

Google Cloud Certified Professional Machine Learning Engineer Exam requires good knowledge of Google Cloud and a working understanding of proven ML models and techniques. If you are already an experienced Machine Learning Engineer, this exam may look easy to you.
Practicing with real exam questions will make you familiar with the Google ML engineer exam patterns. Whizlabs offers one of the best practice questions for this certification exam (You can also try Whizlabs free test). Below is the sample 25 questions to help you to understand the exam format and type of questions.
Google Cloud Certified Professional Machine Learning Engineer Questions
Here is the list of 25 questions for the Google Cloud Certified Professional Machine Learning Engineer Exam Questions.
Frame ML problems
Q 1. Your team works on a smart city project with wireless sensor networks and a set of gateways for transmitting sensor data. You have to cope with many design choices. You want, for each of the problems under study, to find the simplest solution.
For example, it is necessary to decide on the placement of nodes so that the result is the most economical and inclusive. An algorithm without data tagging must be used.
Which of the following choices do you think is the most suitable?
A. K-means
B. Q-learning
C. K-Nearest Neighbors
D. Support Vector Machine(SVM)
Correct answers: B
Q-learning is an RL Reinforcement Learning algorithm. RL provides a software agent that evaluates possible solutions through a progressive reward in repeated attempts. It does not need to provide labels. But it requires a lot of data and several trials and the possibility to evaluate the validity of each attempt.
The main RL algorithms are deep Q-network (DQN) and deep deterministic policy gradient (DDPG).
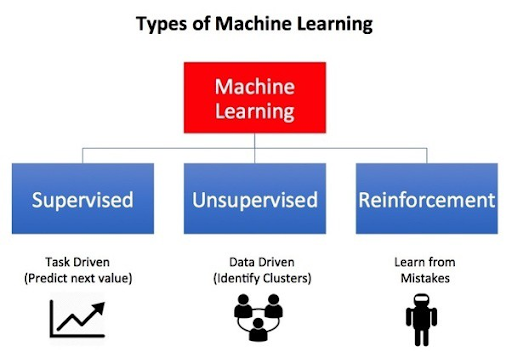
- A is wrong because K-means is an unsupervised learning algorithm used for clustering problems. It is useful when you have to create similar groups of entities. So, even if there is no need to label data, it is not suitable for our scope.
- C is wrong because K-NN is a supervised classification algorithm, therefore, labeled. New classifications are made by finding the closest known examples.
- D is wrong because SVM is a supervised ML algorithm, too. K-NN distances are computed. These distances are not between data points, but with a hyper-plane, that better divides different classifications.
Q 2. Your client has an e-commerce site for commercial spare parts for cars with competitive prices. It started with the small car sector but is continually adding products. Since 80% of them operate in a B2B market, he wants to ensure that his customers are encouraged to use the new products that he gradually offers on the site quickly and profitably.
Which GCP service can be valuable in this regard and in what way?
A. Create a Tensorflow model using Matrix factorization
B. Use Recommendations AI
C. Import the Product Catalog
D. Record / Import User events
Correct answers: B
Recommendations AI is a ready-to-use service for all the requirements shown in the question. You don’t need to create models, tune, train, all that is done by the service with your data. Also, the delivery is automatically done, with high-quality recommendations via web, mobile, email. So, it can be used directly on websites during user sessions.
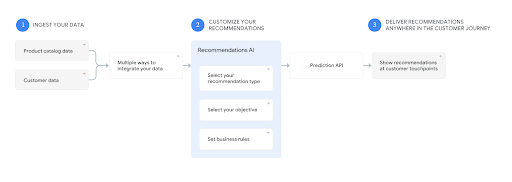
A could be OK, but it needs a lot of work.
C and D deal only with data management, not creating recommendations.
For any further detail:
Q 3. You are working on an NLP model. So, you are dealing with words and sentences, not numbers. Your problem is to categorize these words and make sense of them. Your manager told you that you have to use embeddings.
