

With the huge amount of data that is generated every day, it becomes important to understand the complexity of Big Data. If you are planning to enter in the Big Data planet, you should be familiar with the Big Data terms. These terms will help you dive deep into the world of big data. So, let’s start with the term Big Data itself –
An accurate definition of “Big Data” is quite hard to clinch as business professionals, projects, practitioners, and vendors take it in a different way. So, generally speaking, big data is:
- large/big data sets (large dataset refers to a dataset too large to store or process on a single computer) and,
- the classification of computing technologies and strategies which are used to confer large data sets.
Big Data is a wide spectrum and there is a lot to learn. Here are the big data terms, you should be familiar with.
101 Big Data Terms: The Big Data Glossary
Every field has its own terminology and thus, there are a number of Big Data terms to know while starting a career in Big Data. Once you will get familiar with these Big Data terms and definitions, you will be prepared to learn them in detail. In this article, we are going to define 101 Big Data terms that you should know to start a career in Big Data.
A
1. Algorithm
In computer science and mathematics, an algorithm is an effective categorical specification of how to solve a complex problem and how to perform data analysis. It consists of multiple steps to apply operations on data in order to solve a particular problem.
2. Artificial Intelligence (AI)
The popular Big Data term, Artificial Intelligence is the intelligence demonstrated by machines. AI is the development of computer systems to perform tasks normally having human intelligence such as speech recognition, visual perception, decision making and language translators etc.
3. Automatic Identification and Data Capture (AIDC)
Automatic identification and data capture (AIDC) is the big data term that refers to a method of automatically identifying and collecting data objects through computing algorithm and then storing them in the computer. For example, radio frequency identification, bar codes, biometrics, optical character recognition, magnetic strips all include algorithms for identification of data objects captured.
4. Avro
Avro is data serialization framework and a remote procedure call developed for Hadoop’s project. It uses JSON to define protocols and data types and then serializes data in binary form. Avro provides both
- Serialization format for persistent data
- Wire format for communication between Hadoop nodes and from customer programs to Hadoop services.
B
5. Behavioral Analytics
Behavioral analytics is a recent advancement in business analytics that presents new insights into client’s behavior on e-commerce platforms, web/mobile application, online games etc. It enables the marketers to make right offers to the right customers at right time.
6. Business Intelligence
Business Intelligence is a set of tools and methodologies that can analyze, manage, and deliver information which is relevant to the business. It includes reporting/query tools and dashboard same as found in analytics. BI technologies provide previous, current, and upcoming views of the business operations.
7. Big Data Scientist
Big Data Scientist is a person who can take structured and unstructured data points and use his formidable skills in statistics, maths, and programming to organize them. He applies all his analytical power (contextual understanding, industry knowledge, and understanding of existing assumptions) to uncover the hidden solutions for the business development.
8. Biometrics
Biometrics is the James Bondish technology linked with analytics to identify people by one or more physical traits. For example, biometrics technology is used in face recognition, fingerprint recognition, iris recognition etc.
C
9. Cascading
Cascading is the layer for the abstraction of software that provides the higher level abstraction for Apache Hadoop and Apache Flink. It is an open source framework that is available under Apache License. It is used to allow developers to perform processing of complex data easily and quickly in JVM based languages such as Java, Clojure, Scala, Rubi etc.
10. Call Detail Record (CDR) Analysis
CDR contains metadata i.e. data about data that a telecommunication company collects about phone calls such as length and time of the call. CDR analysis provides businesses the exact details about when, where, and how calls are made for billing and reporting purposes. CDR’s metadata gives information about
- When the calls are made (date and time)
- How long the call lasted (in minutes)
- Who called whom (Contact number of source and destination)
- Type of call ( Inbound, Outbound or Toll-free)
- How much the call costs (on the basis of per minute rate)
11. Cassandra
Cassandra is distributed and open source NoSQL database management system. It is schemed to manage a large amount of distributed data over commodity servers as it provides high availability of services with no point of failure. It was developed by Facebook initially and then structured in key-value form under Apache foundation.
12. Cell Phone Data
Cell phone data has surfaced as one of the big data sources as it generates a tremendous amount of data and much of it is available for use with analytical applications.
