

If you’re looking for some free questions on DP-300: Administering Microsoft Azure SQL Solutions, then you’ve come to the right place! Here we provide some of the free DP-300 practice exam questions that you can use to test your knowledge and skills.
In this blog, we will cover newly updated 20+ Free questions on the Administering Microsoft Azure SQL Solutions DP-300 certification exam which are very similar to the practice test as well as the real exam.
Let us dive into the topic!
Why do we provide DP-300 exam questions on Microsoft Azure SQL Solutions Certification for free?
We provide Microsoft Azure SQL Solutions Certification DP-300 exam questions for free because we want to help people learn about this certification and pass the exam. This certification is important for people who want to work in the cloud computing field, and it can help them get jobs and advance their careers.
In addition, note that the exam syllabus covers questions from the following domains:
![]()
- Implement a secure environment (15–20%)
- Monitor, configure, and optimize database resources (20–25%)
- Configure and manage automation of tasks (15–20%)
- Plan and configure a high availability and disaster recovery (HA/DR) environment (20–25%)
- Plan and implement data platform resources (20–25%)
Domain: Implement a secure environment (15—20%)
Question 1 : You are designing a multi-tenant enterprise data warehouse using Azure Synapse that holds some crucial data for a Medical and health Insurance company. This data relates to sensitive Protected Health information about patients’ ailments and diagnoses.
You need to create a solution to provide Health information management professionals the ability to view all basic entries in patients such as Name, Home Address, and Email.
The solution must avert all Health information management professionals from viewing or inferring demographic information, medical histories, test and laboratory results, mental health conditions, and insurance information.
What should you include to complete this requirement?
A. Data Masking
B. Always Encrypted
C. Transparent Data Encryption
D. Row-level security
Correct Answer : D
Explanation :
Option A is incorrect because we need to recommend a solution that restricts users from viewing or inferring sensitive information. Data Masking is a feature that hides data elements that a user may not have access to. The main objective of data masking is creating an alternate version of data that cannot be easily identifiable or reverse-engineered, protecting data classified as sensitive. Importantly, the data will be consistent across multiple databases, and the usability will remain unchanged.
Option B is incorrect because ‘Always Encrypted’ uses cryptographic keys to protect data. There is no such requirement of the question where you need to encrypt and decrypt data using column encryption keys. The question requirement is to filter sensitive data basis the user accessing it. There is no need of encrypting the data. Thus, this option does not hold as a suitable option.
Option C is incorrect because ‘Transparent data encryption (TDE)’ helps protect Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics against the threat of malicious offline activity by encrypting data at rest. As per the question asked we need to filter data to which a user can not have access, therefore this option isn’t suitable.
Option D is CORRECT because the default RLS behavior is to filter data that a specific user is not supposed to see thereby making him/her unable to see the entire dataset.
The Advantage of using row-level security is it reduces your application development complexity. Without RLS, you’d generally create filters with your queries or through ORM (Object Relational Mapping), or pass on filtering criteria to your procedures.
With RLS, security is at the DB level. If another application was reading data in a different language from a different platform, RLS still allows user1 to see what you want user1 to see. Your DB backup and restore will keep RLS intact.
Check out : DP-300 Exam Preparation Guide on Administering Microsoft Azure SQL Solutions
Question 2 : You have a dedicated virtual machine that monitors and collects data from SQL Server instance on Azure to investigate performance issues.
The dedicated machine has the following components installed.
- Azure Monitor Agent
- Workload Insights extension
To get started with SQL Insights, from the Monitor blade, we create a profile after selecting SQL (preview).
Name the component we need to configure from “Create profile Page” that would help to send all monitoring data.
A. Monitoring profile
B. Collection settings
C. Log Analytics workspace
D. Azure Activity Log
Correct Answer : C
Explanation :
Option A is incorrect because the monitoring profile helps to group servers, instances, or databases to monitor and analyze as a combined set. It sets the scope of monitoring – whether it is a collection (development or production), application (billing or customer), or the collection settings (e.g., high-fidelity data collection vs low), etc. It has specific settings for Azure SQL Database, Azure SQL manage instance, and SQL server running on virtual machines.
Option B is incorrect because this customizes the data collection of your profile. Default settings cover the majority of monitoring scenarios and usually don’t need to be changed, these include Collection Interval, Azure SQL Database setting, Azure SQL managed instance setting, and SQL server setting.
Option C is CORRECT because this is where we send the SQL monitoring data. It’s the destination place for the SQL Monitoring data. Data from Azure resources in your subscription, on-prem computers monitored by the System Centre operation manager, device collections from the configuration manager, diagnostics or logs, data from azure storage, and SQL monitoring data are collected on the log analytics workspace.
Option D is incorrect because the Azure Activity Log is a platform that provides insight into subscription-level events. This is not a workspace to store logs from SQL monitoring.
Domain: Monitor, configure, and optimize database resources (20—25%)
Question 3: You have an Azure subscription and along with it you have a SQL Server Database which is causing a lot of performance issues.
You have set up an extended events engine in Azure SQL which is a lightweight and powerful monitoring system that allows you to capture granular information about activity in your databases and servers.
Which Channel within the Extended event is typically related to performance?
A. Admin Events
B. Operational Events
C. Analytic Events
D. Debug Events
Correct Answer : C
Explanation :
Option A is incorrect because Admin Events are targeted at end users and administrators. The events indicate a problem within a well-defined set of actions that an administrator can take. An example of this is the generation of an XML deadlock report to help identify the root cause of the deadlock.
