

Storing data within a database is a necessity for organizations. You might have the urge to store a mass amount of data for organizational operations. But you might miss out on an ideal resource for the same! Therefore, Cloud BigTable is a one-of-a-kind table that can be scaled to over thousands of columns and billions of rows. It allows you to store around terabytes and petabytes of data seamlessly.
One value within each row gets indexed within this table, and that is known as the ‘row key.’ The latency is really low over BigTable but has a high potential of storing a large amount of data. It offers supportability for reading and writing throughput! Moreover, it acts as a prominent data source for all of the MapReduce operations. BigTable is accessible by other Google Cloud applications, with the use of multiple client libraries.
In this article, you will get a clear insight into what BigTable is and how it can help organizations thrive.
Overview of BigTable
BigTable is the data storing hub, which is preferable for applications that demand high scalability and throughput for value or key data. Each of the values should be less than 10MB to be stored over BigTable assembly. It also consists of a storage engine responsible for streamlining the MapReduce operations, machine-learning applications, and stream analytics or processing aspects.
BigTable is a prominent database for several applications such as Google Personalized Search, App Engine Datastore, Google Analytics, Google Earth, and others. It has the potential of increasing the cluster size for a certain period of time to make it able to handle larger loads. After the job is done, the cluster size can be reversed or reduced again. All of this can be done without experiencing any organizational downtime.
Google has prioritized maintaining the software as an in-house technology. And this software has implemented a great impact on the NoSQL database architecture. Google has explained detailed working aspects of BigTable and has elaborated its internal process of operation. As a result, the bigger organizations and development teams started to look for ways to create BigTable derivatives. Some of the examples for the same are Hypertable, Cassandra, Apache HBase database, and others.
Even with all of the derivatives out in the play, BigTable stood strong and made its appeal loud and clear to the organizations. BigTable allows you to store time-series data, financial data, IoT data, graph data, and marketing data as well. It is a huge set of feasibility that helps organizations utilize data in better ways!
Working Potential of BigTable
Google BigTable is a column-specific data store that can handle structured data with respect to the web services operations and the company’s internet searches. The original integration of BigTable was for offering support to the applications that demand high scalability. The design of this database was meant to be deployed within clustered systems to make use of a simpler data model.
The data within BigTable undergoes an assembling process with the use of a row key. The indexing of the map is then arranged as per the timestamps, row key, and column key. It also makes use of compression algorithms to help leverage high capacity. Data compression is a form of reduction of the number of bits that are essential for representing data. Compressing data intends to save some amount of storage.
BigTable consists of impactful back-end servers that offer enhanced perks than that of the self-managed HBase installation aspects. Scalability is the most important benefit of BigTable that allows it to scale in direct proportion to that of the number of machines within the cluster. The HBase installation consists of a loophole within its technology that limited the performance after a certain threshold was achieved.
But it is not the case with BigTable, as there are no limitations with it. You can potentially scale the clusters as per your needs to handle more read & write thresholds. Moreover, BigTable also maintains durability for the data automatically, without manual assistance. If you want to replicate the existing data within BigTable, you just have to create another cluster to the existing instance. The data replication will begin automatically!