Which of the following techniques are not related to embeddings?
A. Count Vector
B. TF-IDF Vector
C. Co-Occurrence Matrix
D. CoVariance Matrix
Correct Answer: D
Covariance matrices are square matrices with the covariance between each pair of elements.
It measures how much the change of one with respect to another is related.
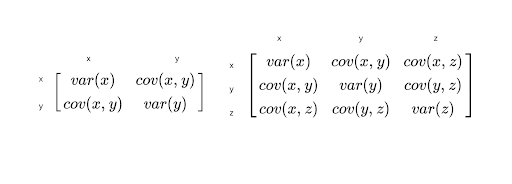
All the others are embeddings:
A Count Vector gives a matrix with the count of every single word in every example. 0 if no occurrence. It is okay for small vocabularies.
TF-IDF vectorization counts words in the entire experiment, not a single example or sentence.
Co-Occurrence Matrix puts together words that occur together. So, it is more useful for text understanding.
Q 4. You are a junior Data Scientist and are working on a deep neural network model with Tensorflow to optimize the level of customer satisfaction for after-sales services with the goal of creating greater client loyalty.
You are struggling with your model (learning rates, hidden layers and nodes selection) for optimizing processing and to let it converge in the fastest way.
Which is your problem, in ML language?
A. Cross-Validation
B. Regularization
C. Hyperparameter tuning
D. drift detection management
Correct Answer: C
ML training Manages three main data categories:
- Training data also called examples or records. It is the main input for model configuration and, in supervised learning, presents labels, that is the correct answers based on past experience. Input data is used to build the model but will not be part of the model.
- Parameters are Instead the variables to be found to solve the riddle. They are part of the final model and they make the difference among similar models of the same type.
- Hyperparameters are configuration variables that influence the training process itself: Learning rate, hidden layers number, number of epochs, regularization, batch size are all examples of hyperparameters.
Hyperparameters tuning is made during the training job and used to be a manual and tedious process, made by running multiple trials with different values.
The time required to train and test a model can depend upon the choice of its hyperparameters.
With Vertex AI you just need to prepare a simple YAML configuration without coding.
A is wrong because Cross Validation is related to the input data organization for training, test, and validation
B is wrong because Regularization is related to feature management and overfitting
D is wrong because drift management is when data distribution changes and you have to adjust the model
Architect ML solutions
Q 5. You work in a major banking institution. The Management has decided to rapidly launch a bank loan service, as the Government has created a series of “first home” facilities for the younger population.
The goal is to carry out the automatic management of the required documents (certificates, origin documents, legal information) so that the practice can be built and verified automatically using the data and documents provided by customers and can be managed in a short time and with the minimum contribution of the scarce specialized personnel.
Which of these GCP services can you use?
A. Dialogflow
B. Document AI
C. Cloud Natural Language API
D. AutoML
Correct answers: B
Document AI is the perfect solution because it is a complete service for the automatic understanding of documents and their management.
It integrates computer natural language processing, OCR, and vision and can create pre-trained templates aimed at intelligent document administration.
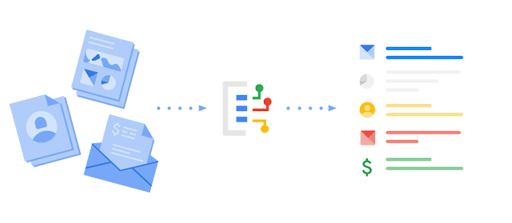
- A is wrong because Dialogflow is for speech Dialogs, not written documents.
- C is wrong because NLP is integrated into Document AI.
- D is wrong because functions like AutoML are integrated into Document AI, too.
Q 6. You work for a large retail company. You are preparing a marketing model. The model will have to make predictions based on the historical and analytical data of the e-commerce site (analytics-360). In particular, customer loyalty and remarketing possibilities should be studied. You work on historical tabular data. You want to quickly create an optimal model, both from the point of view of the algorithm used and the tuning and life cycle of the model.
What are the two best services you can use?