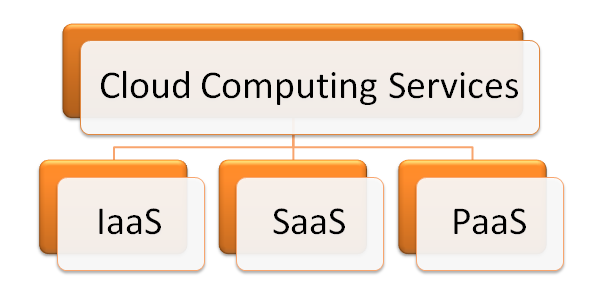
13. Cloud Computing
Cloud computing is one of the must-known big data terms. It is a new paradigm computing system which offers visualization of computing resources to run over the standard remote server for storing data and provides IaaS, PaaS, and SaaS. Cloud Computing provides IT resources such as Infrastructure, software, platform, database, storage and so on as services. Flexible scaling, rapid elasticity, resource pooling, on-demand self-service are some of its services.
14. Cluster Analysis
Cluster analysis is the big data term related to the process of the grouping of objects similar to each other in the common group (cluster). It is done to understand the similarities and differences between them. It is the important task of exploratory data mining, and common strategies to analyze statistical data in various fields such as image analysis, pattern recognition, machine learning, computer graphics, data compression and so on.
15. Chukwa
Apache Chukwa is an open source large-scale log collection system for monitoring large distributed systems. It is one of the common big data terms related to Hadoop. It is built on the top of Hadoop Distributed File System (HDFS) and Map/Reduce framework. It inherits Hadoop’s robustness and scalability. Chukwa contains a powerful and flexible toolkit database for monitoring, displaying, and analyzing results so that collected data can be used in the best possible ways.
16. Columnar Database / Column-Oriented Database
A database that stores data column by column instead of the row is known as the column-oriented database.
17. Comparative Analytic-oriented Database
Comparative analytic is a special type of data mining technology which compares large data sets, multiple processes or other objects using statistical strategies such as filtering, decision tree analytics, pattern analysis etc.
18. Complex Event Processing (CEP)
Complex event processing (CEP) is the process of analyzing and identifying data and then combining it to infer events that are able to suggest solutions to the complex circumstances. The main task of CEP is to identify/track meaningful events and react to them as soon as possible.
D
19. Data Analyst
The data analyst is responsible for collecting, processing, and performing statistical analysis of data. A data analyst discovers the ways how this data can be used to help the organization in making better business decisions. It is one of the big data terms that define a big data career. Data analyst works with end business users to define the types of the analytical report required in business.
20. Data Aggregation
Data aggregation refers to the collection of data from multiple sources to bring all the data together into a common athenaeum for the purpose of reporting and/or analysis.
The knowledge of one of the high-level programming languages is required to build a career in Big Data. Let’s check out which are the Top 3 Big Data Programming Languages for You!
21. Dashboard
It is a graphical representation of analysis performed by the algorithms. This graphical report shows different color alerts to show the activity status. A green light is for the normal operations, a yellow light shows that there is some impact due to operation and a red light signifies that the operation has been stopped. This alertness with different lights helps to track the status of operations and find out the details whenever required.
22. Data Scientist
Data Scientist is also a big data term that defines a big data career. A data scientist is a practitioner of data science. He is proficient in mathematics, statistics, computer science, and/or data visualization who establish data models and algorithms for complex problems to solve them.
23. Data Architecture and Design
In IT industry, Data architecture consists of models, policies standards or rules that control which data is aggregated, and how it is arranged, stored, integrated and brought to use in data systems. It has three phases
- Conceptual representation of business entities
- The logical representation of the relationships between business entities
- The physical construction of the system for functional support
24. Database administrator (DBA)
DBA is the big data term related to a role which includes capacity planning, configuration, database design, performance monitoring, migration, troubleshooting, security, backups and data recovery. DBA is responsible for maintaining and supporting the rectitude of content and structure of a database.
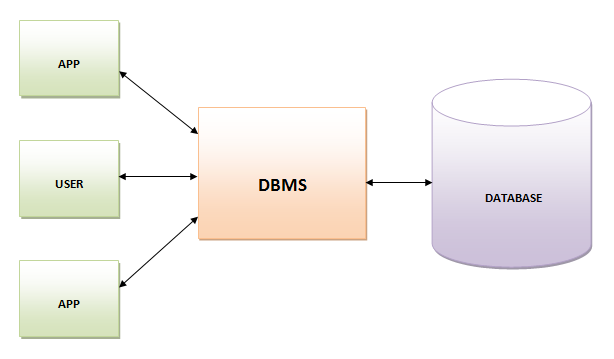
25. Database Management System (DBMS)
Database Management System is software that collects data and provides access to it in an organized layout. It creates and manages the database. DBMS provides programmers and users a well-organized process to create, update, retrieve, and manage data.
