

Cloud is mainly used to drive down the cost of compute and storage, but a new generation of applications brings a new set of requirements for the databases. To support these requirements and fulfill the needs of your applications, both the non-relational and relational databases are required.
Amazon Web Services (AWS) offers a broad set of databases built for your specific applications. Amazon RDS and Amazon RedShift are the relational databases whereas Amazon DynamoDB and Amazon ElastiCache are the non-relational databases in AWS. In this blog, we’ll cover the most common AWS database interview questions and answers that are frequently asked in an AWS interview. However, if you’re looking for more questions for different AWS job role, check out our previous article that covers the top 50 AWS interview questions.
To make it easy for you to prepare with these questions, we’ve categorized them in different sections such as AWS database interview questions for freshers, AWS database interview questions for experienced, AWS DynamoDB interview questions, AWS RDS interview questions, AWS RedShift interview questions, and AWS ElastiCache interview questions.
Whether you are an AWS Architect, Developer or System Admin, you may come across AWS database interview questions in the interview. Let’s get ahead to prepare with the latest AWS database interview questions and answers.
Top 30 AWS Database Interview Questions
In an AWS interview, you may come across basic as well as advanced AWS database interview questions. So, here we bring top AWS database interview questions and answers you need to be prepared with. These are the most common questions that are asked in an AWS database interview. So, whatever be the company you are going for the interview, these best AWS database interview questions will help you develop your knowledge and get selected in the interview.
AWS Database Interview Questions for Freshers
It doesn’t matter you are a fresher or have some considerable experience, you may come across some basic and most common AWS database interview questions in the interview. So, let’s go through these best AWS database interview questions and prepare yourself for the Amazon database interview.
1. What do you know about the Amazon Database?
Answer: Amazon database is one of the Amazon Web Services that offers managed database along with managed service and NoSQL. It is also a fully managed petabyte-scale data warehouse service and in-memory caching as a service. There are four AWS database services, the user can choose to use one or multiple that meet the requirements. Amazon database services are – DynamoDB, RDS, RedShift, and ElastiCache.
2. Explain Amazon Relational Database.
Answer: Amazon relational database is a service that helps users with a number of services such as operation, lining up, and scaling an on-line database within the cloud. It automates the admin tasks such as info setup, hardware provisioning, backups, and mending. Amazon relational database provides users with resizable and cost-effective capability. By automating the tasks, it saves time and thus let user concentrate on the applications and provide them high availableness, quick performance, compatibility, and security. There are a number of AWS RDS engines, such as:
- MySQL
- Oracle
- PostgreSQL
- SQL Server
- MariaDB
- Amazon Aurora
Read Now: Amazon Braket
3. What are the features of Amazon Database?
Answer: Following are the important features of Amazon Database:
- Easy to administer
- Highly scalable
- Durable and reliable
- Faster performance
- Highly available
- More secure
- Cost-effective
4. Which of the AWS DB service is a NoSQL database and server-less, and delivers consistent single-digit millisecond latency at any scale?
Answer: Amazon DynamoDB
Must Read: 10 AWS Jobs You can Get with an AWS Certification
5. What is a key-value store?
Answer: Key-value store is a database service that facilitates the storing, updating, and querying of the objects which are generally identified with the key and values. These objects consist of the keys and values which constitute the actual content that is stored.
AWS Database Interview Questions: DynamoDB
NoSQL is widely used now as compared to the traditional SQL database service. And thus, the demand for professionals with DynamoDB knowledge has increased in the industry. There are a number of opportunities for the professionals aspired to make a career in the database and backend fields. If you have some prior knowledge of DynamoDB and you are looking for AWS database interview questions, here are the AWS DynamoDB interview questions that will help you crack the interview.
6. What is DynamoDB?
Answer: DynamoDB is a NoSQL database service that provides an inevitable and faster performance. DynamoDB is superintendent and offers a high level of scalability. DynamoDB makes users not to worry about the configuration, setup, hardware provisioning, throughput capacity, replication, software patching or cluster scaling. It helps users in offloading the scaling and operating distributed databases to AWS.
7. List some of the benefits of using Amazon DynamoDB.
Answer: Amazon DynamoDB is the NoSQL service that provides a number of benefits to the users. Some of the benefits of AWS DynamoDB are –
- Being a self-managed service, DynamoDB doesn’t require the experts for setup, installation, cluster etc.
- It provides inevitable and faster performance.
- It is highly scalable, available, and durable.
- It provides very high throughput at the low latency.
- It is highly cost-effective.
- It supports and allows the creation of dynamic tables with multi-values attributes i.e. it’s flexible in nature.
Also Read: How to use Amazon DynamoDB?
8. What is a DynamoDB Mapper Class?
Answer: The mapper class is the entry point of the DynamoDB. It allows users to enter the DynamoDB and access the endpoint. DynamoDB mapper class helps users access the data stored in various tables, then execute queries, scan them against the tables, and perform CRUD operations on the data items.
