

BigData and Hadoop are two widely recognized terms in the current landscape, and they are closely interconnected. The processing of Big Data often relies on the utilization of Hadoop.
This article aims to provide a concise overview of the distinctions between BigData and Hadoop by covering the key terms, features, and advantages of employing it.
Let’s dive in!
What is BigData?
Bigdata refers to the massive amount of data, information, or related statistics processed by large organizations and ventures.
Big Data includes 7 key “V” factors: Velocity, Variety, Volume, Value, Veracity, Visualization, and Variability. Due to the unique challenges posed by managing such data, the demand for individuals with specialized skills in this field is on the rise. Many people are aspiring to complete certification courses in Big Data to meet this growing demand.
Organizations develop various software applications and process tons of data daily. Thus it makes it difficult to process those big data manually. Big data helps to discover the pattern and make informed decisions related to interaction technology and human behavior.
Enrolling in a Big Data and Hadoop course is an excellent way to acquire the skills and knowledge needed to work with large datasets and master the Hadoop framework for efficient data processing.
How does Big Data work?
Big data analytics involves the collection, processing, cleaning, and analysis of large datasets to help organizations make practical use of their big data.
Collecting Data
Every organization has its way of gathering data. With today’s technology, data can be sourced from various places, including cloud storage, mobile apps, and in-store IoT sensors. Some data is stored in data warehouses for easy access, while more complex or diverse data goes into a data lake with assigned metadata.
Processing Data
Once collected, data needs to be organized for accurate analytical results, especially when dealing with large and unstructured datasets. The challenge grows as available data expands exponentially. Batch processing examines large data blocks over time, suitable for scenarios with a longer turnaround between data collection and analysis. On the other hand, stream processing looks at smaller data batches, reducing the delay for quicker decision-making, albeit at a potentially higher cost.
Cleaning Data
Regardless of size, data needs scrubbing for better quality and stronger results. Correct formatting and the elimination of duplicative or irrelevant data are essential. Dirty data can mislead, creating flawed insights.
Analyzing Data
Turning big data into usable insights is a gradual process. Once prepared, advanced analytics methods come into play:
- Data mining identifies patterns and relationships by sifting through large datasets, pinpointing anomalies, and forming data clusters.
- Predictive analytics uses historical data to predict future trends, and recognize upcoming risks and opportunities.
- Deep learning, mimicking human learning patterns, employs artificial intelligence and machine learning to uncover patterns in complex and abstract data through layered algorithms.
Also Read : How to Start Learning Hadoop for Beginners?
What is Hadoop?
Hadoop is open-source software and comprises of cluster of machines to handle the massive amount of data. It also comes up with distributed storage and distributed processing to handle huge amounts of data.
This can be possible with the usage of the MapReduce programming model.
Hadoop can be easily implemented in the Java tool and it can do data mining in any data form such as structured, unstructured, or semi-structured. Moreover, it is highly scalable.
Hadoop architecture consists of three major components such as:
- HDFS: It refers to a reliable storage system with major data stored in it.
- MapReduce: This layer consists of a distributed processor.
- Yarn: This layer is composed of the resource manager
One of the driving forces behind the significant growth of Hadoop technology is that it has distinct features. Unlike other frameworks, Hadoop can partition consumer jobs into various separate subtasks. It can permit code translation into information and this significantly reduces the network traffic.
How does Hadoop work?
Hadoop simplifies the utilization of storage and processing capacity across cluster servers, enabling the execution of distributed processes on massive datasets. It serves as the foundational framework upon which other services and applications can be constructed.
For applications collecting data in diverse formats, integration with the Hadoop cluster involves utilizing an API operation to connect to the NameNode. The NameNode manages the file directory structure and the distribution of “chunks” for each file, which are replicated across DataNodes.
Running a data query job involves providing a MapReduce job composed of numerous map and reduce tasks that operate on the data stored in the Hadoop Distributed File System (HDFS) across the DataNodes. Map tasks execute on each node, processing input files, while reducers aggregate and organize the final output.
Exploring a Big Data and Hadoop tutorial can be a helpful starting point for individuals looking to grasp the fundamentals of managing and analyzing large datasets using the Hadoop ecosystem.