Option B is incorrect because Operational Events are used for the analysis and diagnostics of common problems. These events can be used to trigger an action or task based on the occurrence of the event. An example of an operational event would be a database in an availability group changing state, which would indicate a failover.
Option C is CORRECT because Analytic Events are typically related to performance events. Tracing stored procedures or query execution would be an example of an analytic event.
Option D is incorrect because Debug Events are not necessarily fully documented, and you should only use them when troubleshooting in conjunction with Microsoft support.
Domain: Monitor, configure, and optimize database resources (20—25%)
Question 4: You have a Microsoft Azure Subscription that holds an Azure SQL Managed Instance. This holds tables on various modules of an ERP system. You need to configure automatic tuning on the Azure SQL Managed Instance. Which Automatic tuning option is available for Instance database support?
A. FORCE_LAST_GOOD_PLAN
B. CREATE INDEX
C. DROP INDEX
D. CREATE PRIMARY KEY CONSTRAINT
Correct Answer : A
Explanation :
Option A is CORRECT because the FORCE_LAST_GOOD_PLAN identifies Azure SQL queries using an execution plan that is slower than the previous good plan, and forces queries to use the last known good plan instead of the regressed plan. By default, new servers inherit Azure defaults for automatic tuning settings. It simplifies the management of automatic tuning options for a large number of databases. Azure defaults are set to FORCE_LAST_GOOD_PLAN enabled, CREATE_INDEX disabled, and DROP_INDEX disabled.
Option B is incorrect because this option is not supported for Azure Managed instances, though it is available in a single and pooled database.
Option C is incorrect because this option is not supported for Azure Managed Instances, though it is available in a single and pooled database.
Option D is incorrect because creating primary constraints is for uniquely identifying rows at the table level. This has nothing to do with Automatic Tuning options being enabled at the server level.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/automatic-tuning-overview?view=azuresql
Domain: Plan and configure a high availability and disaster recovery (HA/DR) environment (20—25%)
Question 5 : You have an Azure SQL server virtual machine.
You need to back up the transaction log from the Primary server instance to the secondary server instance. Which option should you choose?
A. Implement ‘Always On’ availability groups
B. Configure transactional replication
C. Configure Transaction Log Shipping
D. Import a DACPAC
Correct Answer : C
Explanation :
Option A is incorrect because high availability disaster recovery encompasses two fundamental concepts. Firstly, how to minimize the amount of time your databases will be offline in the event of hardware failures, power outages, or any natural disasters. Secondly, it looks at how to minimize data loss when any of such events occur. It does not back up and stores the transaction log in the secondary server instance.
Option B is incorrect because transactional replication is used to solve the problem of moving data between continuously connected servers. By using the Replication Wizard, you can easily configure and administer a replication topology
Option C is CORRECT because Transaction Log shipping allows you to automatically send transaction log backups from a primary database on a primary server instance to one or more secondary databases on separate secondary server instances. The transaction log backups are applied to each of the secondary databases individually. An optional third server instance, known as the monitor server, records the history and status of backup and restore operations and, optionally, raises alerts if these operations fail to occur as scheduled.
Option D is incorrect because DACPAC is an acronym for Data-Tier Application Package. It is a logical database entity defining all database objects such as tables, views, users, and logins. It enables developers and database administrators to create a single package file consisting of database objects.
Drag and drop – matching
Domain: Plan and configure a high availability and disaster recovery (HA/DR) environment (20—25%)
Question 6 : You have a ‘server01’ running HADR with a primary role and it crashes. The DBA performs a HADR takeover by force on the ‘servers02’ to switch roles. The ‘server02’ now becomes the primary server. The below DMVs provide information on the state of a replica. Match the correct definition with their respective DMVs.
| DMV’S | ANSWER AREA | ||
| 1 | sys.dm_hadr_availability_replica_states | A | Returns a row for each Always On availability replica of all Always On availability groups |
| 2 | sys.dm_hadr_database_replica_states | B | Returns a row for each local replica and a row for each remote replica in the same Always On availability group |
| 3 | sys.dm_hadr_database_replica_cluster_states | C | Returns a row for each database that is participating in an Always On availability group for which the local instance of SQL Server is hosting an availability replica |
| 4 | sys.dm_hadr_availability_replica_cluster_states | D | Returns a row containing information intended to provide you with insight into the health of the available databases in the Always On availability groups in each Always On availability group on the Windows Server Failover Clustering cluster |
Correct Answer : 1-B, 2-C, 3-D and 4-A
Explanation :
sys.dm_hadr_availability_replica_states:
Returns a row for each local replica and a row for each remote replica in the same Always On availability group.
sys.dm_hadr_database_replica_states:
Returns a row for each database that is participating in an Always On availability group for which the local instance of SQL Server is hosting an availability replica.
sys.dm_hadr_database_replica_cluster_states:
Returns a row containing information intended to provide you with insight into the health of the available databases in the Always On availability groups in each Always On availability group on the Windows Server Failover Clustering cluster.
sys.dm_hadr_availability_replica_cluster_states:
Returns a row for each Always On availability replica of all Always On availability groups.
Drag and drop – matching
Domain: Plan and implement data platform resources (20—25%)
Question 7 : You have a Microsoft Azure SQL database instance. The data size is large. You are facing issues with storage, computing resources, and network while maintaining the performance of the database.
To solve this issue, you have implemented Database sharding where you divide a data store into a set of horizontal partitions or shards. Each shard has the same schema but holds a distinct subset of the data.