A. AutoML Tables
B. BigQuery ML
C. Vertex AI
D. GKE
Correct answers: A and C
AutoML Tables can select the best model for your needs without having to experiment.
The architectures currently used (they are added at the same time) are:
- Linear
- Feedforward deep neural network
- Gradient Boosted Decision Tree
- AdaNet
- Ensembles of various model architectures
In addition, AutoML Tables automatically performs feature engineering tasks, too, such as: - Normalization
- Encoding and embeddings for categorical features.
- Timestamp columns management (important in our case)
So, it has special features for time columns: for example, it can correctly split the input data into training, validation and testing.
Vertex AI is a new API that combines AutoML and AI Platform. You can use both AutoML training and custom training in the same environment.

- B is wrong because AutoML Tables has additional automated feature engineering and is integrated into Vertex AI.
- D is wrong because GKE doesn’t supply all the ML features of Vertex AI. It is an advanced K8s managed environment.
Q 7. Your company operates an innovative auction site for furniture from all times. You have to create a series of ML models that allow you, starting from the photos, to establish the period, style and type of the piece of furniture depicted.
Furthermore, the model must be able to determine whether the furniture is interesting and require it to be subject to a more detailed estimate. You want Google Cloud to help you reach this ambitious goal faster.
Which of the following services do you think is the most suitable?
A. AutoML Vision Edge
B. Vision AI
C. Video AI
D. AutoML Vision
Correct Answer: D
Vision AI uses pre-trained models trained by Google. This is powerful, but not enough.
But AutoML Vision lets you train models to classify your images with your own characteristics and labels. So, you can tailor your work as you want.
A is wrong because AutoML Vision Edge is for local devices.
C is wrong because Video AI manages videos, not pictures. It can extract metadata from any streaming video, get insights in a far shorter time, and let trigger events.

Q 8. You are using an AI Platform, and you are working with a series of demanding training jobs. So, you want to use TPUs instead of CPUs. You are not using Docker images or custom containers.
What is the simplest configuration to indicate if you do not have particular needs to customize in the YAML configuration file?
A. Use scale-tier to BASIC_TPU
B. Set Master-machine-type
C. Set Worker-machine-type
D. Set parameterServerType
Correct Answer: A
AI Platform lets you perform distributed training and serving with accelerators (TPUs and GPUs).
You usually must specify the number and types of machines you need for master and worker VMs. But you can also use scale tiers that are predefined cluster specifications.
In our case,
scale-tier=BASIC_TPU
covers all the given requirements.
B, C and D are wrong because it is not the easiest way. Moreover, workerType, parameterServerType, evaluatorType, workerCount, parameterServerCount, and evaluatorCount for jobs use custom containers and for TensorFlow jobs.
purpose.

Q 9. You work for an industrial company that wants to improve its quality system. It has developed its own deep neural network model with Tensorflow to identify the semi-finished products to be discarded with images taken from the production lines in the various production phases.
You need to monitor the performance of your models and let them go faster.
Which is the best solution that you can adopt?
A. TFProfiler
B. TF function
C. TF Trace
D. TF Debugger
E. TF Checkpoint
Correct Answer: A
TensorFlow Profiler is a tool for checking the performance of your TensorFlow models and helping you to obtain an optimized version.
In TensorFlow 2, the default is eager execution. So, one-off operations are faster, but recurring ones may be slower. So, you need to optimize the model.
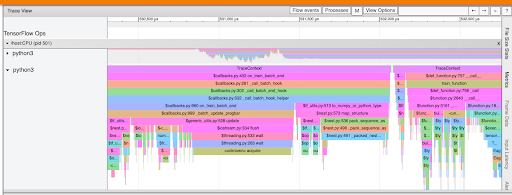
- B is wrong because the TF function is a transformation tool used to make graphs out of your programs. It helps to create performant and portable models but is not a tool for optimization.
- C is wrong because TF tracing lets you record TensorFlow Python operations in a graph.
