java runtime can be run anytime and anywhere. Hence, you can run Java on any hardware and software platform.
- Allocation: Java has a stack provisioning feature that helps to re-establish quickly. Moreover, Java has the potential for garbage collection and automatic memory distribution.
- Distributive: Java is highly networking competent. Usually, Java receives and sends files informally.
- Extremely secure: Java enforces strong security standards with safe programming.
Now, let’s see where Java fits with big data in reality.
Nowadays the amount of data produced every day shows exponential growth. Moreover, analyzing such a vast amount of data will only continue to increase over the period as well. Batch data processing is a realistic way of analyzing such vast data, and this is mostly done using open source tools like Hadoop and Spark.
Interestingly most of the open-source big data tools are Java-based. One of the key reasons behind it is the root of Java is deeply ingrained in open-source communities. Hence, a huge amount of Java code is publicly available, and with these readily available code foundations like Apache, Google is hugely contributing to making open source big data tools.
For the most prominent big data tool Hadoop, Java is the language. Hence, it is easy for Java developers to learn Hadoop. The fact is learning some of the big data tools are almost similar to learning a new API for Java developers.
Not only Hadoop, but Pig is also another big data tool for Java developers which they can learn easily as Pig Latin uses JavaScript.
Best Open Source Big Data Tools for Java Developers in Market
No doubt, future of big data is Java. There are numerous big data tools for Java developers in the market, and most of them are open source from Apache. Here we have sorted out some of them which are mostly used big data tools for Java developers.
1. Apache Hadoop
Hadoop is a Java subproject and mostly used big data tools. It is an Apache Software Foundation tool which was later donated by Yahoo! It is a free, Java-based programming framework which processes large datasets in a distributed computing environment. In addition to that, you can easily install it on a cluster of standard machines. Hadoop has become very successful in companies for storing massive data in one system and performing analysis on this data. Hadoop runs in master/slave architecture. The master controls the running of the entire distributed computing stack.
Hadoop has an entire ecosystem of software built around it.
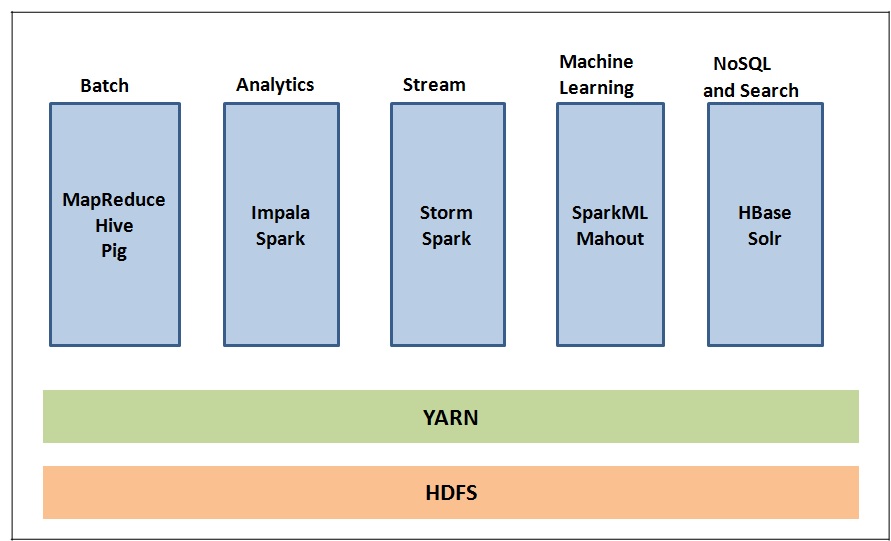
Important features of Hadoop are listed below.

If you want to know more details on Hadoop architecture and other details, please refer to our Hadoop guide for beginners.
2. Apache Spark
Apache Spark works similar to Hadoop MapReduce framework and is getting more popular than MapReduce for big data processing. Spark is a cluster computing framework and can run on thousands of machines. Furthermore, it can run on a cluster of distributed computers on the massive datasets across these computers and combine the results. Spark stands on the concept of RDD (Resilient Distributed Dataset).
Spark is used in large ETL (extract, transform, and load) operation, predictive analytics, and reporting applications. A Spark program would do the following:
- It loads some data into the RDD.
- Performs the transformation on data to make it compatible for handling your operations.