The Architecture of BigTable
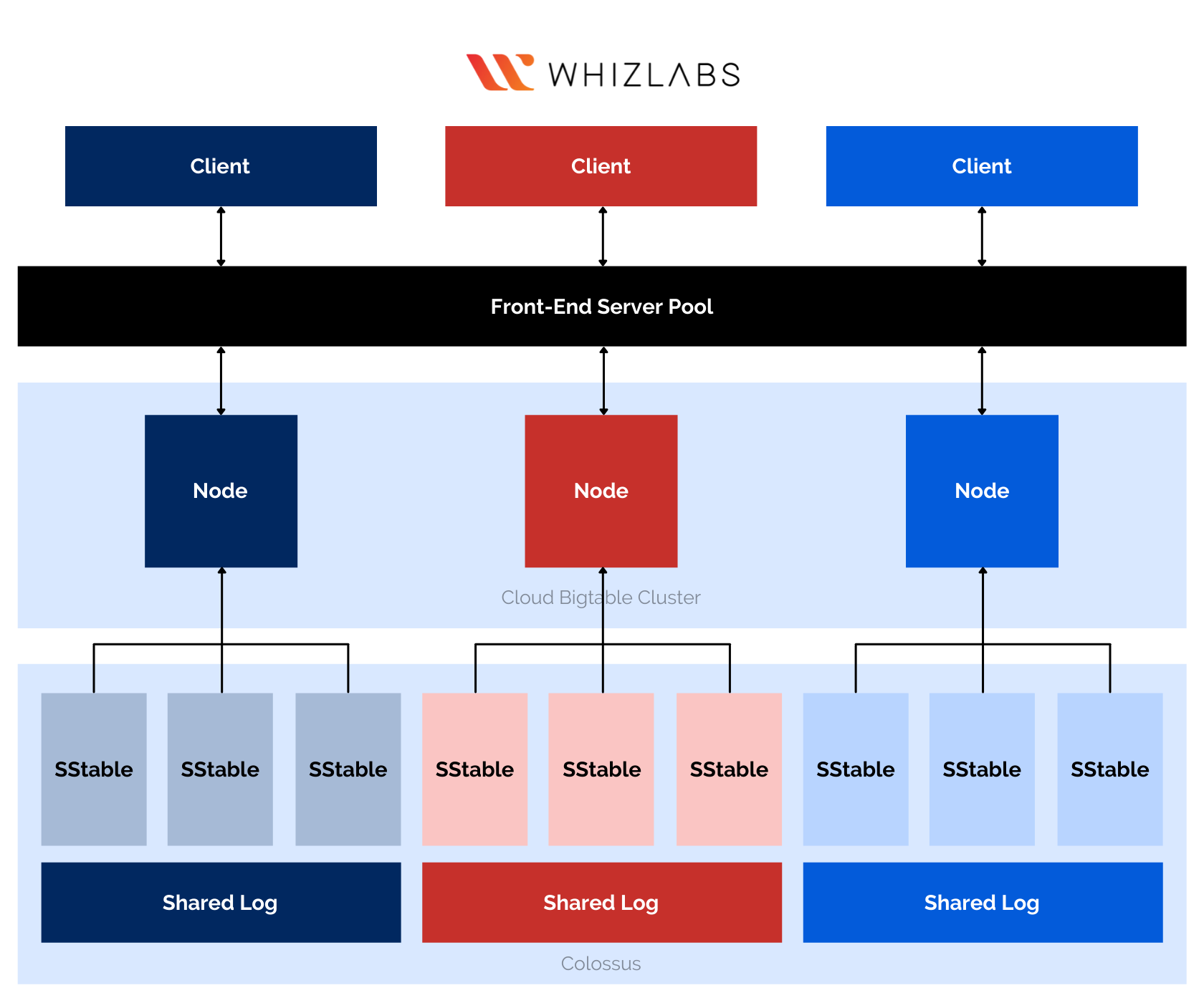
The architecture of BigTable is simple and sorted! First, the requests that come from the client’s send passes through the front-end servers. It is mandatory for all of the requests to pass through the front-end server pool before they can reach the specific BigTable node. As of the original revelation of BigTable, the BigTable nodes were referred to as ‘tablet servers.’ If you want to check out the original BigTable paper, then refer to this link!
The nodes are organized in the form of a BigTable cluster that belongs to a specific BigTable instance, which is also a cluster container. Each node within the cluster is responsible for handling the subset of all the requests that enter the cluster. By adding more nodes to a specific cluster, you can plan on increasing the potential of the cluster upon handling more requests. Moreover, the maximum throughput potential will also increase for the cluster.
If you intend to replicate the data within the existing cluster, you will have to create a second cluster within the same instance. On replicating data to another cluster, you can also direct different traffics to each of the clusters. A BigTable consists of several blocks of rows that share the same border. They are termed ‘tablets’! They will help you in balancing the query workloads.
