

What are the most popular and useful big data programming languages? Maybe, it is the most pertaining question for any aspiring big data programmer to begin with big data languages. Not to mention, there are many big data programming languages for data science on the list. Before we give our opinion on the best programming language for Big Data, it is good to know about the market survey a little bit.
Recommended Reading: A Complete List of Big Data Blogs
Top 3 Big Data Programming Languages
As per the data science community KD Nugget’s yearly poll on “What programming/statistics, languages are used for data science work” the below graph represents the popularity of languages:
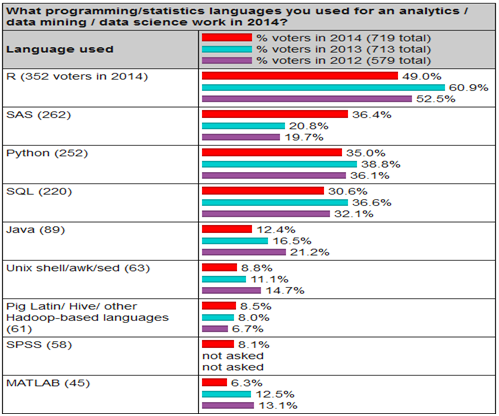
However, based on the market survey and user experience we have shortlisted the top 3 big data programming languages from the list as the most used programming languages for data science. Let’s go through this blog and know the power of these big data programming languages.
The field of big data is growing continuously. Let’s get understand the Importance of Big Data Analytics.
Java – The Ultimate Big Data Programming Language
According to the industry report, since its inception in the mid 90’s Java has ranked itself as the number one or two most popular open-source programming language. There are many factors that play vital roles to make Java popular.
Java Features
The important features of Java that make it suitable for data scientists are:
- Java is platform-agnostic with Java Virtual Machine (JVM). Hence, Java can run on almost every system. Being portable, investing in Java is long-term beneficial for developers.
- Scalability is the backbone of Java which makes it popular for enterprises as well as small applications.
- Java is a statically-typed language. Hence, it is faster and easier to maintain with fewer bugs.
- Java is backward compatible, which means you can use old versions of Java perfectly even after it releases new versions. This helps organizations or individuals to get rid of rework.
- Java has vast communities support like Stack Overflow and GitHub. It is another reason for its popularity.
- Java is an Original JVM language (with many other JVM languages) and very much simpler to use. It moreover uses OOP object-oriented programming, it always maintains some standards and consistency thoroughly in this industry which makes a solid choice of JVM.
Now if we consider from the big data perspective, JVM is the backbone for big data analysis tools like Hadoop MapReduce. Not only Hadoop, but many other big data analysis tools like Storm, Spark, and Kafka are also written in Java and run on the JVM (in Clojure and Scala). Another big data-related technology Apache Beam which was previously known as Google Cloud Dataflow supports Java only.
Hence, Java is essential for any Hadoop developer who wants to take a dig deep into Hadoop code. To understand the code functionality and troubleshooting, knowledge of core and advance Java is essential. So, Java is a must for big data development.
From a data science perspective for iterative development, Java 8 has the new lambda support which helps in reducing the verbosity. Also with Java 9 release, users will get REPL support. These two big enhancements in the new releases make Java almost similar compatible with other popular data science languages R, Python, or Scala.
Preparing for Big Data interview? Go through these top 25 Big Data Interview Questions and Answers to crack the interview!
Python – The Importance is on the Rise
Python has gained its popularity as a major language in some of the most trending technologies of the decade like Data Science, Machine learning, Artificial Intelligence(AI), Robotics, Big data, and Cyber Security.
Python is a simple, open-source, general-purpose language. Hence, it is easy to learn Python for anyone. This is the most important reason behind its success among the big data programming languages. With its rich set of utilities and libraries and easy-to-use features, it works wonders for big data processing and analysis.
Unlike R, Python is a traditional object-oriented language; hence most developers feel relatively easy working with it. On the other hand, the first exposure to R or Scala can prove to be a steep learning curve for beginners.
Python features
The following features make python a perfect fit for rapid data science application development.
- Python is an interpreted language. Hence, the coded program does not need any compilation.
- Python dynamically defines variable types.
- Python is unique in its way with less coding which makes it more acceptable for the users.
- Python is strongly typed which needs manual typecasting.
- Python is portable, extendable, and scalable.
Python has gained a lot of importance in big data. With its comprehensive set of data processing libraries, Python is an easy to use language for data scientists. It allows big data experts to make scalable applications. Also, it can be easily integrated with the web applications. The user can install many open source packages in python environment which may be useful at later point of time.
The factors mentioned above support big data processing in generating quick insights of data. This is a need for today’s organizations which Python fulfills perfectly.
Thinking about Big Data Jobs? Let’s check out Job Trends for Big Data Professionals.
Scala: Go on a Hybrid Language Way for Big Data
This is a highly scalable and general purpose programming language which combines features of both object-oriented and functional programming.
Scala Features
Some of the well-known features of Scala are:
- Scala is a general-purpose language with a concise and expressive design. Hence, it is less verbose.
- Scala supports both OOP and functional programming in individual ways.
- Scala is interoperable with Java libraries.
- It is portable. Also, as Scala is one of the JVM languages, one can write Scala’s source code and then can run it on JVM as compiled Java bytecode.
- Scala can compile to JavaScript. Hence, you can use Scala to write web apps.
- Scala checks types at compile time. Hence, developers can catch the bugs at compile time and can escape many production issues.
Scala is a rival of Java and Python in the world of Data Science and becoming more and more popular due to extensive use of Apache Spark in Big data Hadoop industry. To know more about Apache Spark importance, read our blog on Importance of Apache Spark in Big data Industry.
Apache Spark is written in Scala. Not only is data processing, but Scala is also reputed as the language for machine learning and streaming analytics. Apache Spark is inbuilt with many APIs and libraries which support machine learning algorithms.
Bottom Line
To conclude, if you are an aspiring big data professional then Linux and Java are the base for the most popular big data tool like Hadoop. Knowing all the above three languages is an advantage if you want to prosper in Data science and big data arena. However, scaling up gradually make sense for better achievement.
A combined skill like Java with Hadoop is the most demanding in big data industry. Whizlabs offers you the certification guides for both Java and Hadoop (Cloudera and Hortonworks) which helps you to take an edge over others while you prepare yourself as industry ready Hadoop professional.
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021

Informative and clear content and one to keep for further reference.
Best view i have ever seen !
i know you write in it but what else?. what are some good websites to start a blog and what topics should i do?.