9. What are the data types supported by DynamoDB?
Answer: DynamoDB supports different types of data types such as collection data types, scalar data types, and even null values.
Scalar Data Types – The scalar data types supported by DynamoDB are:
- Binary
- Number
- Boolean
- String
Collection Data Types – The collection data types supported by DynamoDB are:
- Binary Set
- Number Set
- String Set
- Heterogeneous Map
- Heterogeneous List
Want to become an AWS Certified Architect? Start your preparation now for the AWS Certified Solutions Architect Associate exam.
10. What do you understand by DynamoDB Auto Scaling?
Answer: DynamoDB Auto Scaling specifies its specialized feature to automatically scale up and down its own read and write capacity or global secondary index.
Note: CIDR is one of the important terms an AWS Engineer should know about. CIDR offers the benefits of effective management of available IP address space and reduces the number of routing table entries. If you are still wondering what does CIDR stand for, learn more!
AWS Database Interview Questions: Redshift
With the increase in popularity in Amazon Redshift, it has become a hot topic for the interviewers due to its advantages. As the digital data is accumulating at an incomprehensible speed the enterprises are experiencing difficulties in managing the data so they are moving the data to the cloud. Here we are presenting you with some of the best AWS RedShift interview questions which are asked frequently by the interviewers.
11. What is a Data Warehouse and how AWS Redshift can play a vital role in the storage?
Answer: A data warehouse can be thought of a repository where the data generated from the company’s systems and other sources is collected and stored. So a data warehouse has three-tier architecture:
- In the bottom tier, we have the tools which cleanse and collect the data.
- in the middle tier, we have tools which transform the data using Online Analytical Processing Server.
- In the top tier, we have different tools where data analysis and data mining is performed at the front end.
Setting up and managing a data warehouse involves a lot of money as the data in an organization continuously increases and the organization has to continuously upgrade their data storage servers. So here AWS Redshift comes into existence where the companies store their data in the cloud-based warehouses provided by Amazon.
Also Read: AWS OpsWorks
12. What is Amazon Redshift and why is it popular among other cloud data warehouses?
Answer: Amazon Redshift is a fast and scalable data warehouse which is easy to use and is cost effective to manage all the organization’s data. The database is ranged from gigabytes to 100’s of petabytes of cloud data storage. A person does not need knowledge of any programming language to use this feature, just upload the cluster and tools which are already known to the user he can start using Redshift.
AWS Redshift is popular due to the following reasons:
- AWS Redshift is very easy to use: In the console of AWS Redshift, you will find an option of creating a cluster. Just click on that and leave the rest on the machine programming of Redshift. Just fill the correct details as asked and launch the cluster. Now the cluster is ready to be used as Redshift automates most of the task like managing, monitoring and scaling.
- Scaling of Warehouse is very easy: You just have to resize the cluster size by increasing the number of compute nodes.
- Redshift gives 10x times better and fast performance: It makes use of specific strategies like columnar storage and massive parallel processing strategies to deliver high throughput and response time.
- Economical: As it does not require any setup so cost reduces down to 1/10th of the traditional data warehouse.
13. What is Redshift Spectrum?
Answer: The Redshift Spectrum allows you to run queries alongside petabytes of data which is unstructured and that too with no requirement of loading ETL. Spectrum scales millions of queries and allows you to allocate and store the data wherever you want and whatever the type of format is suitable for you.
Also Read: AWS Solutions Architect Interview Questions
14. What is a leader node and compute node?
Answer: In a leader node the queries from the client application are received and then the queries are parsed and the execution plan is developed. The steps to process these queries are developed and the result is sent back to the client application.
in a compute node the steps assigned in the leader node are executed and the data is transmitted. The result is then sent back to the leader node before sending it to the client application.
15. How to load data in Amazon Redshift?
Answer: Amazon DynamoDB, Amazon EMR, AWS Glue, AWS Data Pipeline are some of the data sources by which you can load data in Redshift data warehouse. The clients can also connect to Redshift with the help of ODBC or JDBC and give the SQL command ‘insert’ to load the data.
AWS Database Interview Questions: RDS
Amazon Relational Database Service has become an important aspect which allows a user to create and operate relation database. Here we are proving you with the Amazon AWS RDS Interview Questions so that you may also get knowledge about Amazon RDS interview questions asked in the interview.
16. What is Amazon RDS?
Answer: RDS stands for Relational Database Service by which a user can easily manage and scale a relational database in the cloud. You can focus on your application and business instead of managing the time-consuming data administration works. The user can access his files anywhere on the go with high scalability and cost-effective manner.
The code and applications that you use today with the existing database like MySQL, MariaDB, Oracle, SQL Server work efficiently with Amazon RDS. It automatically backups the database and updates regularly with the latest version.