26. Data Model and Data Modelling
Data Model is a starting phase of a database designing and usually consists of attributes, entity types, integrity rules, relationships and definitions of objects.
Data modeling is the process of creating a data model for an information system by using certain formal techniques. Data modeling is used to define and analyze the requirement of data for supporting business processes.
Looking for big data tools to start a big data career? Here are the Top 10 Open Source Big Data Tools in 2018.
27. Data Cleansing
Data Cleansing/Scrubbing/Cleaning is a process of revising data to remove incorrect spellings, duplicate entries, adding missing data, and providing consistency. It is required as incorrect data can lead to bad analysis and wrong conclusions.
28. Document Management
Document management, often, referred to as Document management system is a software which is used to track, store, and manage electronic documents and an electronic image of paper through a scanner. It is one of the basic big data terms you should know to start a big data career.
29. Data Visualization
Data visualization is the presentation of data in a graphical or pictorial format designed for the purpose of communicating information or deriving meaning. It validates the users/decision makers to see analytics visually so that they would be able to understand the new concepts. This data helps –
- to derive insight and meaning from the data
- in the communication of data and information in a more effective manner
30. Data Warehouse
The data warehouse is a system of storing data for the purpose of analysis and reporting. It is believed to be the main component of business intelligence. Data stored in the warehouse is uploaded from the operational system like sales or marketing.
31. Drill
The drill is an open source, distributed, low latency SQL query engine for Hadoop. It is built for semi-structured or nested data and can handle fixed schemas. The drill is similar in some aspects to Google’s Dremel and is handled by Apache.
E
32. Extract, Transform, and Load (ETL)
ETL is the short form of three database functions extract, transform and load. These three functions are combined together into one tool to place them from one to another database.
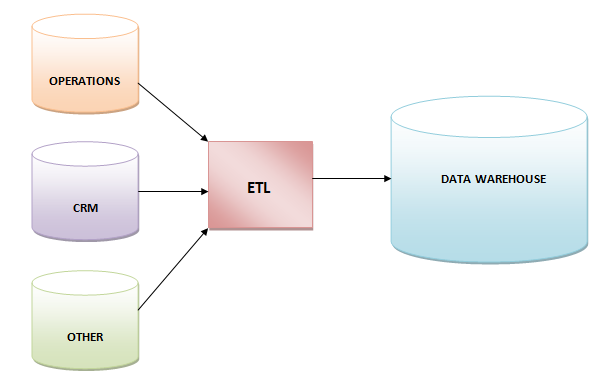
- Extract
It is the process of reading data from a database.
- Transform
It is the process of conversion of extracted data in the desired form so that it can be put into another database.
- Load
It is the process of writing data into the target database
F
33. Fuzzy Logic
Fuzzy logic is an approach to computing based on degrees of truth instead of usual true/false (1 or 0) Boolean algebra.
34. Flume
Flume is defined as a reliable, distributed, and available service for aggregating, collecting, and transferring huge amount of data in HDFS. It is robust in nature. Flume architecture is flexible in nature, based on data streaming.
G
35. Graph Database
A graph database is a group/collection of edges and nodes. A node typifies an entity i.e. business or individual whereas an edge typifies a relation or connection between nodes.
You must remember the statement given by graph database experts –
“If you can whiteboard it, you can graph it.”
36. Grid Computing
Grid computing is a collection of computer resources for performing computing functions using resources from various domains or multiple distributed systems to reach a specific goal. A grid is designed to solve big problems to maintain the process flexibility. Grid computing is often used in scientific/marketing research, structural analysis, web services such as back-office infrastructures or ATM banking etc.
37. Gamification
Gamification refers to the principles used in designing the game to improve customer engagement in non-game businesses. Different companies use different gaming principles to enhance interest in a service or product or simply we can say gamification is used to deepen their client’s relationship with the brand.
H
38. Hadoop User Experience (HUE)
Hadoop User Experience (HUE) is an open source interface which makes Apache Hadoop’s use easier. It is a web-based application. It has a job designer for MapReduce, a file browser for HDFS, an Oozie application for making workflows and coordinators, an Impala, a shell, a Hive UI, and a group of Hadoop APIs.
39. High-Performance Analytical Application (HANA)
High-performance Analytical Application is a software/hardware scheme for large volume transactions and real-time data analytics in-memory computing platform from the SAP.