All of the tablets are stored over a file system by Google, Colossus. These tablets are stored within SSTable format. If you are keen to learn more about SSTable, you can visit this documentation page for the same. The role of the SSTable format is to offer a persistent & immutable map. Each tablet has a specific node! Along with SSTable files, all the write throughput operations embedded within BigTable are also stored over the shared log of Colossus. It is to offer enhanced durability to the data!
BigTable Nodes and Tablets
Firstly, you need to understand that no data is ever stored over BigTable nodes. As soon as BigTable identifies the data, each node directs its pointers to a certain set of tablets. And the data is passed onto them! Now, these tablets are then stored over the Colossus. The rebalancing of tablets from one node to the other is seamless and fast. It is because the actual data is not at all copied. Instead, BigTable just updates its node pointers to respective tablets.
The recovery potential in case of BigTable node failure is also streamlined and fast. In such a situation of node failures, the metadata is the only aspect that needs migration to that of the replacement node. You can be assured of losing no data on Bigdata node failure. Instances, nodes, and clusters are the fundamental blocks that build this entire database of BigTable. Redirect yourself to this documentation, and learn more about the working potential of instances, nodes, and clusters.
Key Capabilities of BigTable
The organizations demand the use of the database for achieving and maintaining their growth with ideal analytic implementations. And for that, the databases you use should have some high-end potential and capabilities. BigTable comprises the 7 key capabilities that are essential for a business to thrive. BigTable offers you the scope of personalization, speed, and automation.
Apart from that, the key capabilities include:
1. Large-Scale Storage
BigTable offers you the potential for capturing high amounts of data and use it for machine learning and analytics.
2. Integration with ML Tools
With BigTable, you can run Machine Learning algorithms for deriving recommendations and predictions.
3. High Throughput
All the data that intends to change rapidly can be accommodated with a high count of reading and write throughputs.
4. Latency is Low
Low latency resembles high-speed on-site performance. You will get the response for lookups or data searches in a matter of milliseconds.