Match the below sharding strategies that are commonly used when selecting the shard key and decide how to distribute data across shards.
| PERFORMANCE TECHNIQUES | ANSWER AREA | |
| Lookup strategy | A | In this strategy groups related items together in the same shard and orders them by shard key—the shard keys are sequential. It’s useful for applications that frequently retrieve sets of items using these queries |
| Range strategy | B | The purpose of this strategy is to reduce the chance of hotspots (shards that receive a disproportionate amount of load). It distributes the data across the shards in a way that achieves a balance between the size of each shard and the average load that each shard will encounter. The sharding logic computes the shard to store an item based on a hash of one or more attributes of the data. |
| Hash strategy | C | In this strategy, the sharding logic implements a map that routes a request for data to the shard that contains that data using the shard key. In a multi-tenant application, all the data for a tenant might be stored together in a shard using the tenant ID as the shard key |
Correct Answer : 1-C, 2-A and 3-B
Explanation :
Lookup strategy: In this strategy, the sharding logic implements a map that routes a request for data to the shard that contains that data using the shard key. In a multi-tenant application, all the data for a tenant might be stored together in a shard using the tenant ID as the shard key
Range strategy: In this strategy groups related items together in the same shard and orders them by shard key—the shard keys are sequential. It’s useful for applications that frequently retrieve sets of items using these queries
Hash strategy: The purpose of this strategy is to reduce the chance of hotspots (shards that receive a disproportionate amount of load). It distributes the data across the shards in a way that achieves a balance between the size of each shard and the average load that each shard will encounter. The sharding logic computes the shard to store an item based on a hash of one or more attributes of the data.
References: https://learn.microsoft.com/enus/azure/architecture/patterns/sharding, https://learn.microsoft.com/en-us/training/modules/migrate-sql-workloads-azure-sql-databases/5-service-continuity-of-azure-sql-database
Drag and drop – Ordering
Domain: Plan and implement data platform resources (20—25%)
Question 8: You have a large production Azure SQL database named ‘bankdb’. You are running a reporting or analytics workload on this data that is causing performance issues.
To overcome this issue you decide to have a second database such that additional workload can be handled thereby minimizing the performance impact on your production workload. Data Sync helps you to keep the two databases synchronized. Below are the steps required to set up SQL Data Sync between databases. Identify the correct sequence from the options below.
A. Add a Database in Azure SQL Database
B. Add a SQL Server Database
C. Create a Sync group
D. Configure Sync Group
E. Add Sync Member
Correct Answer : C, E, A, B and D
Explanation :
To set up SQL Data Sync by creating a sync group that contains both Azure SQL Database and SQL Server instance. The sync group is custom configured and synchronizes on the schedule you set. Below are the steps to set up SQL Data Sync.
- Create a Sync group
- Add Sync Member
- Add a Database in Azure SQL Database
- Add a SQL Server Database
- Configure Sync Group
References: https://learn.microsoft.com/en-us/azure/azure-sql/database/sql-data-sync-data-sql-server-sql-database?view=azuresql, http://learn.microsoft.com/en-us/azure/azure-sql/database/sql-data-sync-sql-server-configure?view=azuresql
Domain: Configure and manage automation of tasks (15—20%)
Question 9: You have an Azure SQL manage instance that has a database named IBC-data that stores data in geo-redundant storage blobs which are replicated to a paired region. Match the following storage redundancies for backup.
| BACKUP STORAGE REDUNDANCIES | ANSWER AREA | |
| Locally redundant storage (LRS) | A | Copying your backups synchronously three times within a single physical location in the primary region using LRS. Then it copies your data asynchronously three times to a single physical location in the paired secondary region. |
| Zone-redundant storage (ZRS) | B | Copies your backups synchronously across three Azure availability zones in the primary region. |
| Geo-redundant storage (GRS) | C | Copies your backups synchronously three times within a single physical location in the primary region |
Correct Answer : 1-C, 2-B and 3-A
Explanation :
Locally redundant storage (LRS): Copies your backups synchronously three times within a single physical location in the primary region. LRS is the least expensive storage option, but we don’t recommend it for applications that require resiliency to regional outages or a guarantee of high data durability.

Zone-redundant storage (ZRS): Copies your backups synchronously across three Azure availability zones in the primary region. It’s currently available in only certain regions.
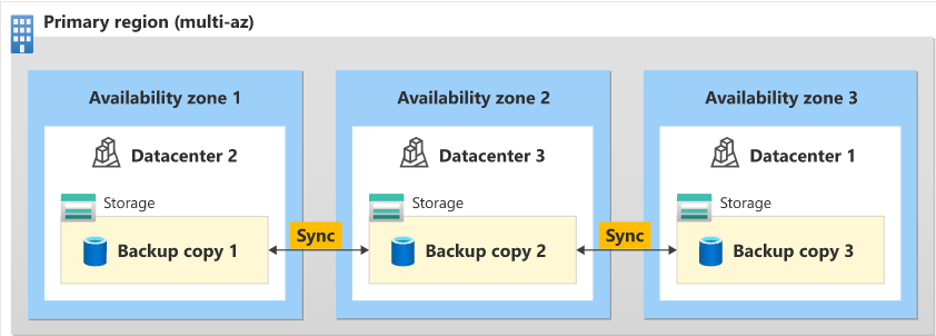
Geo-redundant storage (GRS): Copying your backups synchronously three times within a single physical location in the primary region using LRS. Then it copies your data asynchronously three times to a single physical location in the paired secondary region.
The result is
- Three synchronous copies in the primary region.