- D is wrong because TF debugging is for Debugger V2 and creates a log of debug information.
- E is wrong because Checkpoints catch the value of all parameters in a serialized SavedModel format.
Q 10. Your team needs to create a model for managing security in restricted areas of a campus.
Everything that happens in these areas is filmed and, instead of having a physical surveillance service, the videos must be managed by a model capable of intercepting unauthorized people and vehicles, especially at particular times.
What are the GCP services that allow you to achieve all this with minimal effort?
A. AI Infrastructure
B. Cloud Video Intelligence AI
C. AutoML Video Intelligence Classification
D. Vision AI
Correct Answer: C
AutoML Video Intelligence is a service that allows you to customize the pre-trained Video intelligence GCP system according to your specific needs.
In particular, AutoML Video Intelligence Object Tracking allows you to identify and locate particular entities of interest to you with your specific tags.
- A is wrong because AI Infrastructure allows you to manage hardware configurations for ML systems and in particular the processors used to accelerate machine learning workloads.
- B is wrong because Cloud Video Intelligence AI is a pre-configured and ready-to-use service, therefore not configurable for specific needs
- D is wrong because Vision A is for images and not video.
Q 11. With your team you have to decide the strategy for implementing an online forecasting model in production.
This template needs to work with both a web interface as well as DialogFlow and Google Assistant and a lot of requests are expected.
You are concerned that the final system is not efficient and scalable enough, and you are looking for the simplest and most managed GCP solution.
Which of these can be the solution?
A. AI Platform Prediction
B. GKE e TensorFlow
C. VMs and Autoscaling Groups with Application LB
D. Kubeflow
Correct Answer: A
The AI Platform Prediction service is fully managed and automatically scales machine learning models in the cloud
The service supports both online prediction and batch prediction.
- B and C are wrong because they are not managed services
- D is wrong because Kubeflow is not a managed service, it is used into AI Platforma and let you to deploy ML systems to various environments
Design data preparation and processing systems
Q 12. You work for a digital publishing website with an excellent technical and cultural level, where you have both famous authors and unknown experts who express ideas and insights.
You, therefore, have an extremely demanding audience with strong interests that can be of various types.
Users have a small set of articles that they can read for free every month. Then they need to sign up for a paid subscription.
You have been asked to prepare an ML training model that processes user readings and article preferences. You need to predict trends and topics that users will prefer.
But when you train your DNN with Tensorflow, your input data does not fit into RAM memory.
What can you do in the simplest way?
A. Use tf.data.Dataset
B. Use a queue with tf.train.shuffle_batch
C. Use pandas.DataFrame
D. Use a NumPy array
Correct Answer: A
The tf.data.Dataset allows you to manage a set of complex elements made up of several inner components.
It is designed to create efficient input pipelines and to iterate over the data for their processing.
These iterations happen in streaming. So, they work even if the input matrix is very large and doesn’t fit in memory.
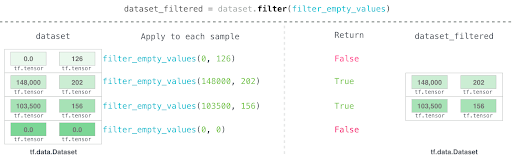
- B is wrong because it is far more complex, even if it is feasible.
- C and D are wrong because they work in real memory, so they don’t solve the problem at all.
Q 13. You are working on a deep neural network model with Tensorflow. Your model is complex, and you work with very large datasets full of numbers.
You want to increase performances. But you cannot use further resources.
You are afraid that you are not going to deliver your project in time.
Your mentor said to you that normalization could be a solution.
Which of the following choices do you think is not for data normalization?
A. Scaling to a range
B. Feature Clipping
C. Z-test
D. log scaling
E. Z-score
Correct Answer: C
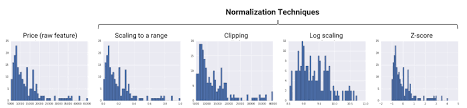
z-test is not correct because it is a statistic that is used to prove if a sample mean belongs to a specific population. For example, it is used in medical trials to prove whether a new drug is effective or not.