40. HAMA
Hama is basically a distributed computing framework for big data analytics based on Bulk Synchronous Parallel strategies for advanced and complex computations like graphs, network algorithms, and matrices. It is a Top-level Project of The Apache Software Foundation.
Big Data Analytics is the field with a number of career opportunities. Let’s check out why is Big Data Analytics so important!
41. Hadoop Distributed File System (HDFS)
Hadoop Distributed File System (HDFS) is primary data storage layer used by Hadoop applications. It employs DataNode and NameNode architecture to implement distributed and Java-based file system which supplies high-performance access to data with high scalable Hadoop Clusters. It is designed to be highly fault-tolerant.
42. HBase
Apache HBase is the Hadoop database which is an open source, scalable, versioned, distributed and big data store. Some features of HBase are
- Modular and linear scalability
- Easy to use Java APIs
- Configurable and automatic sharing of tables
- Extensible JIRB shell
43. Hive
Hive is an open source Hadoop-based data warehouse software project for providing data summarization, analysis, and query. Users can write queries in the SQL-like language known as HiveQL. Hadoop is a framework which handles large datasets in the distributed computing environment.
I
44. Impala
Impala is an open source MPP (massively parallel processing) SQL query engine which is used in computer cluster for running Apache Hadoop. Impala provides parallel database strategy to Hadoop so that user will be able to apply low-latency SQL queries on the data that is stored in Apache HBase and HDFS without any data transformation.
K
45. Key Value Stores / Key Value Databases
Key value store or key-value database is a paradigm of data storage which is schemed for storing, managing, and retrieving a data structure. Records are stored in a data type of a programming language with a key attribute which identifies the record uniquely. That’s why there is no requirement of a fixed data model.
L
46. Load balancing
Load balancing is a tool which distributes the amount of workload between two or more computers over a computer network so that work gets completed in small time as all users desire to be served faster. It is the main reason for computer server clustering and it can be applied with software or hardware or with the combination of both.
47. Linked Data
Linked data refers to the collection of interconnected datasets that can be shared or published on the web and collaborated with machines and users. It is highly structured, unlike big data. It is used in building Semantic Web in which a large amount of data is available in the standard format on the web.
48. Location Analytics
Location analytics is the process of gaining insights from geographic component or location of business data. It is the visual effect of analyzing and interpreting the information which is portrayed by data and allows the user to connect location-related information with the dataset.
49. Log File
A log file is the special type of file that allows users keeping the record of events occurred or the operating system or conversation between the users or any running software.
M
50. Metadata
Metadata is data about data. It is administrative, descriptive, and structural data that identifies the assets.
51. MongoDB
MongoDB is an open source and NoSQL document-oriented database program. It uses JSON documents to save data structures with an agile scheme known a MongoDB BSON format. It integrates data in applications very quickly and easily.
52. Multi-Dimensional Database (MDB)
A multidimensional database (MDB) is a kind of database which is optimized for OLAP (Online Analytical Processing) applications and data warehousing. MDB can be easily created by using the input of relational database. MDB is the ability of processing data in the database so that results can be developed quickly.
53. Multi-Value Database
Multi-Value Database is a kind of multi-dimensional and NoSQL database which is able to understand three-dimensional data. These databases are enough for manipulating XML and HTML strings directly.
Some examples of Commercial Multi-value Databases are OpenQM, Rocket D3 Database Management System, jBASE, Intersystem Cache, OpenInsight, and InfinityDB.
54. Machine-Generated Data
Machine generated data is the information generated by machines (computer, application, process or another inhuman mechanism). Machine generated data is known as amorphous data as humans can rarely modify/change this data.
55. Machine Learning
Machine learning is a computer science field that makes use of statistical strategies to provide the facility to “learn” with data on the computer. Machine learning is used for exploiting the opportunities hidden in big data.
56. MapReduce
MapReduce is a processing technique to process large datasets with the parallel distributed algorithm on the cluster. MapReduce jobs are of two types. “Map” function is used to divide the query into multiple parts and then process the data at the node level. “Reduce’ function collects the result of “Map” function and then find the answer to the query. MapReduce is used to handle big data when coupled with HDFS. This coupling of HDFS and MapReduce is referred to as Hadoop.
57. Mahout
Apache Mahout is an open source data mining library. It uses data mining algorithms for regression testing, performing, clustering, statistical modeling, and then implementing them using MapReduce model.