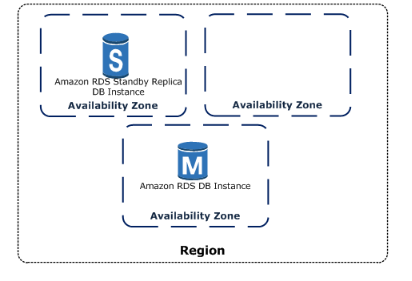
17. Mention the database engines which are supported by Amazon RDS.
Answer: The database engines that are supported by Amazon RDS are Amazon Aurora, MySQL, MariaDB, Oracle, SQL Server, and PostgreSQL database engine.
18. What is the work of Amazon RDS?
Answer: When a user wants to set up a relational database then Amazon RDS is used. It provisions the infrastructure capacity that a user requests to install the database software. Once the database is set up and functional RDS automates the tasks like patching up of the software, taking the backup of the data and management of synchronous data replication with automatic failover.
Also Read: High Availability using AWS RDS Multi-AZ and Read Replica
19. What is the purpose of standby RDS instance?
Answer: The main purpose of launching a standby RDS instance is to prevent the infrastructure failure (in case failure occurs) so it is stored in a different availability zone which is a totally different infrastructure physically and independent.
20. Are RDS instances upgradable or downgradable according to the need?
Answer: Yes, you can upgrade the RDS instances with the help of following command: modify-db-instance. If you are unable to detect the amount of CPU needed to upgrade then start with db.m1.small DB instance class and monitor the utilization of CPU with the help of tool Amazon CloudWatch Service.
AWS Database Interview Questions: ElastiCache
Caching is a technique to store the information in a temporary location which is frequently used. Amazon ElastiCache is an in-memory service provided by Amazon. It also plays an important role in the interviewers as it is also a favorite topic for the interviewers. So we will have a look at some of the top AWS ElastiCache interview questions for your interview preparation.
21. What is Amazon ElastiCache?
Answer: Amazon ElastiCache is an in-memory key-value store which is capable of supporting two key-value engines – Redis and Memcached. It is a fully managed and zero administrations which are hardened by Amazon. With the help of Amazon ElastiCache, you can either build a new high-performance application or improve the existing application. You can find the various application of ElastiCache in the field of Gaming, Healthcare, etc.
22. What is the use of Amazon ElastiCache?
Answer: The performance of web applications could be improved with the help of the caching of information that is used again and again. The information can be accessed very fast using in-memory-caching. With ElastiCache there is no need of managing a separate caching server. You can easily deploy or run an open source compatible in-memory data source with high throughput and low latency.
23. What are the benefits of Amazon ElastiCache?
Answer: There are various benefits of using Amazon ElastiCache some of which are discussed below:
- The cache node failures are automatically detected and recovered.
- It can be easily integrated with other AWS so as to provide a high performance and secured in-memory cache.
- As most of the data is managed by ElastiCache such as setup, configuration, and monitoring so that the user can focus on other high-value applications.
- The performance is enhanced greatly as it only supports the applications which require a very less response time.
- The ElastiCache can easily scale itself up or scale down according to the need.
24. What is an ElastiCache cluster?
Answer: A cluster is a collection of nodes. When you have a Memcached node then the nodes can be in multiple availability zones and in case of Redis cluster there is only a single node i.e. the master node and does not support data partitioning.
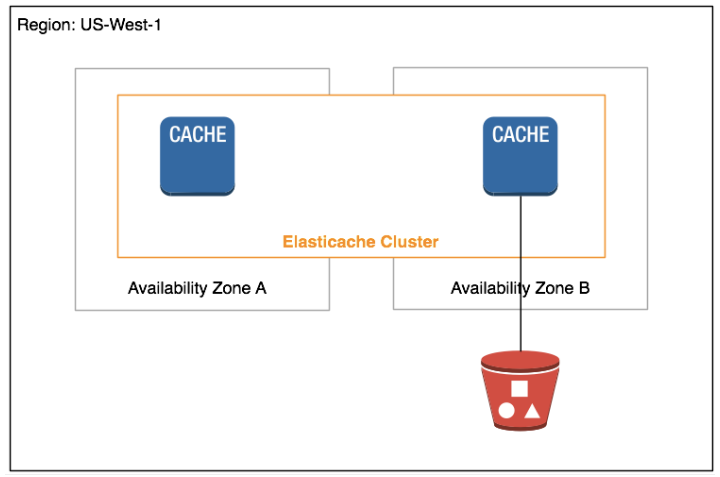
25. Explain the types of engines in ElastiCache.
Answer: There is two type of engine supported in Elasticache: Memcached and Redis.