A is OK because Scaling to a range converts numbers into a standard range ( 0 to 1 or -1 to 1).
B is OK because Feature Clipping caps all numbers outside a certain range.
D is OK because Log Scaling uses the logarithms instead of your values to change the shape. This is possible because the log function preserves monotonicity.
E is OK because Z-score is a variation of scaling: the resulting number is divided by the standard deviations. It is aimed at obtaining distributions with mean = 0 and std = 1.
Develop ML models
Q 14. You need to develop and train a model capable of analyzing snapshots taken from a moving vehicle and detecting if obstacles arise. Your work environment is an AI Platform (currently Vertex AI).
Which technique or algorithm do you think is best to use?
A. TabNet algorithm with TensorFlow
B. A linear learner with Tensorflow Estimator API
C. XGBoost with BigQueryML
D. TensorFlow Object Detection API
Correct Answer: D
TensorFlow Object Detection API is designed to identify and localize multiple objects within an image. So it is the best solution.

- A is wrong because TabNet is used with tabular data, not images. It is a neural network that chooses the best features at each decision step in such a way that the model is optimized simpler.
- B is wrong because a linear learner is not suitable for images too. It can be applied to regression and classification predictions.
- C is wrong because BigQueryML is designed for structured data, not images.
Q 15. You are starting to operate as a Data Scientist and are working on a deep neural network model with Tensorflow to optimize customer satisfaction for after-sales services to create greater client loyalty.
You are doing Feature Engineering, and your focus is to minimize bias and increase accuracy. Your coordinator has told you that by doing so you risk having problems. He explained to you that, in addition to the bias, you must consider another factor to be optimized. Which one?
A. Blending
B. Learning Rate
C. Feature Cross
D. Bagging
E. Variance
Correct Answer: E
The variance indicates how much function f (X) can change with a different training dataset. Obviously, different estimates will correspond to different training datasets, but a good model should reduce this gap to a minimum.
The bias-variance dilemma is an attempt to minimize both bias and variance.
The bias error is the non-estimable part of the learning algorithm. The higher it is, the more underfitting there is.
Variance is the sensitivity to differences in the training set. The higher it is, the more overfitting there is.
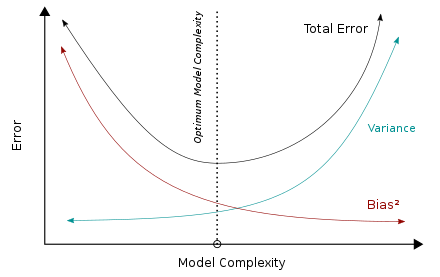
- A is wrong because Blending indicates an ensemble of ML models.
- B is wrong because Learning Rate is a hyperparameter in neural networks.
- C is wrong because Feature Cross is the method for obtaining new features by multiplying other ones.
- D is wrong because Bagging is an ensemble method like Blending.
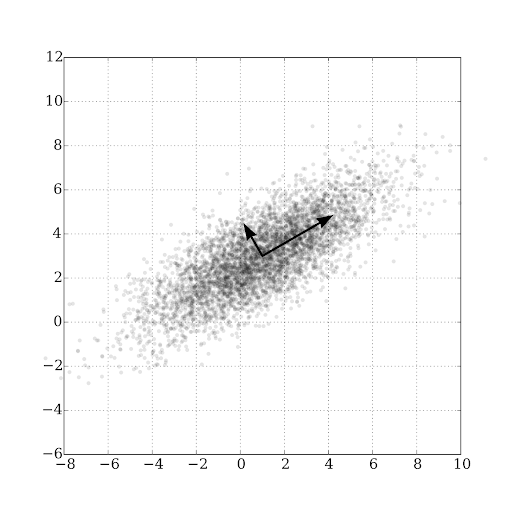
Q 16. You have a Linear Regression model for the optimal management of supplies to a sales network based on a large number of different driving factors. You want to simplify the model to make it more efficient and faster. Your first goal is to synthesize the features without losing the information content that comes from them.