- Three synchronous copies in the paired region were copied over from the primary region to the secondary region asynchronously.
References: https://docs.microsoft.com/en-us/azure/azure-sql/database/automated-backups-overview?view=azuresql, https://docs.microsoft.com/en-us/azure/azure-sql/database/service-tier-hyperscale?view=azuresql
Domain: Configure and manage automation of tasks (15—20%)
Question 10: You have a Microsoft Azure SQL database instance running in the single-user mode for a POS application that manages sales and performs day to day operations of the retail store. We have a table named product_specification. The non-cluster index is created on columns
batch_number, name, description, and price. There was a loss of data due to a deadlock caused when multiple users started performing CRUD operations.
Which parameter option under the DBCC(Database Console Commands) check would ensure an integrity check for the given table with no data loss?
A. NOINDEX
B. REPAIR_FAST
C. REPAIR_REBUILD
D. REPAIR_ALLOW_DATA_LOSS
Correct Answer : C
Explanation :
Option A is incorrect because with NOINDEX intensive checks of non-clustered indexes for user tables will not be performed. NOINDEX doesn’t affect system tables because integrity checks are always performed on system table indexes.
Option B is incorrect because REPAIR_FAST is used to maintain syntax for backward compatibility only. No repair actions are performed.
Option C is CORRECT because it performs repairs with no possibility of data loss with quick repairs such as repairing missing rows in non-clustered indexes. It also involves rebuilding indexes which is time-consuming.
Option D is incorrect because it may not always be the best option for bringing a database to a physically consistent state. If successful, then also REPAIR_ALLOW_DATA_LOSS option may result in some data loss. It may result in more data loss than if a user wants to restore the database from the last known good backup.
Domain: Monitor, configure, and optimize database resources (20—25%)
Question 11 : An instance of Microsoft Azure SQL Server has a Sales Database with multiple objects. You have multiple indexes created on tables. Index pages are increasing massively because of the Insert and Update operation.
Name a stored procedure that provides all information about the fragmentation page and space.
A. dm_db_index_physical_stats
B. dm_db_column_store_row_group_physical_stats
C. dm_db_index_usage_stats
D. dm_db_index_operational_stats
Correct Answer : A
Explanation :
Option A is CORRECT because fragmentation and page density decides whether to perform index maintenance and which maintenance method to use. For indexes, sys.dm_db_index_physical_stats() determines fragmentation and page density for a specific index.
Option B is incorrect because it returns current row-level I/O, locking, and access method activity for compressed row groups in a column store index. It identifies row groups that are encountering significant I/O activity or hot spots.
Option C is incorrect because it returns counts of different types of index operations and the time each type of operation was last performed.
Option D is incorrect because it returns the current lower-level I/O, locking, latching, and access method activity for each partition of a table or index in the database.
Domain: Configure and manage automation of tasks (15—20%)
Question 12 : You need to run a Transact-SQL system stored procedure on the Microsoft Azure job agent database. For this, we need to add a new target server member to the target group containing server(s) and exclude a database target member MappingDB from the server target group. Identify the procedure that would help us perform the above tasks.
A. jobs.target_groups
B. jobs.sp_add_target_group
C. jobs.sp_add_target_group_member
D. jobs.target_group_members
Correct Answer : C
Explanation :
Option A is incorrect because it helps us view the recently created target groups.
Option B is incorrect because this adds or creates just the target group containing server(s), not the target member. A target could be an elastic pool, SQL Server, or an Azure database. Jobs operate with a target group, not an individual target.
Option C is CORRECT because this helps you add a server target member to the target group. Using the stored procedure, we can exclude a particular database or a pool group. For this, you need to set the membership type parameter as exclude. If you are targeting a server or pool of servers against the database, then you would use a refresh_credential_name
Option D is incorrect because this helps us view recently created target group members.
Type – Drag n drop – Aligning
Domain: Configure and manage automation of tasks (15—20%)
Question 13 : We have a SQL Server on an Azure VM named CHC-DB-SERVER which holds databases such as RV Medicare, and Medicaid for various clients of an insurance claim company. You add a user as a member of the sysadmin group who would be the SQL Agent operator such that it receives emails as an alert on every job failure. You need to perform certain actions from the below options to achieve the requirement.
A. Create a Job Alert
B. Enable Database Mail
C. Create a Job Notification
D. Enable Email setting for SQL Server Agent
E. Create a targeted Job
Correct Answers : B, D and E
Explanation :
To configure Database Mail, you must be a member of the sysadmin fixed server role.
To send an email with Database Mail, you must be a member of the DatabaseMailUserRole database role in the msdb database.
Then enable the database mail and the email setting for the SQL Server Agent. To send the notification in response to an alert, you must first configure SQL Server Agent to send emails.
Option A is incorrect because alerts, configured using the SQL Server Agent, are created to help us monitor our system effectively. The question here is to define what actions should be taken when we get an email Alert on every job failure.
Option C is incorrect because Job Notification is done to send Log Shipping notifications to all stakeholders.
References: https://learn.microsoft.com/en-us/sql/relational-databases/database-mail/configure-sql-server-agent-mail-to-use-database-mail?view=sql-server-ver16, https://learn.microsoft.com/en-us/sql/ssms/agent/assign-alerts-to-an-operator?view=sql-server-ver16
Type – Drag n drop – Aligning
Domain: Plan and configure a high availability and disaster recovery (HA/DR) environment (20—25%)
Question 14 : You have a Microsoft Azure SQL server virtual machine. You wish to install log shipping such that you could store backups on a dedicated SMTP file share. You need to configure servers to perform the Log Shipping step. Which server instance would you choose to configure and perform actions such as complete backup job & copy backup Job You can choose the same server instance for different actions performed.