Big Data and Hadoop Differences
Big Data and Hadoop are often used together, but they refer to distinct concepts in the field of data processing. Here is the tabulated BigData and Hadoop differences:
| Aspect | Big Data | Apache Hadoop |
| Definition | Big Data is a group of technologies. It is a collection of huge data that continuously multiplies. | Apache Hadoop is an open-source Java-based framework that incorporates some of the principles of big data. |
| Complexity | It is a collection of assets that are quite complex, complicated, and ambiguous. | It achieves a set of goals and objectives for dealing with the collection of assets. |
| Problem | It represents a complicated problem involving a huge amount of raw data. | It serves as a solution for processing large volumes of data. |
| Accessibility | Big Data is harder to access. | Apache Hadoop allows data to be accessed and processed faster. |
| Data Variety | It is challenging to store a vast amount of data as it includes various forms of data, such as structured, unstructured, and semi-structured. | Apache Hadoop implements the Hadoop Distributed File System (HDFS), enabling the storage of different varieties of data. |
| Data Size | Big Data defines the size of the data set. | Apache Hadoop is where the data set is stored and processed. |
| Applications | Big data has a wide range of applications in fields such as Telecommunication, the banking sector, Healthcare, etc. | Hadoop is used for cluster resource management, parallel processing, and data storage. |
BigData and Hadoop: Advantages
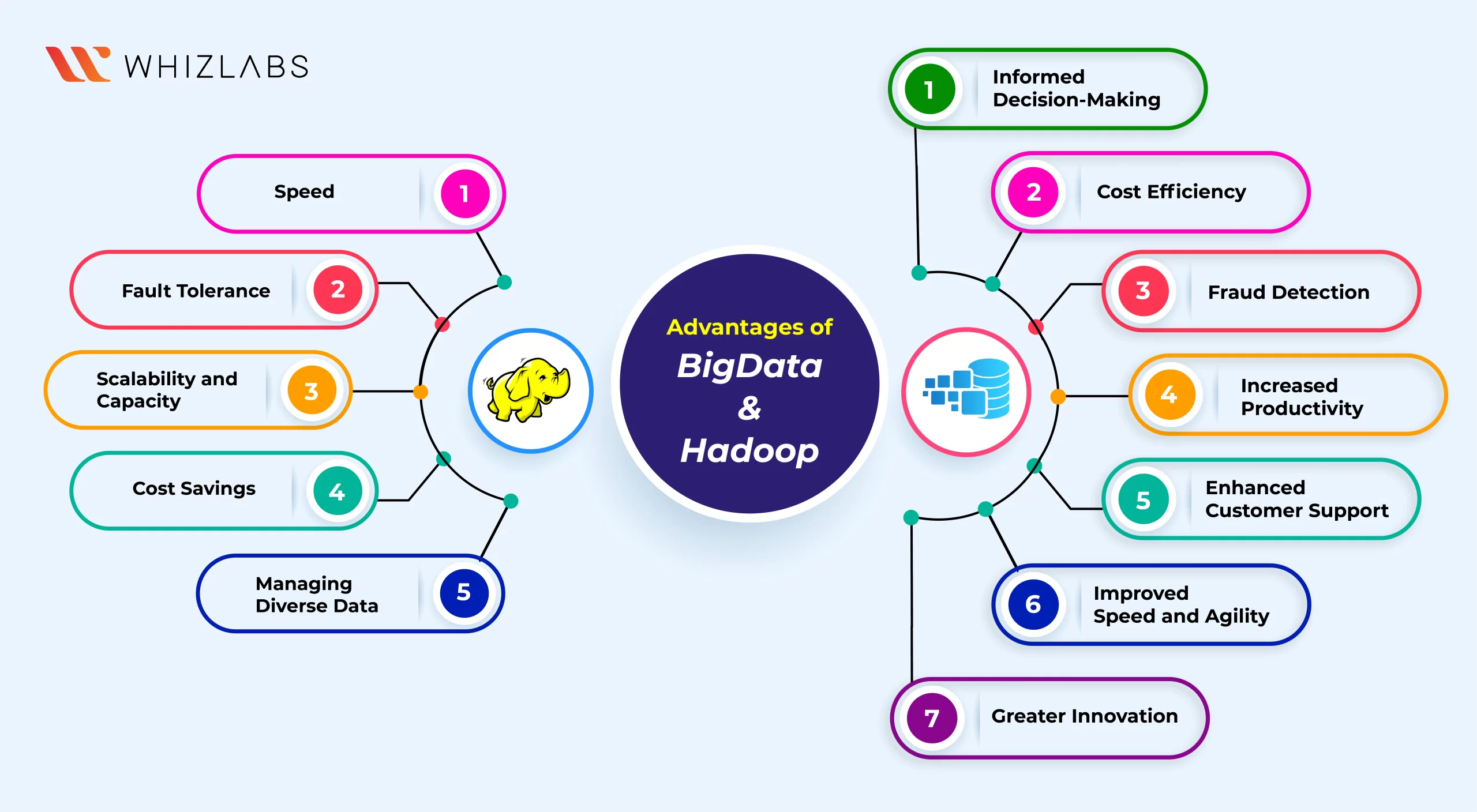
Big Data: Advantages
Informed Decision-Making
Big data enables businesses to make accurate predictions about customer preferences and behaviors, enhancing decision-making in various industries.