- Cache the reusable data across sessions (by using persist).
- Do some readymade or custom operations on the data.
The underlying language used for Spark is Scala, which inherently is written in Java. Hence, Java is the building block of the Apache Spark stack and is fully supported by all its products. Apache Spark stack has an extensive Java API. Thus, Apache Spark is one of the easily adopted big data tools for Java developers as they can easily pick up it.
Here are some of the Spark APIs that Java developers can easily use for big data purpose:
- The core RDD frameworks along with its functions
- Spark SQL code
- Spark Streaming code
- Spark MLlib algorithm
- Spark GraphX library
We have explained more on Spark in the blog Top 11 Factors that Make Apache Spark Faster.
Interestingly Apache Spark has become a complete ecosystem which consists of many sub-projects as described below:
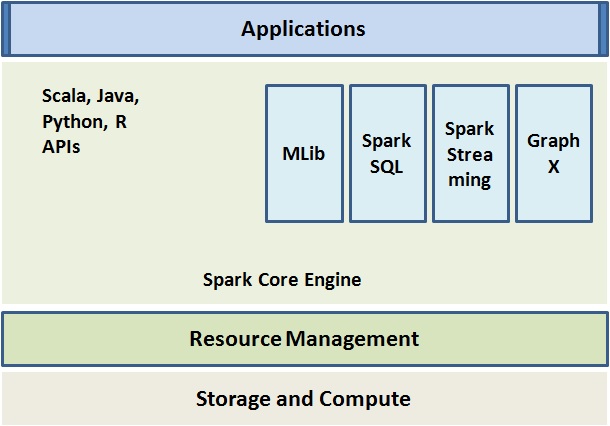
3. Apache Mahout
Apache Mahout is open source big data tool and a popular Java ML library. It consists of scalable machine learning algorithms some of which are used for:
- Recommendations
- Clustering
- Classifications
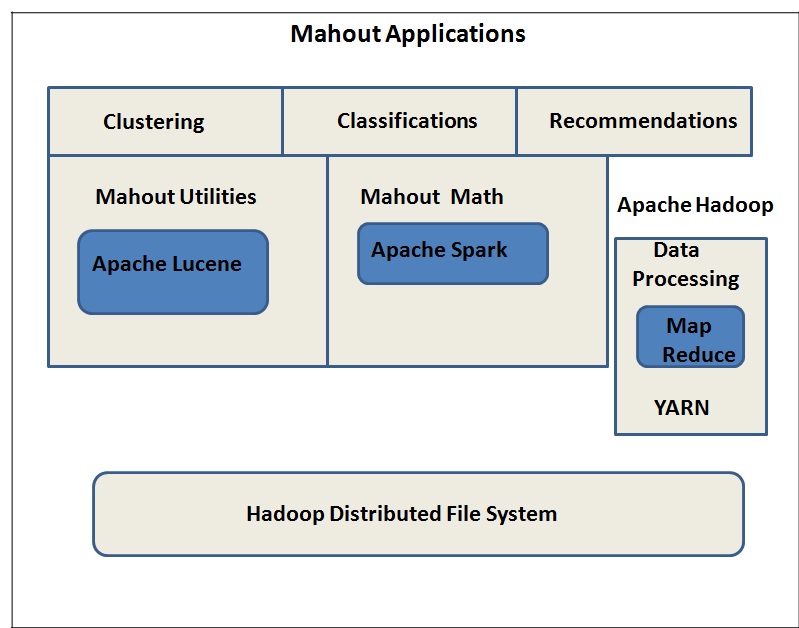
Some important features of Mahout are as follows:
- Its algorithms run on Hadoop. Hence, they work well in a distributed environment
- It has inbuilt MapReduce implementations of several ML algorithms
4. Java JFreechart
Data visualization is an important task in big data analysis. As big data deals with huge amount of data; hence, it is challenging to find out trend by just looking out raw data. However, when the same data is plotted on a chart, it becomes more comprehensible and easy to identify the patterns and relationships within data.
JFreechart is one of the popular open source big data tools for Java developers with libraries built in Java which helps in making charts.
We can build different charts to visualize data with the help of this library such as –
- Pie charts
- Bar charts
- Single and multiple time series charts
- Line charts
- Scatter Plots
- Box plots
- Histogram
JFreechart not only builds the axis and legends in the charts but also provides automatic zooming features into the charts with a mouse. However, it is useful for simple chart visualizations.