A. Monitor Server Instance
B. Primary Server Instance
C. Secondary Server Instance
D. Backup Share file Server
Correct Answers : B and C
Explanation :
Before you configure log shipping, you must create a share to make the transaction log backups available to the secondary server.
SQL Server Log shipping allows you to automatically send transaction log backups from a primary database on a primary server instance to one or more secondary databases on separate secondary server instances.
The transaction log backups are applied to each of the secondary databases individually. An optional third server instance, known as the monitor server, records the history and status of backup and restore operations and, optionally, raises alerts if these operations fail to occur as scheduled.
The primary server instance runs the backup job to back up the transaction log on the primary database backup job.
The secondary server instance runs its own copy job to copy the primary log-backup file to its own local destination folder.
Option A is incorrect because using the monitor server instance you can monitor information about the status of all the log shipping servers. In the question, we speak about steps such as backup & copy jobs for log shipping to be configured on the server instance.
Option D is incorrect because this is the network share to which you wish to copy the backup files. This is nothing to do with backup & copy jobs.
Reference: https://docs.microsoft.com/en-us/sql/database-engine/log-shipping/about-log-shipping-sql-server
Domain: Plan and implement data platform resources (20—25%)
Question 15: I want to compress my table dbo.myTable. I start with the following code:
- ALTER TABLE dbo.myTable
- REBUILD PARTITION = ALL
- WITH (DATA_COMPRESSION =
Which of the options is NOT a valid ending to this code?
A. PAGE)
B. ROW)
C. NONE)
D. PREFIX)
Correct Answer : D
Explanation :
OPTION A is incorrect because page-level compression compresses data at the leaf level of tables and indexes. The compression is done by storing repeating values and common prefixes only once and then making references to those values from other locations within the table.
OPTION B is incorrect because this is applied to maximize the number of rows stored on a page. It’s highly dependent on the field types. So, varchars, nvarchars, and tiny ‘ints’ won’t be compressed at all and only datetime, datetime2, and datetimeoffset would be compressed in the datatypes. So, you have most of the savings in char and nchar. When page compression is applied to a table, row compression techniques are also applied
OPTION C is incorrect because this is applied when no compression whatsoever is required.
OPTION D is CORRECT as prefix compression is part of Page compression, you don’t activate it separately.
References: https://docs.microsoft.com/en-us/sql/relational-databases/data-compression/data-compression?view=sql-server-ver16, https://docs.microsoft.com/en-us/sql/relational-databases/data-compression/page-compression-implementation?view=sql-server-ver16
Domain: Plan and implement data platform resources (20—25%)
Question 16 : You plan to create a table in an Azure Synapse Analytics dedicated SQL pool. The data in the table is invoice data under the sales schema for the past 3 years. SQL Monitor has raised a “Long running query” which when executed showed details about all invoices generated over years to gather month-wise sales for individual items. Due to this management decided to purge data, once a year for data that is older than three years.
Using which of the options below can you ensure that data can be distributed evenly across partitions such that the operation of purging data is accelerated?
A. Filegroup
B. Partition scheme
C. Partition Function
D. Partition Column
Correct Answer : C
Explanation :
Option A is incorrect because filegroup creation defines files involved when partitions are created.
Option B is incorrect because a partition scheme is a database object that maps the partitions of a partition function to one filegroup or to multiple filegroups. It does not help in splitting large datasets into smaller chunks such that querying these would help retrieve data quickly.
Option C is CORRECT because a partition function is a database object that defines how the rows of a table or index are mapped to a set of partitions based on the values of a certain column, called a partitioning column. Each value in the partitioning column is an input to the partitioning function, which returns a partition value. For example, given a table above that contains sales invoices data, you may want to partition the table into 12 (monthly) partitions based on a DateTime column such as invoice date. The partition function defines the number of partitions and the partition boundaries that the table will have.
Option D is incorrect because the example in the question above demands a method by which the data can be split. A Partition column of a table or index is what a partition function uses to partition the table or index.
Domain: Implement a secure environment (15—20%)
Question 17 : You plan to create a table and you need to establish trust around the integrity of data stored. Ledger provides a chronicle of all alternates made to the database over time. Choose the right option that best defines the ledger table.
A. Implements Row level security
B. Implements Encryption of data.
C. Implements decryption of data
D. Preserves historical data in the history table.
Correct Answer : D
Explanation :
Option A is incorrect as row-level security (RLS) is used to restrict data access for given users. Filters, restrict data access at the row level. You can define filters within roles. You can configure RLS on datasets that are using DirectQuery, such as SQL Server. With RLS the records from the tables are displayed based on who the user is and to which records the user has access.
Option B is incorrect because encryption is the process of perplexing data by the use of a key or password. In this question, we are referring to ledger tables and their functionality. Encryption of data does not provide tamper-evidence capabilities in your database. Using data encryption you cannot cryptographically attest to other parties, such as auditors or other business parties, that your data hasn’t been tampered with.
Option C is incorrect because the decryption of data is using the corresponding decryption key or password used at the point of encryption. The decryption of data is the conversion of encrypted data into its original form. Nowhere it corresponds to the feature of preserving historical data as done by Ledger tables.