Cost Efficiency
Surveys show that 66.7% of businesses experience cost reduction through big data analytics, contributing to improved operational efficiency.
Fraud Detection
Big data, especially in finance, employs AI and machine learning to detect anomalies in transaction patterns, preempting potential fraud.
Increased Productivity
Utilizing big data analytics tools like Spark and Hadoop, businesses report a 59.9% increase in productivity, leading to higher sales and improved customer retention.
Enhanced Customer Support
Big data leverages information from diverse sources, including social media and CRM systems, allowing businesses to offer personalized products and services for increased customer satisfaction and loyalty.
Improved Speed and Agility
Big data analytics provides businesses with insights ahead of competitors, helping them adapt quickly to market changes, assess risks, and strengthen strategies.
Greater Innovation
Executives recognize big data as a catalyst for innovation, with 11.6% investing primarily to gain unique insights and disrupt markets with innovative products and services.
Hadoop: Pros
Speed
Hadoop facilitates parallel processing across a dataset, distributing tasks to be executed concurrently across multiple servers. This framework significantly enhances processing speed compared to previous data analysis methods, whether conducted on local servers or in cloud environments.
Fault Tolerance
With data replication across various nodes in the cluster, Hadoop ensures high fault tolerance. In the event of a node failure or data corruption, the replicated data can seamlessly take over, maintaining accessibility and security.
Scalability and Capacity
The Hadoop Distributed FileSystem (HDFS) enables the partitioning and storage of data across commodity server clusters with uncomplicated hardware setups. Particularly well-suited for cloud installations, Hadoop allows for straightforward and cost-effective expansion to accommodate the exponential growth of data into the petabyte range.
Cost Savings
Being an open-source framework, Hadoop allows anyone with programming skills and sufficient storage space to establish a Hadoop system without the need for licensing. The use of commodity servers for local setups keeps the system economically viable, and the availability of affordable cloud storage further contributes to cost savings.
Managing Diverse Data
Hadoop’s FileSystem is adept at storing a diverse range of data formats in its data lakes, including unstructured data like videos, semi-structured data such as XML files, and structured data found in SQL databases. Unlike systems with strict schema validation, Hadoop allows data to be accessed without adherence to a predefined schema, enabling flexible analysis in various ways.
FAQs
What is Big Data and Hadoop ecosystem?
Big Data and Hadoop ecosystem comprise various interconnected tools and technologies designed to handle and process large and complex datasets efficiently.
What is the distinction between Big Data and Data Mining?
The key distinction between Big Data and Data Mining lies in their nature and purpose. Big Data is a term encompassing a substantial volume of data, while Data Mining involves a thorough exploration of data to extract essential knowledge, patterns, or information, irrespective of the data size—be it small or large. The primary difference centers on the scale of data (Big Data) versus the analytical process of uncovering insights (Data Mining).
Is Hadoop in demand?
Yes, Hadoop remains in high demand within the realm of Big Data Analytics Solutions. Many companies and industries are actively shifting their focus toward this evolving technological sector, indicating a substantial demand for professionals skilled in Hadoop and Big Data analytics.
What is a big data architecture?
Big Data architecture is like a plan that outlines how we deal with lots of data—how we take it in, work with it, store it, manage it, and get information from it. It’s the blueprint for handling large amounts of data effectively.
What are the components of Hadoop?
The four main components of Hadoop are HDFS (Hadoop Distributed File System), MapReduce, YARN (Yet Another Resource Negotiator), and Hadoop Common. These components form the core framework of Hadoop, and various tools and solutions are often employed to complement or support these key elements.
Conclusion
Hope this article has provided clarity on the concepts of Big Data and Hadoop, highlighting their distinctions.
By harnessing the power of Big Data analysis tools like Hadoop, organizations gain insights into emerging trends. This not only adds significant value but also enables the swift development of practical and effective solutions.
To further dive into the practical world, try our hands on labs and sandboxes.
- Top 25 AWS Data Engineer Interview Questions and Answers - May 11, 2024
- What is Azure Synapse Analytics? - April 26, 2024
- AZ-900: Azure Fundamentals Certification Exam Updates - April 26, 2024
- Exam Tips for AWS Data Engineer Associate Certification - April 19, 2024
- Maximizing Cloud Security with AWS Identity and Access Management - April 18, 2024
- A Deep Dive into Google Cloud Database Options - April 16, 2024
- GCP Cloud Engineer vs GCP Cloud Architect: What’s the Difference? - March 22, 2024
- 7 Ways to Double Your Cloud Solutions Architect Role Salary in 12 Months - March 7, 2024