Which of these is the best technique?
A. Feature Crosses
B. Principal component analysis (PCA)
C. Embeddings
D. Functional Data Analysis
Correct Answer: B
Principal component analysis is a technique to reduce the number of features by creating new variables obtained from linear combinations or mixes of the original variables, which can then replace them but retain most of the information useful for the model. In addition, the new features are all independent of each other.
The new variables are called principal components.
A linear model is assumed as a basis. Therefore, the variables are independent of each other.
- A is incorrect because Feature Crosses are for the same objective, but they add non-linearity.
- C is incorrect because Embeddings, which transform large sparse vectors into smaller vectors are used for categorical data.
- D is incorrect because Functional Data Analysis has the goal to cope with complexity, but it is used when it is possible to substitute features with functions- not our case.
Q 17. You work for a digital publishing website with an excellent technical and cultural level, where you have both famous authors and unknown experts who express ideas and insights. You, therefore, have an extremely demanding audience with strong interests of various types. Users have a small set of articles that they can read for free every month; they need to sign up for a paid subscription.
You aim to provide your audience with pointers to articles that they will indeed find of interest to themselves.
Which of these models can be useful to you?
A. Hierarchical Clustering
B. Autoencoder and self-encoder
C. Convolutional Neural Network
D. Collaborative filtering using Matrix Factorization
Correct Answer: D
Collaborative filtering works on the idea that a user may like the same things of the people with similar profiles and preferences.
So, exploiting the choices of other users, the recommendation system makes a guess and can advise people on things not yet been rated by them.
- A is wrong because Hierarchical Clustering creates clusters using a hierarchical tree. It may be effective, but it is heavy with lots of data, like in our example.
- B is wrong because Autoencoder and self-encoder are useful when you need to reduce the number of variables under consideration for the model, therefore for dimensionality reduction.
- C is wrong because Convolutional Neural Network is used for image classification.
Q 18. You work for an important Banking group.
The purpose of your current project is the automatic and smart acquisition of data from documents and modules of different types.
You work on big datasets with a lot of private information that cannot be distributed and disclosed.
You are asked to replace sensitive data with specific surrogate characters.
Which of the following techniques do you think is best to use?
A. Format-preserving encryption
B. K-anonymity
C. Replacement
D. Masking
Correct Answer: D
Masking replaces sensitive values with a given surrogate character, like hash (#) or asterisk (*).
Format-preserving encryption (FPE) encrypts in the same format as the plaintext data.
For example, a 16-digit credit card number becomes another 16-digit number.
k-anonymity is a way to anonymize data in such a way that it is impossible to identify person-specific information. Still, you maintain all the information contained in the record.
Replacement just substitutes a sensitive element with a specified value.

Q 19. Your company traditionally deals with statistical analysis on data. The services have been integrated for some years with ML models for forecasting, but analyzes and simulations of all kinds are carried out.
So you are using 2 types of tools but you have been told that it is possible to have more levels of integration between traditional statistical methodologies and those more related to AI / ML processes.
Which tool is the best one for your needs?
A. TensorFlow Hub
B. TensorFlow Probability
C. TensorFlow Enterprise
D. TensorFlow Statistics
Correct answers: B
TensorFlow Probability is a Python library for statistical analysis and probability, which can be processed on TPU and GPU, too.
TensorFlow Probability main features are:
- Probability distributions and differentiable and injective (one to one) functions.
- Tools for deep probabilistic models building
- Inference and Simulation methods support Markov chain, Monte Carlo.
- Optimizers such as Nelder-Mead, BFGS, and SGLD.
All the other answers are wrong because they don’t deal with traditional statistical methodologies.
Automate & orchestrate ML pipelines
Q 20. Your customer has an online dating platform that, among other things, analyzes the degree of affinity between the various people. Obviously, it already uses ML models and uses, in particular, XGBoost, the gradient boosting decision tree algorithm, and is obtaining excellent results.