Option D is CORRECT as the ledger helps protect data from any attacker or high-privileged user, including database administrators (DBAs), system administrators, and cloud administrators. With a traditional ledger, the feature preserves historical data. If a row is updated in the database, its previous value is maintained and protected in a history table. Ledger provides a chronicle of all changes made to the database over time.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/ledger/ledger-updatable-ledger-tables?view=sql-server-ver16, https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/sql-server-encryption?view=sql-server-ver16
Domain: Plan and implement data platform resources (20—25%)
Question 18 : You have SQL Server on an Azure virtual machine that contains a database named DB1. Consider a table that holds coffee inventory data.
The columns within the table are ID, Name, Price description and Create Date.
We have a non-clustered index on our Name column and the query is Sargable. We also add non-key columns such as Price and Description.
The data in the table is not evenly distributed. We have more rows with ‘Name’ including “Costa Rica”.
Following is the stored procedure which basically filters the different coffee entries from the table.
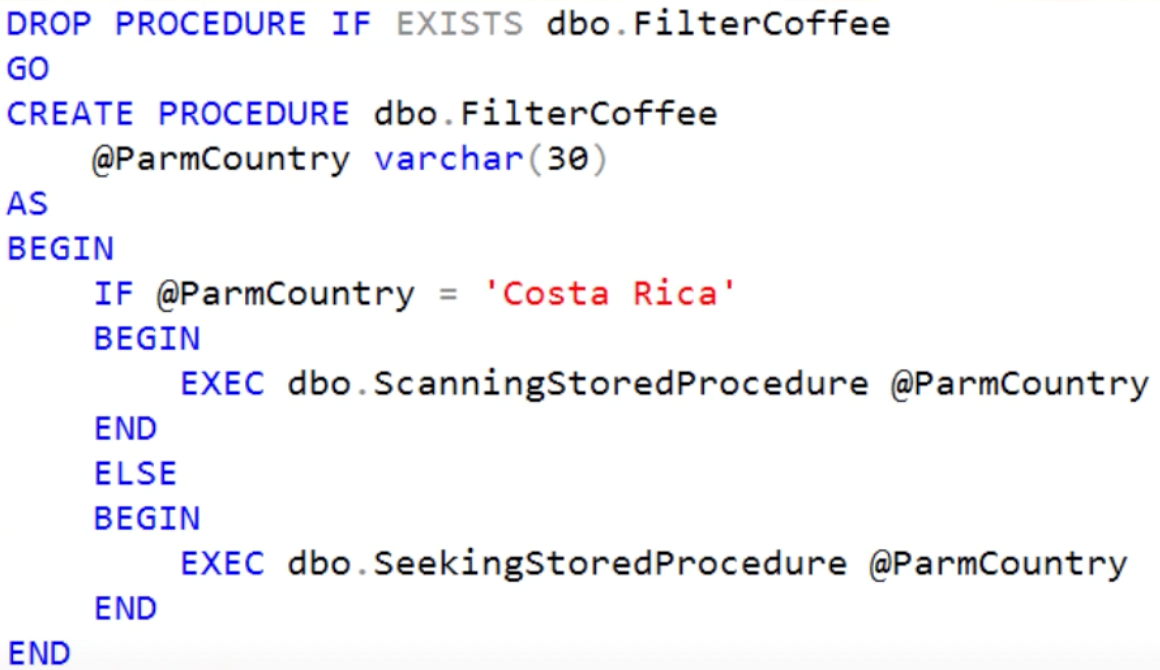
DROP PROCEDURE IF EXISTS dbo.FilterCoffee
GO;
CREATE PROCEDURE dbo.FilterCoffee
@ParamCountry varchar(30)
AS
BEGIN
SELECT Name, Price, Description From dbo.FilterCoffee Where Name lile @ParamCountry + ‘%’
END
GO
Executing the procedure twice with different parameter values ‘Costa Rica’ and then ‘Eithopia’ receives the same query plan which uses the table scan.
What option would you select that provides a solution to poor performance from parameter sniffing?
A. WITH RECOMPILE option
B. IF/ELSE STATEMENT
C. Run DBCC FREEPROCACHE
D. OPTIMIZE FOR
Correct Answers : A, B and D
Explanation :
Option A is CORRECT because when the optimizer creates an execution plan it sniffs the parameter values. This is not an issue; in fact, it is needed to build the best plan. The problem arises when a query uses a previously generated plan optimized for different data distribution. WITH RECOMPILE hint forces SQL to generate a new execution plan every single time a query is run. The best query plan takes into consideration the cardinality estimation based on input parameters with the help of statistics.
Option B is CORRECT because this solution gives you absolute flexibility. We can write an IF/ELSE statement with a condition that it would run different stored procedures based on the parameter value getting passed. If “Costa Rica” is the parameter value that is passed we can execute a different stored procedure that is optimized for the value “Costa Rica” ELSE we can run another stored procedure that is optimized for parameters that are bringing back a few rows such that we receive an execution plan that’s using the index seek.
Option C is incorrect as DBCC FREEPROCCACHE does not clear the execution statistics for natively compiled stored procedures. The procedure cache does not contain information about natively compiled stored procedures. Any execution statistics collected from procedure executions will appear in the execution statistics DMVs.
Option D is CORRECT as you can OPTIMIZE FOR an unknown value which would basically use an average distribution of all the values and SQL Server would write a query plan that is based on that average distribution. When you specify optimization for an unknown value, it Instructs the query optimizer to use statistical data instead of the initial values for all local variables when the query is compiled and optimized, including parameters created with forced parameterization.