N
58. Network Analysis
Network analysis is the application of graph/chart theory that is used to categorize, understand, and viewing relationships between the nodes in network terms. It is an effective way of analyzing connections and to check their capabilities in any field such as prediction, marketing analysis, and healthcare etc.
59. NewSQL
NewSQL is a class of modern relational database management system which provide the scalable performance same as NoSQL systems for OLTP read/write workloads. It is well-defined database system which is easy to learn.
Want to extend your knowledge of Big Data? Here is the complete list of Big Data Blogs, just read and become a Big Data expert!
60. NoSQL
Widely known as ‘Not only SQL’, it is a system for the management of databases. This database management system is independent of the relational database management system. A NoSQL database is not built on tables, and it doesn’t use SQL for the manipulation of data.
O
61. Object Databases
The database that stores data in the form of objects is known as the object database. These objects are used in the same manner as that of the objects used in OOP. An object database is different from the graph and relational databases. These databases provide a query language most of the time that helps to find the object with a declaration.
62. Object-based Image Analysis
It is the analysis of object-based images that is performed with data taken by selected related pixels, known as image objects or simply objects. It is different from the digital analysis that is done using data from individual pixels.
63. Online Analytical Processing (OLAP)
It is the process by which analysis of multidimensional data is done by using three operators – drill-down, consolidation, and slice and dice.
- Drill-down is the capability provided to users to view underlying details
- Consolidation is the aggregate of available
- Slice and dice is the capability provided to users for selecting subsets and viewing them from various contexts
64. Online transactional processing (OLTP)
It is the big data term used for the process that provides users an access to the large set of transactional data. It is done in such a manner that users are able to derive meaning from the accessed data.
65. Open Data Center Alliance (ODCA)
OCDA is the combination of IT organizations over the globe. The main goal of this consortium is to increase the movement of cloud computing.
66. Operational Data Store (ODS)
It is defined as a location to collect and store data retrieved from various sources. It allows users to perform many additional operations on the data before it is sent for reporting to the data warehouse.
67. Oozie
It is the big data term used for a processing system that allows users to define a set of jobs. These jobs are written in different languages such as Pig, MapReduce, and Hive. Oozie allows users to link those jobs to one another.
P
68. Parallel Data Analysis
The process of breaking an analytical problem into small partitions and then running analysis algorithms on each of the partitions simultaneously is known as parallel data analysis. This type of data analysis can be run either on the different systems or on the same system.
69. Parallel Method Invocation (PMI)
It is the system that allows program code to call or invoke multiple methods/functions simultaneously at the same time.
70. Parallel Processing
It is the capability of a system to perform the execution of multiple tasks simultaneously.
71. Parallel Query
A parallel query can be defined as a query that can be executed over multiple system threads in order to improve the performance.
72. Pattern Recognition
A process to classify or label the identified pattern in the process of machine learning is known as pattern recognition.
73. Pentaho
Pentaho, a software organization, provides open source Business Intelligence products those are known as Pentaho Business Analytics. Pentaho offers OLAP services, data integration, dashboarding, reporting, ETL, and data mining capabilities.
74. Petabyte
The data measurement unit equals to 1,024 terabytes or 1 million gigabytes is known as petabyte.
Q
75. Query
A query is a method to get some sort of information in order to derive an answer to the question.
Big Data world is steadily evolving with the time. Let’s have a look at the upcoming Big Data Trends in 2018.
76. Query Analysis
The process to perform the analysis of search query is called query analysis. The query analysis is done to optimize the query to get the best possible results.
R
77. R
It is a programming language and an environment for the graphics and statistical computing. It is very extensible language that provides a number of graphical and statistical techniques such as nonlinear and linear modeling, time-series analysis, classical statistical tests, clustering, classification etc.
78. Re-identification
The data re-identification is a process that matches anonymous data with the available auxiliary data or information. This practice is helpful to find out the individual whom this data belongs to.
79. Real-time Data
The data that can be created, stored, processed, analyzed, and visualized instantly i.e. in milliseconds, is known as real-time data.
80. Reference Data
It is the big data term that defines the data used to describe an object along with its properties. The object described by reference data may be virtual or physical in nature.
81. Recommendation Engine
It is an algorithm that performs the analysis of various actions and purchases made by a customer on an e-commerce website. This analyzed data is then used to recommend some complementary products to the customer.
82. Risk Analysis
It is a process or procedure to track the risks of an action, project or decision. The risk analysis is done by applying different statistical techniques on the datasets.