All its development processes follow CI / CD specifications and use Docker containers. The requirement is to classify users in various ways and update models frequently, based on new parameters entered into the platform by the users themselves.
So, the problem you are called to solve is how to optimize frequently re-trained operations with an optimized workflow system. Which solution among these proposals can best solve your needs?
A. Deploy the model on BigQuery ML and setup a job
B. Use Kubeflow Pipelines to design and execute your workflow
C. Use AI Platform
D. Orchestrate activities with Google Cloud Workflows
E. Develop procedures with Pub/Sub and Cloud Run
F. Schedule processes with Cloud Composer
Correct Answer: B
Kubeflow Pipelines is the ideal solution because it is a platform designed specifically for creating and deploying ML workflows based on Docker containers. So, it is the only answer that meets all requirements.
The main functions of Kubeflow Pipelines are:
- Using packaged templates in Docker images in a K8s environment
- Manage your various tests/experiments
- Simplifying the orchestration of ML pipelines
- Reuse components and pipelines
It is within the Kubeflow ecosystem, which is the machine learning toolkit for Kubernetes.
The other answers may be partially correct but do not resolve all items or need to add more coding.
Q 21. You are working with Vertex AI, the managed ML Platform in GCP.
You are dealing with custom training and you are looking and studying the job progresses during the training service lifecycle.
Which of the following states are not correct?
A. JOB_STATE_ACTIVE
B. JOB_STATE_RUNNING
C. JOB_STATE_QUEUED
D. JOB_STATE_ENDED
Correct answer: A
This is a brief description of the lifecycle of a custom training service.
Queueing a new job
When you create a CustomJob or HyperparameterTuningJob, the job is in the JOB_STATE_QUEUED.
When a training job starts, Vertex AI schedules as many workers according to configuration, in parallel.
So Vertex AI starts running code as soon as a worker becomes available.
When all the workers are available, the job state will be: JOB_STATE_RUNNING.
A training job ends successfully when its primary replica exits with exit code 0.
Therefore all the other workers will be stopped. The state will be: JOB_STATE_ENDED.
So A is wrong simply because this state doesn’t exist. All the other answers are correct.
Each replica in the training cluster is given a single role or task in distributed training. For example:
Primary replica: Only one replica, whose main task is to manage the workers.
Worker(s): Replicas that do part of the work.
Parameter server(s): Replicas that store model parameters (optional).
Evaluator(s): Replicas that evaluate your model (optional).
Q 22. Your team works for an international company with Google Cloud, and you develop, train and deploy several ML models with Tensorflow. You use many tools and techniques and you want to make your work leaner, faster, and more efficient.
You would like engineer-to-engineer assistance from both Google Cloud and Google’s TensorFlow teams.
How is it possible? Which service?
A. AI Platform
B. Kubeflow
C. Tensorflow Enterprise
D. TFX
Correct Answer: C
The TensorFlow Enterprise is a distribution of the open-source platform for ML, linked to specific versions of TensorFlow, tailored for enterprise customers.
It is free but only for big enterprises with a lot of services in GCP. it is prepackaged and optimized for usage with containers and VMs.
It works in Google Cloud, from VM images to managed services like GKE and Vertex AI.
The TensorFlow Enterprise library is integrated in the following products:
- Deep Learning VM Images
- Deep Learning Containers
- Notebooks
- AI Platform/Vertex AITraining
It is ready for automatic provisioning and scaling with any kind of processor.
It has a premium level of support from Google. - A is wrong because AI Platform is a managed service without the kind of support required
- B and D are wrong because they are open source libraries with standard support from the community
Monitor, optimize, and maintain ML solutions
Q 23. You work for an important organization and your manager tasked you with a new classification model with lots of data drawn from the company Data Lake.
The big problem is that you don’t have the labels for all the data, but for only a subset of it and you have very little time to complete the task.
Which of the following services could help you?