Domain: Implement a secure environment (15—20%)
Question 19 : London Heathrow Airport is one of the busiest in Europe by passenger traffic. To keep adverse weather, aircraft delays, traffic-clogged highways, public transport slow-downs, and global pandemics from disrupting its operational readiness, and to identify the untapped capacity that it can use to grow sustainably, Heathrow needs an effectively managed data estate. Which Microsoft Azure service would help derive data-driven insights to optimize its operations, support continued growth, and improve air travel experiences.
A. Data Catalog
B. Microsoft Purview
C. Azure Lighthouse
D. Azure CycleCloud
Correct Answer : B
Explanation :
Option A is incorrect because Azure Data Catalog was good at scanning SQL databases and drawing inferences of what form of data resided in the tables. It never understood anything beyond relational databases. It did not understand any modern data structure. It did not offer anything related to data governance, data classification, and data security.
Option B is CORRECT because of its unified data governance service for managing on-premises and multi-cloud data. It created a unified map of data across your entire data estate. Automated and managed metadata from hybrid sources. Classified data using built-in and custom classifiers and Microsoft Information Protection sensitivity labels. Labeled sensitive data consistently across SQL Server, Azure, Microsoft 365, and Power BI.Easily integrated all data catalogs and systems using Apache Atlas APIs.
Option C is incorrect because Azure Lighthouse enables multi-tenant management with scalability, higher automation, and enhanced governance across resources. Customers maintain control over who has access to their tenants, which resources they can access, and what actions can be taken.
Option D is incorrect because Azure CycleCloud is an enterprise-friendly tool for orchestrating and managing High-Performance Computing (HPC) environments on Azure. With CycleCloud, users can provision infrastructure for HPC systems, deploy familiar HPC schedulers, and automatically scale the infrastructure to run jobs efficiently at any scale. Through CycleCloud, users can create different types of file systems and mount them to the compute cluster nodes to support HPC workloads.
References: https://learn.microsoft.com/en-us/azure/purview/concept-best-practices-accounts, https://learn.microsoft.com/en-us/azure/lighthouse/overview, https://learn.microsoft.com/en-us/azure/cyclecloud/overview?view=cyclecloud-8
Domain: Implement a secure environment (15—20%)
Question 20 : We have an Azure SQL Database server named IBC_010122 that stores PHI data for customers at Change health care. This data is accessed and transmitted across networks between the database Server and various HealthTech, and InsurTech Client applications. To encrypt data that is transmitted across networks which form of data encryption is most suitable?
A. Always Encrypted
B. TLS
C. TDE
D. CLE
Correct Answer : B
Explanation :
Option A is incorrect because Always Encrypted exists to solve more than just the issue of making sure data is encrypted in transit. In fact, that’s not even the primary concern that Always Encrypted solves. The big issue that Always Encrypted solves is that with Transparent Data Encryption (TDE), the keys and certificates which secure the encrypted data are themselves stored in the database. This could be a concern for someone considering putting their SQL Server database in the cloud because the cloud provider then ultimately has the secrets for decrypting the data. With Always Encrypted, the Column Encryption Key (CEK), which is used to encrypt/decrypt column data, is stored in the database in its encrypted form. But here’s the kicker – the key used to encrypt/decrypt the CEK is stored outside the database, leaving the database unable to decrypt the data on its own.
Option B is CORRECT because TLS is a standard cryptographic protocol that ensures privacy and data integrity between clients and services over the Internet.
Option C is incorrect because, it Encrypts & de-encrypts data at the page level at rest.
Option D is incorrect because, it encrypts only the sensitive information in a table. With CLE there are high-performance penalties if search queries cannot be optimized to avoid encrypted data.
Type: Drag n drop: Aligning
Domain: Plan and implement data platform resources (20—25%)
Question 21 : You need to migrate a disk-based table for sales data on a SQL 2014 server to SQL 2016 such that we could have these tables as memory-optimized. A back and restore option was used for this operation. The need for this migration was to improve performance. Determine the Transact-SQL segments you should use such that the performance benefits are concluded and table statistics are updated consequently.
| SQL SEGMENTS | |
| A | Create procedure sp_inventory
WITH NATIVE COMPILATION |
| B | ALTER DATABASE CURRENT SET
COMPATIBILITY_LEVEL = 130 |
| C | EXEC sp_inventory |
| D | UPDATE STATISTICS dbo.sales |
| E | EXEC sp_recompile N’ sp_inventory |
Correct Answers : B, D and E
Explanation :
Compatibility level 130: Queries on a memory-optimized table can now have parallel plans: This is the compatibility level setting of 130. A memory-optimized table has 2 copies, one active memory, and one durable disk. It’s actually the way SQL Server handles the latches and locks. It does not place locks or latches on any version of updated rows of data, which is very different than normal tables.
It’s this mechanism that reduces contention and allows the transactions to process exponentially faster. Instead of locks, In-Memory uses Row Versions, keeping the original row until after the transaction is committed. Much like Read Committed Snapshot Isolation (RCSI), this allows other transactions to read the original row while updating the new row version. The In-Memory structured version is pageless and optimized for speed inside active memory, giving a significant performance impact depending on workloads.
Updating statistics ensures that queries compile with up-to-date statistics. Updating statistics via any process may cause query plans to recompile automatically. Updating statistics can certainly cause recompilation. But based on observations, it won’t necessarily cause every execution plan to recompile. SQL Server was smart enough to check if the data had changed. Updating statistics alone doesn’t always invalidate execution plans.