Memcached
It is a popular in-memory data store which the developers use for the high-performance cache to speed up applications. By storing the data in memory instead of disk Memcached can retrieve the data in less than a millisecond. It works by keeping every value of the key for every other data to be stored and uniquely identifies each data and lets Memcached quickly find the record.
Redis
Today’s applications need low latency and high throughput performance for real-time processing. Due to the performance, simplicity, and capability of redis, it is most favored by the developers. It provides high performance for real-time apps and sub-millisecond latency. It supports complex datatypes i.e. string, hashes, etc and has a backup and restore capabilities. While Memcached supports key names and values up to 1 MB only Redis supports up to 512 MB.
Also Read: Top AWS Developer Interview Questions
AWS Database Interview Questions for Experienced
If you are an experience AWS database professional and preparing for the next job interview, you need to be prepared well. The interviewer will ask you more difficult and scenario-based questions to check your knowledge and experience as well. So, here we bring some of the top AWS database interview questions for experienced that are frequently asked in Amazon AWS interview.
26. Can you differentiate DynamoDB, RDS, and RedShift?
Answer: DynamoDB, RDS, and RedShift these three are the database management services offered by Amazon. These can be differentiated as –
Amazon DynamoDB is the NoSQL database service which deals with the unstructured data. DynamoDB offers a high level of scalability with faster and inevitable performance.
Amazon RDS is the database management service for the relational databases which manages upgrading, fixing, patching, and backing up information of the database without your intervention. RDS is solely a database management service for the structure data.
Amazon RedShift is totally different from RDS and DynamoDB. RedShift is a data warehouse product that is used in data analysis.
Features |
Amazon DynamoDB |
Amazon RDS |
Amazon RedShift |
| Primary Usage | Database for dynamically modified unstructured data | Conventional databases | Data warehouse |
| Computing Resources | Non-specified, SaaS (Software-as-a-Service) | Instances with 64 vCPU and 244 GB RAM | Nodes with vCPU and 244 GB RAM |
| Database Engine | NoSQL | MySQL, SQL Server, Oracle, Aurora, Postgre SQL, MariaDB | RedShift |
| Maintenance Window | No impact | 30 minutes every week | 30 minutes every week |
| Multi A-Z Replication | In-built | Additional service | Manual |
27. Is it possible to run multiple DB instances for free for Amazon RDS?
Answer: Yes, it is possible to run more than one Single-AZ micro DB instance for Amazon RDS and that’s for free. However, if the usage exceeds 750 instance hours across all the RDS Single-AZ micro DB instances, billing will be done at the standard Amazon RDS pricing across all the regions and database engines.
For example, consider we are running 2 Single-AZ micro DB instances for 400 hours each in one month only, the accumulated usage will be 800 instance hours from which 750 instance hours will be free. In this case, you will be billed for the remaining 50 hours at the standard pricing of Amazon RDS.
28. Which AWS services will you choose for collecting and processing e-commerce data for real-time analysis?
Answer: I’ll use DynamoDB for collecting and processing e-commerce data for real-time analysis. DynamoDB is a fully managed NoSQL database service that can be used for any type of unstructured data. It can even be used for the e-commerce data taken from e-commerce websites. On this retrieved e-commerce data, analysis can be then performed using RedShift. Elastic MapReduce can also be used for analysis but we’ll avoid it here as real-time analysis if required.
29. What will happen to the dB snapshots and backups if any user deletes dB instance?
Answer: When a dB instance is deleted, the user receives an option of making a final dB snapshot. If you will do that it will restore your information from that snapshot. AWS RDS keeps all these dB snapshots together that are created by the user along with the all other manually created dB snapshots when the dB instance is deleted. At the same time, automated backups are deleted while manually created dB snapshots are preserved.
30. When will you prefer to use Provisioned IOPS over normal RDS storage?
Answer: The provisioned IOPS will deliver high IO rates in case of batch-oriented workloads but at the same time, it is a high ticket. On the other hand, execution workloads don’t require manual intervention as they allow complete utilization of systems, so RDS storage is good enough for those. It specifies that we should prefer Provisioned IOPS over normal RDS storage for the batch-oriented workloads.
Final Words
So, here we have discussed some of the latest AWS Database interview questions that will be extremely useful in your AWS interview preparation. The companies that are using AWS services will be asking these questions in the interview. Also, to crack the interview, you need to be fully confident about your answer. The interviewer may try to confuse you but you must stick to your answer.
Certifications are also considered as an add-on to your profile in an interview. If you are going for an AWS interview, having an AWS credential in your resume will increase your chances of getting selected in the job. With the aim of helping you pass an AWS certification and crack the AWS interview, we provide best-in-industry AWS Certifications training. Join us and get ahead towards the bright AWS career.
Have any question regarding AWS database interview? Ask us in the comment below, we’ll be happy to answer.
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024

Does the author work for AWS. This list of questions and answers seem like one big Ad.