
Amazon Elasticsearch Service is the powerhouse to help you deploy, operate & scale respective Elasticsearch clusters within the AWS cloud. Amazon Elasticsearch offers you direct access to the Elasticsearch APIs and automatically replaces the failed nodes. If you intend to use AWS Elasticsearch for your operations, then it is better for you to know about some of the crucial factors associated with it.
Important Points about AWS Elasticsearch
In this article, you will know about some of the crucial elements or factors that will help you decide whether to invest in Amazon Elasticsearch Service. Let’s dive in!
-
Supported Versions of Elasticsearch
Amazon Elasticsearch Service supports the latest version of Elasticsearch that is 7.10. Apart from that, Amazon ES has support for all the older versions as well. However, compared to the older Elasticsearch versions, the 6.0+ and 7.1+ versions consist of some powerful features that improved their responsive speed, security aspects, and ease of use.
Some of the highlights you get with the latest version support of Elasticsearch include:
- High-Performance Indexing- The latest versions of Elasticsearch offers superior capabilities of indexing to the users. Hence, it results in an increased data update throughput.
- Vega visualization- Kibana version 6.2 and above offer support for the language of Vega visualization. With it, you can expect to make Elasticsearch queries that are aware of the context. Along with that, it allows you to combine multiple sources of data and blend them into one graph. With Vega visualization, you can also prefer to add user interactivity upon graphs and implement many more operations to streamline the task.
- Safeguards the Performance- With the latest versions of Elasticsearch supported by Amazon ES, you can expect to eradicate negative effects upon the cluster’s stability & performance due to complex or over-broad queries.
- High-Level Java REST Client- The high-level client intends to offer a more simplex development initiative, as compared to the low-level client. Moreover, it also supports most of the Elasticsearch APIs for integration.
When you are planning on starting a new AWS Elasticsearch project, it is important for you to go with the latest version. In case you have a domain that is integrated with the older version of Elasticsearch, you can either decide upon keeping the domain and create a new one or migrate the existing data to a newer version over Amazon ES.
Learn Now: How to Create a Domain in AWS Elasticsearch
-
Usability of Amazon ES with other AWS Services
Amazon ES is offering ideal integration potential to the users by adding up the capabilities of using it with all other AWS services. Some of the AWS services that are used with Amazon Elasticsearch Service are:
- Amazon CloudWatch- Amazon ES domains are meant to automatically send efficient metrics to Amazon CloudWatch for monitoring the performance & health of the domain. You can also configure the CloudWatch Logs for streaming data to Amazon Elasticsearch Service for detailed analysis.
- AWS CloudTrail- Using AWS CloudTrail with Amazon ES can get you a complete history associated with the configuration of Amazon ES. Along with that, you can also keep a check on the API calls and other associative events upon the account.
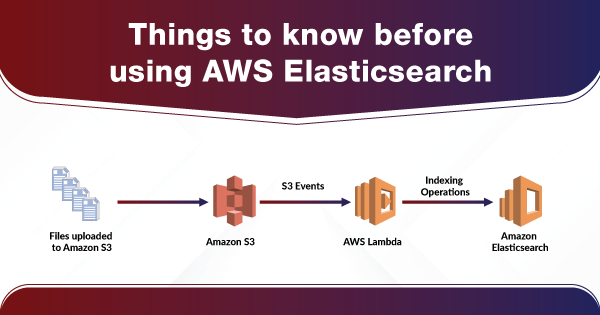
- Amazon S3- Amazon S3 or Simple Storage Service offers internet storage to the users. You can load streaming data from Amazon S3 to Amazon Elasticsearch Service.
- AWS IAM- AWS IAM, or Identity and Access Management, is preferably a web service that is destined to help you manage and control the access to Amazon ES domains.
- Amazon Quicksight- With the dashboards of Amazon Quicksight, you will be able to visualize the data within the Amazon ES domain. You can refer to this guide to know about how to use Amazon QuickSight with Amazon Elasticsearch Service.
- Amazon DynamoDB- AWS Lambda is a very popular compute service of Amazon. It allows you to run code without taking concern for server management or provisioning. You can use AWS Lambda for loading the streaming data to the Amazon Elasticsearch service. For more information on it, check out this guide.
- Amazon Kinesis- Kinesis is yet another managed service that intends to implement real-time processing of the streaming data on a bigger platform. You can load the streaming data onto the Amazon Elasticsearch service with the use of both Kinesis Data Streams and Kinesis Data Firehose.