83. Routing Analysis
It is a process or procedure to find the optimized routing. It is done with the use of various variables for transport to improve efficiency and reduce costs of the fuel.
S
84. SaaS
It is the big data term used for Software-as-a-Service. It allows vendors to host an application and then make this application available over the internet. The SaaS services are provided in the cloud by SaaS providers.
85. Semi-Structured Data
The data, not represented in the traditional manner with the application of regular methods is known as semi-structured data. This data is neither totally structured nor unstructured but contains some tags, data tables, and structural elements. Few examples of semi-structured data are XML documents, emails, tables, and graphs.
86. Server
The server is a virtual or physical computer that receives requests related to the software application and thus sends these requests over a network. It is the common big data term used almost in all the big data technologies.
87. Spatial Analysis
The analysis of spatial data i.e. topological and geographic data is known as spatial analysis. This analysis helps to identify and understand everything about a particular area or position.
88. Structured Query Language (SQL)
SQL is a standard programming language that is used to retrieve and manage data in a relational database. This language is very useful to create and query relational databases.
89. Sqoop
It is a connectivity tool that is used to move data from non-Hadoop data stores to Hadoop data stores. This tool instructs Sqoop to retrieve data from Teradata, Oracle or any other relational database and to specify target destination in Hadoop to move that retrieved data.
90. Storm
Apache Storm is a distributed, open source, and real-time computation system used for data processing. It is one of the must-known big data terms, responsible to process unstructured data reliably in real-time.
A big data certification validates your Big Data skills and helps you stand out of the crowd. Here is the list of best Big Data Certifications in 2018.
T
91. Text Analytics
The text analytics is basically the process of the application of linguistic, machine learning, and statistical techniques on the text-based sources. The text analytics is used to derive an insight or meaning from the text data by application of these techniques.
92. Thrift
It is a software framework that is used for the development of the ascendable cross-language services. It integrates code generation engine with the software stack to develop services that can work seamlessly and efficiently between different programming languages such as Ruby, Java, PHP, C++, Python, C# and others.
U
93. Unstructured Data
The data for which structure can’t be defined is known as unstructured data. It becomes difficult to process and manage unstructured data. The common examples of unstructured data are the text entered in email messages and data sources with texts, images, and videos.
V
94. Value
This big data term basically defines the value of the available data. The collected and stored data may be valuable for the societies, customers, and organizations. It is one of the important big data terms as big data is meant for big businesses and the businesses will get some value i.e. benefits from the big data.
95. Volume
This big data term is related to the total available amount of the data. The data may range from megabytes to brontobytes.
W
96. WebHDFS Apache Hadoop
WebHDFS is a protocol to access HDFS to make the use of industry RESTful mechanism. It contains native libraries and thus allows to have an access of the HDFS. It helps users to connect to the HDFS from outside by taking advantage of Hadoop cluster parallelism. It also offers the access of web services strategically to all Hadoop components.
97. Weather Data
The data trends and patterns that help to track the atmosphere is known as the weather data. This data basically consists of numbers and factors. Now, real-time data is available that can be used by the organizations in a different manner. Such as a logistics company uses weather data in order to optimize goods transportation.
X
98. XML Databases
The databases that support the storage of data in XML format is known as XML database. These databases are generally connected with the document-specific databases. One can export, serial, and put a query on the data of XML database.
Y
99. Yottabyte
It is the big data term related to the measurement of data. One yottabyte is equal to 1000 zettabytes or the data stored in 250 trillion DVDs.
Z
100. ZooKeeper
It is an Apache software project and Hadoop subproject which provides open code name generation for the distributed systems. It also supports consolidated organization of the large-sized distributed systems.
101. Zettabyte
It is the big data term related to the measurement of data. One zettabyte is equal to 1 billion terabytes or 1000 exabytes.
Bottom Line
Big data is not only a buzz word but the broad term that has a lot to learn. So, we have enlisted and described these Big Data terms that will be helpful in your big data career. Not to mention, it is important to validate your big data skills and knowledge for the bright career. And big data certifications are meant to demonstrate your big data skills to the employers.
Whizlabs, the pioneer in Big Data Certifications Training, is aimed to help you learn and get certified in big data technologies. Whether you are a Hadoop or Spark professional, Whizlabs Hadoop Admin (HDPCA), Spark Developer (HDPCD), and CCA Administrator certification online training will prepare you for a bright future!
Have any questions regarding these Big Data terms? Just write here or put a comment below, we’ll be happy to answer!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021