5. Deeplearning4j
Deeplearning4j is a Java library that is used to build different types of neural networks. Furthermore, we can integrate it with Apache Spark on the big data stack and can even run on GPUs. This is the only open source big data tool for Java developers which has main Java library out with a lot of built-in algorithms focusing on deep learning and casting in Java. Moreover, it has a very good online community with good documentation.
Features:
- Distributed GPUs and CPUs
- Java, Python and Python APIs
- Supports micro-service architecture
- Scalable on Hadoop
- GPU support for to scale up on AWS
6. Apache Storm
This is ideal for Java streaming applications and among popular big data tools for Java developers.
Apache Storm has many advantages, and some of its key features are –
- User-friendly
- Free and open source
- Ideal for both small and large scale implementations
- Highly fault tolerant
- Reliable
- Extremely fast
- Performs real-time processing
- Scalable
- Performs dynamic load balancing and optimization using operational intelligence
Apache Storm architecture has two main components:
- Master node (Nimbus)
- Worker nodes (Supervisor)
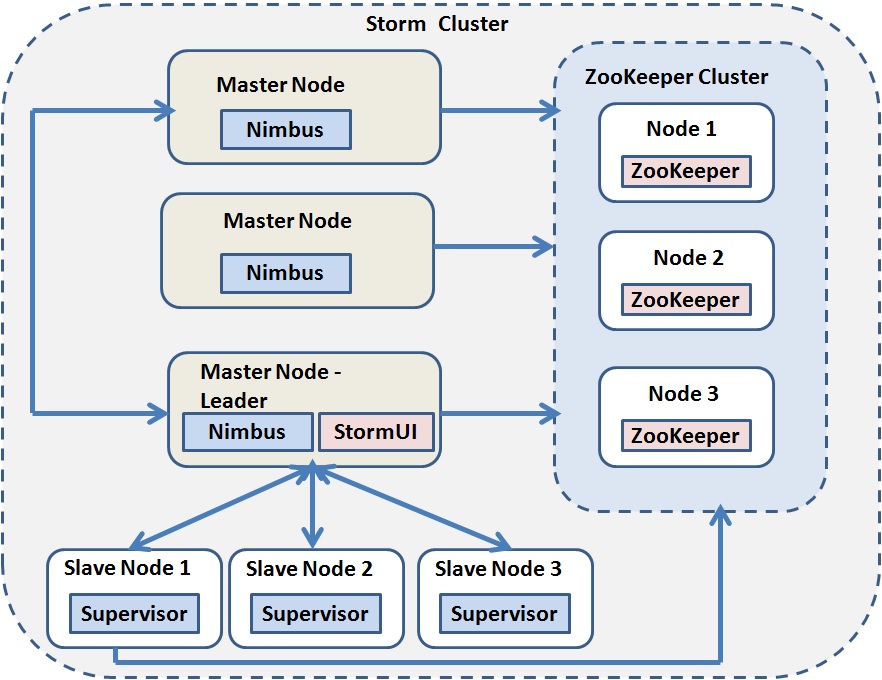
Individual worker node runs a daemon which is called “Supervisor.” The Nimbus controls the worker nodes and as per that the supervisor node listens for assigned work and starts and stops worker processes accordingly. Every worker process is associated with a subset of topology which consists of many worker processes. The entire coordination between Nimbus and Supervisors is performed using Zookeeper cluster.
Apache Spark and Apache Storm both are important tools for Java Developers. Let’s have a comparison to find which one is the best – Apache Storm vs Apache Spark
Bottom Line
As big data is evolving every day, new tools are coming into the picture. Among the big data tools for Java developers, no doubt, Hadoop is the best one. It’s the Bible of Big data. Hence, before you learn any other Big data tools, knowing Hadoop is a must.
Whizlabs offers you to learn Hadoop through its Cloudera and Hortonworks certification guides training. It’s a comprehensive guide that not only helps you to acquire a thorough knowledge of Hadoop but also hands-on expertise. Hence, join us today and promotes yourself from a Java developer to a big data specialist.
Have any questions? Just write down below in the comment section or here and we’ll be happy to answer you.
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