5. High Availability
BigTable can constantly operate without downtime or breakdown to serve the customers without fail.
6. High Scalability
BigTable is scalable to cater to many requests and users automatically without any overloading aspect.
7. Fully-Managed Database
BigTable, being fully managed, allows the developers to direct their focus upon app development aspects instead of giving their attention to databases. Google BigTable is handling that part seamlessly!
Purpose of Rows, Columns, and Cells within 3D Map Structure
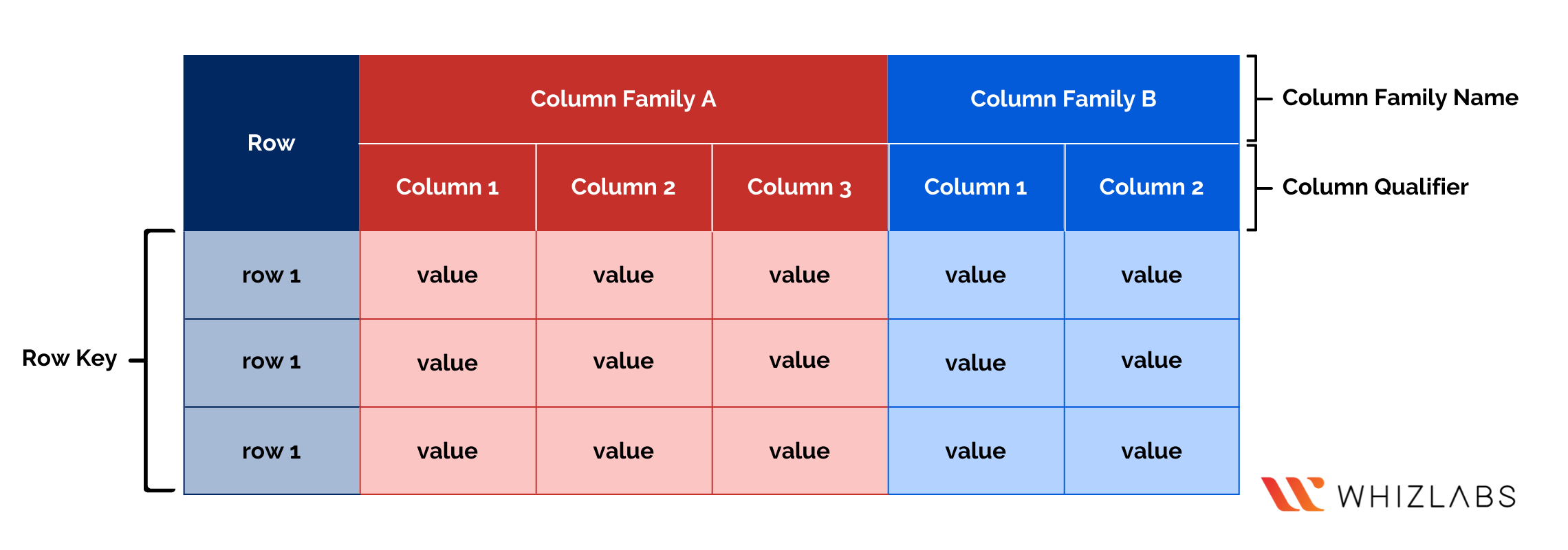
The data within BigTable is stored in the form of 2 dimensions, which are rows and columns. But this is not similar to that of the relational databases, as there are slight complications within BigTable that make it different and better.
1st Dimension- Rows
Each row has a unique identification or index that is stated as a single row key. The data that is stored within BigTable undergoes automatic sorting with respect to row keys in alphabetical order. This sorting technique is also known as lexicographical sorting, making scans & searches fast and easy across the table.
2nd Dimension- Columns
Now, the related data is then grouped within column families. For instance, basic profile details such as name, mobile number, and email address can be grouped on a select column family. In contrast, the comments given by the users can be grouped in another column family. The sole purpose of columns is to gather all the possible information that might be frequently retrieved together. Hence, this will make it easy and fast for the users to look for their selected data.
Each of the columns within the same family consists of a specific column qualifier. Column qualifiers are similar to row keys, which helps in column identification. Column identification is carried out by the combination of family name and qualifier. The column qualifiers are in alphabetical order for increasing the query speed. Keep in mind that two-column families within one table should not have the same name. Moreover, two columns should also prohibit having the same column qualifiers.
In case any of the columns are empty, without any data over it, then that column is not consuming any storage or space. Therefore, BigTable is accountable for being titled a sparse database.
3rd Dimension- Cells
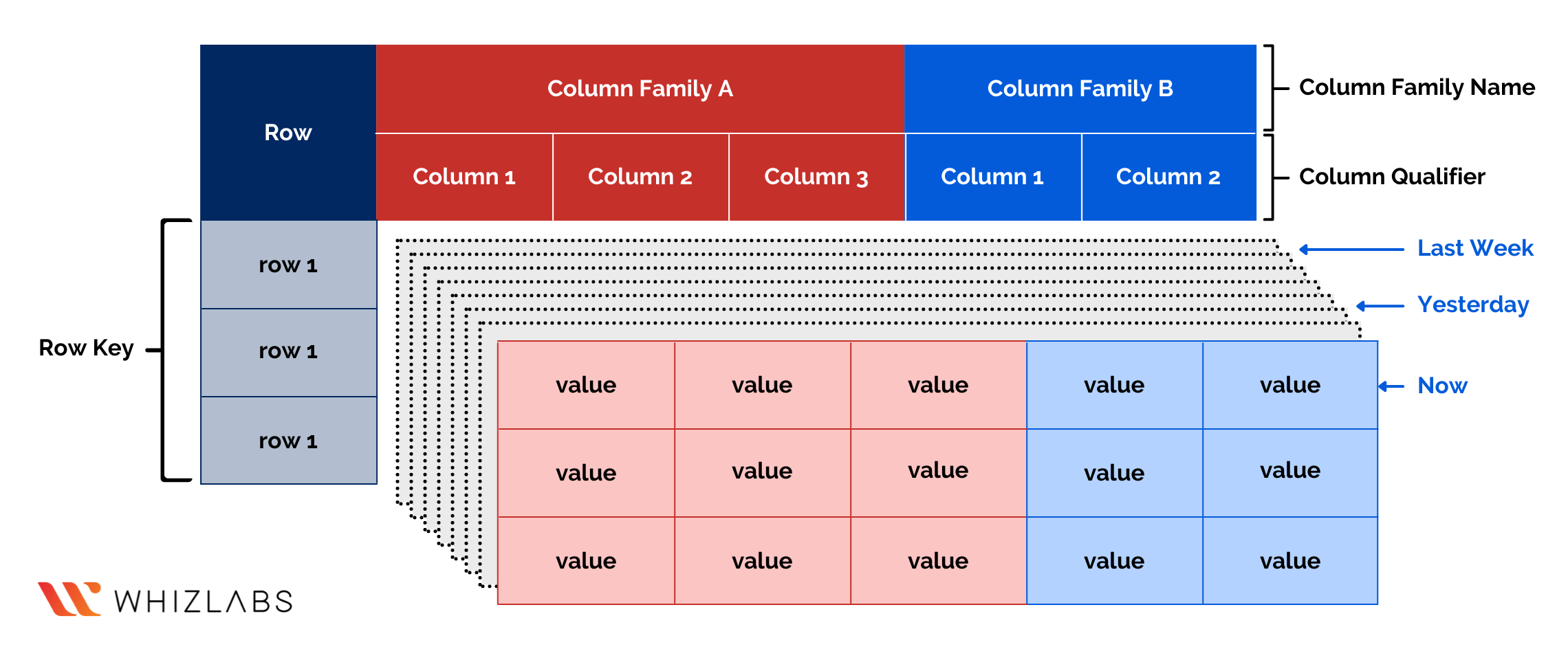
Now that you know the basic fundamentals of storing data over BigTable, it is time to introduce the third dimension. This dimension is responsible for making it different from other relational databases.