-
Basic Approach to Amazon Elasticsearch Service
Before getting started with your first Elasticsearch project over Amazon ES, it is better to get a clear idea of your approach ideology. The first thing you need to do is sign-up for an AWS account or log in to the existing one. Once you are in your account, you need to take up the AWS Elasticsearch tutorial to ensure that you know about the core approach methods that include creating a domain, sizing the domain, choosing the access control for a domain, uploading data to the domain, searching data, creating a visualization, data indexing, and others.
-
Know About Perfect Deployment of Amazon ES
Irrespective of whether you deploy Amazon Elasticsearch Service on AWS Management Console, Amazon ES APIs, or AWS CloudFormation, you need to know your options for configuring the hardware of your domain. You need to choose the option by referring to the security features and high availability.
For configuring the domain of your Amazon ES, you need to choose the type of instance, along with the master nodes for it. Elasticsearch runs upon a cluster of nodes and instances. Different node types come with different functions and demand different sizing. Amazon ES supports five instance classes, T, C, I, R, and M. But the latest generation instance versions from each class are T2, C5, I3, R5, and M5.
For the perfect deployment of Amazon ES, you need to learn about how you can choose your instance type for the data nodes. While you choose the type of instance for the nodes, you need to keep in mind that all data within your indexes are being carried out by these nodes. These nodes do all the necessary processing for the request put by you and act as the Central Processing Unit (CPU).
Therefore, if you are working with heavy production workloads, then you should prefer to choose I3 or R5 type. As per the performance aspect is considered, the R5 type is said to deliver the best of all performance with respect to log analytics associated workloads. On the other hand, an I3 type is also a high-end option for handling the workloads, for which you should try them both to see what suits the best for your needs. If you are willing to choose the instance type based upon cost, then I3 is more cost-effective than R5, with very little difference in terms of performance.
If you have a smaller workload, you can definitely go ahead and choose the M5s. It is the perfect type for entry-level instances. The C5s are counted as a specialized type of instance that is relevant and reliable for heavy use case queries that demand more processing work than network or disk. The T2 instance types are well-preferred for QA workloads and development but are not meant for production. The C5 instances are proficiently known as the dedicated masters that have around 75 data node clusters. If you are in need of something more than that, then R5 is the ideal option!
Knowing the types of instances will help you understand the number of instances you need to suit your project. Along with that, you will be able to put up a deeper analysis of the data handling footprint. For perfect deployment, considering the availability zones is equally important as that of choosing the instance type. Amazon ES can increase the availability of the cluster by implementing the use of the Zone Awareness feature. You get to choose the deployment of your master nodes and data to up to 3 availability zones. For the best practice, you should make sure of choosing three Availability Zones for deployments associated with production.
When you prefer to choose more than one availability zone, Amazon Elasticsearch Service takes care of equal deployment of data nodes across all the zones. Moreover, in the process, it makes sure that the node replicas are sent to different available zones. Hence, choosing more than one Availability Zone is destined to increase the availability of your domain and enhance the stability aspects as well.
-
Know About the Elasticsearch Shard Design and Index
When you prefer to use Amazon Elasticsearch Service, you are required to upload the data onto indexes within the cluster. An index is referenced to be a table within the relational database. For the specific use cases associated with log analytics, you have the potential to control the data life cycle within the cluster. And, for that, you can choose a rolling indexing pattern. When you create a new index every day, make sure to archive & delete the older one present within the cluster.
The data partitions within the Amazon Elasticsearch Service are termed as shards. The shard count should be configured for better seamless operations. Also, there are basically two types of shards, primary shards and replica shards. The primary shard count specifies the number of data partitions created by Elasticsearch. The replica shard count specifies the number of additional copies of the primary shards that are created by Elasticsearch.
Once you set the primary shard count, you are not recommended to change it. You can set the primary shard count while you are creating the index. Along with that, you can also set the replica shards to count at the index creation phase, but the difference is that you can change it over time. Elasticsearch makes adjustments while creating or removing the replicas.
Bottom Line
These are a few of the things that you need to consider before you can start working with Amazon Elasticsearch Service. You need to make sure that you understand all of the core aspects of Amazon ES before you can start your first project. Moreover, remember that you will be paying hourly for the use of EC2 instance for Amazon ES.
Along with that, you will also be paying for any of the EBS storage volumes that are used upon your instances. The standard AWS data transfer charges will also be applied to the overall bill. But, collectively, it is a cost-effective service that you can master!
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024