Causes stored procedures, triggers, and user-defined functions to be recompiled the next time that they are run. It does this by dropping the existing plan from the procedure cache forcing a new plan to be created the next time that the procedure or trigger is run.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-database-transact-sql-compatibility-level?view=sql-server-2017#differences-between-compatibility-level-120-and-level-130, https://docs.microsoft.com/en-us/sql/relational-databases/clr-integration/clr-integration-overview?view=sql-server-ver16
Domain: Plan and implement data platform resources (20—25%)
Question 22 : A company holds a Microsoft cloud subscription. We need to understand how we enable the staff of the company to connect to the cloud services.
We have the Azure virtual network gateway to access the cloud environment.
To ensure a secure connection for all of the users who work at the office, between the data center or office and the Azure virtual network, which of the following VPN option would you choose from below?
A. site to site (S2S) VPN
B. IPSec
C. ExpressRoute
D. point-to-site VPN
Correct Answer : A
Explanation :
Option A is CORRECT because, the site-to-site VPN is used when you want to connect 2 networks and keep the communication up all the time. S2S tends to cost low and all communication occurs over the public internet and is limited by the organization’s internet speed. SSL VPNs give users remote tunneling access to a specific system or application on the network. With SSL VPNs, if a bad actor gains control of the tunnel they have access to only the specific application or operating systems that the SSL is connected to.
Option B is incorrect or not suitable for various reasons, the first being IPsec protocol, while secured with encryption as part of the TCP/IP suite, can give hackers full access to an entire corporate network if access is gained. The main difference between IPsec and SSL VPNs is the endpoints for each protocol. While an IPsec VPN allows users to connect remotely to an entire network and all its applications, SSL VPNs give users remote tunneling access to a specific system or application on the network
Option C is incorrect because, ExpressRoute is a dedicated private connection. All transferred data is not encrypted, and do not go over the public Internet.
Option D is incorrect because, in point-to-site, you have to connect to the network you want to access manually. Usually, if you log off or restart the workstation it loses connection, and you have to reconnect every time. If you are using the VM in Azure as a workstation, then point-to-site may be enough, but if your application needs to get data from the customer database automatically with or without someone logged in to the VM, then its not a better approach. Even though P2S VPN is a useful solution to use instead of S2S VPN when you have only a few clients that need to connect to a VNet it is still not the optimal option because of the above reasons.
Reference: https://docs.microsoft.com/en-us/azure/vpn-gateway/vpn-gateway-howto-site-to-site-classic-porta
Domain: Implement a secure environment (15—20%)
Question 23 : You have Customer PHI data residing at TIBCO which is a legacy service used to integrate applications using a visual, model-driven development environment by CHC. We need to migrate this data to Azure SQL Database such that we can perform certain analyses.
The TIBCO system produces time series analysis-based reports for customers who are segregated on the basis of aliment diagnosed. There are six ailments on which these analyses would broadly be carried out.
Data from the TIBCO system is stored in Azure Event Hub.
For being affirmative on the diagnosis done for the aliment the reports would be sent to four other departments such that pre-operative assessment and examination tests could be carried out.
Each department has an Azure Web App that displays time series-based assessment and contains a WebJob that processes incoming data from Event Hub.
All Web Apps run on App Service Plans with three instances.
Data throughput must be maximized. Latency must be minimized.
You need to implement the Azure Event Hub. The partition Key is ‘department’. What would be the number of partitions required for optimal data distribution?
A. 3
B. 4
C. 6
D. 12
Correct Answer : C
Explanation :
The number of partitions is specified at creation and must be between 2 and 32. The partition count is not changeable, so you should consider the long-term scale when setting the partition count.
Since we have 6 distinct aliments for which we are doing the diagnosis our partition stands on the number of aliments where the distribution of data would incur.
A sequence of events identified by a partition key is a stream. A partition is a multiplexed log store for many such streams.
You can use a partition key to map incoming event data into specific partitions for the purpose of data organization. The partition key is a sender-supplied value passed into an event hub. It is processed through a static hashing function, which creates the partition assignment. If you don’t specify a partition key when publishing an event, a round-robin assignment is used.
The partition key enables keeping related events together in the same partition and in the exact order in which they arrive. The partition key is some string derived from your application context and identifies the interrelationship of the events.
Reference: https://learn.microsoft.com/en-us/azure/event-hubs/event-hubs-features
Summary
Hope you have enjoyed this article and found it very useful for DP-300 exam on Administering Microsoft Azure SQL Solutions Certification preparation. Experts always recommend spending more time on learning before you attempt the actual certification exam. Just like learning by these free questions, you should also try to attempt the DP-300 free practice test which has a set of mock questions to assess your skills.
We at Whizlabs provides you the DP-300 exam preparation guidance with all of the training resources like video courses, practice tests and hands-on-labs, Azure sandboxes for real-time experiments that you need to pass the DP-300 certification exam successfully.
Keep Learning !
- Study Guide DP-600 : Implementing Analytics Solutions Using Microsoft Fabric Certification Exam - June 14, 2024
- Top 15 Azure Data Factory Interview Questions & Answers - June 5, 2024
- Top Data Science Interview Questions and Answers (2024) - May 30, 2024
- What is a Kubernetes Cluster? - May 22, 2024
- What are the Roles and Responsibilities of an AWS Sysops Administrator? - March 28, 2024
- How to Create Azure Network Security Groups? - March 15, 2024
- What is the difference between Cloud Dataproc and Cloud Dataflow? - March 13, 2024
- What are the benefits of having an AWS SysOps Administrator certification? - March 1, 2024