When you look for a row key and zoom to get insight into a particular column, you would generally expect to see a single value. But within BigTable, you will eventually see variable versions of that particular column value in different time points. Each of the timestamp versions is termed a cell. And it is the third dimension within this 3D map structure of BigTable.
The third dimension is optional for the organizations to implement. But with this positive complication, the data storage and retrieval will become more efficient in the long run with the use of BigTable.
You need this dimension because the data stored with BigTable intends to change very fast in the long run. For instance, one customer can choose to view one product and then switch to another immediately. Similarly, a user might be listening to any particular song, but the mood didn’t match, so they changed to another in just 20 seconds. Hence, you can now relate to how data changes rapidly.
Therefore, adding the third dimension of cells is important to help you see the history of data within a row. You will be able to view the products that your customer checked last week or the songs your customers listened to the day before. It will help you implement better data analytics and will lead you to know your customers well. Knowing the customers will help improve the business services.
Final Words
These are a few of the things that you need to keep in mind about BigTable. It is not just any ordinary database but a special business tool. It can literally help you go back in time to know the best interactions for ideal analysis. Cloud BigTable is a powerful database that has the ability to power mobile sites and apps with personalization and speed.
So, if you are convinced about the potential of this Google database, BigTable, then go ahead and get some hands-on experience. It will help you improve your approach towards your targeted audience.
Assess your knowledge Now – Click Here
No Credit Card Required
- Cloud DNS – A Complete Guide - December 15, 2021
- Google Compute Engine: Features and Advantages - December 14, 2021
- What is Cloud Run? - December 13, 2021
- What is Cloud Load Balancing? A Complete Guide - December 9, 2021
- What is a BigTable? - December 8, 2021
- Docker Image creation – Everything You Should Know! - November 25, 2021
- What is BigQuery? - November 19, 2021
- Docker Architecture in Detail - October 6, 2021