A. Vertex Data Labeling
B. Mechanical Turk
C. GitLab ML
D. Tag Manager
Correct Answer: A
In supervised learning, the correctness of label data, together with the quality of all your training data is utterly important for the resulting model and the quality of the future predictions.
If you cannot have your data correctly labeled you may request to have professional people that will complete your training data.
GCP has a service for this: Vertex AI data labeling. Human labelers will prepare correct labels following your directions.
You have to set up a data labeling job with:
- The dataset
- A list, vocabulary of the possible labels
- An instructions document for the professional people
- B is wrong because Mechanical Turk is an Amazon service
- C is wrong because GitLab is a DevOps lifecycle tool
- D is wrong because Tag Manager is in the Google Analytics ecosystem
Q 24. Your team is working with a great number of ML projects, especially with Tensorflow.
You recently prepared a DNN model for image recognition that works well and is about to be rolled out in production.
Your manager asked you to demonstrate the inner workings of the model.
It is a big problem for you because you know that it is working well but you don’t have the explainability of the model.
Which of these techniques could help you?
A. Integrated Gradient
B. LIT
C. WIT
D. PCA
Correct Answer: A
Integrated Gradient is an explainability technique for deep neural networks which gives info about what contributes to the model’s prediction.
Integrated Gradient works highlight the feature importance. It computes the gradient of the model’s prediction output regarding its input features without modification to the original model.
In the picture, you can see that it tunes the inputs and computes attributions so that it can compute the feature importances for the input image.
You can use tf.GradientTape to compute the gradients,

- B is wrong because LIT is only for NLP models
- C is wrong because What-If Tool is only for classification and regression models with structured data.
- D is wrong because Principal component analysis (PCA) transforms and reduces the number of features by creating new variables, from linear combinations of the original variables.
The new features will be all independent of each other.
Q 25. You work as a Data Scientist in a Startup and you work with several project with Python and Tensorflow;
You need to increase the performance of the training sessions and you already use caching and prefetching.
So now you want to use GPUs, but in a single machine, for cost reduction and experimentations.
Which of the following is the correct strategy?
A. tf.distribute.MirroredStrategy
B. tf.distribute.TPUStrategy
C. tf.distribute.MultiWorkerMirroredStrategy
D. tf.distribute.OneDeviceStrategy
Correct Answer: A
tf.distribute.Strategy is an API explicitly for training distribution among different processors and machines.
tf.distribute.MirroredStrategy lets you use multiple GPUs in a single VM, with a replica for each CPU.
- B is wrong because tf.distribute.TPUStrategy let you use TPUs, not GPUs
- C is wrong because tf.distribute.MultiWorkerMirroredStrategy is for multiple machines
- D is wrong because tf.distribute.OneDeviceStrategy, like the default strategy, is for a single device, so a single virtual CPU.
Conclusion
The above questions give you a brief idea of the various domains, the exam pattern, and the question format of the Google ML engineer exam. When are you planning to take the certification? If you need to practice more, check our practice exam. Do share your feedback to help other learners.
Reference Links:
- https://cloud.google.com/document-ai
- https://cloud.google.com/automl
- https://www.tensorflow.org/probability
- https://cloud.google.com/certification/machine-learning-engineer
- 25 Free Questions – Certificate of Cloud Security Knowledge V.4 - December 13, 2021
- 25 Free Questions on PL-900 Exam Certification - December 3, 2021
- 50 Free Terraform Certification Exam Questions - December 2, 2021
- 25 Free Questions – GCP Certified Professional Cloud Network Engineer - December 2, 2021
- 25 Free Questions – Microsoft Power BI PL-300 (DA-100) Certification - December 2, 2021
- 25 Free Questions – Google Cloud Developer Certification Exam - November 30, 2021
- 25 Free Questions – Google Cloud Certified Professional Security Engineer - November 30, 2021
- 25 Free Questions – Google Cloud Certified Professional Machine Learning Engineer - November 30, 2021

