

Microsoft Fabric keeps appearing in the same places: job descriptions, architecture diagrams, conference talks, and your organisation’s roadmap. If you’re a data engineer trying to decide whether Microsoft Fabric is the right platform for you, and whether DP-700 is the right certification to pursue. Then this is the right spot. We have answered what Fabric actually is as a platform, how it works and what’s best for the Data engineer role.
Microsoft Fabric seems to be everywhere right now. It’s showing up in enterprise architecture discussions, data modernisation projects, conference keynotes, and increasingly, in certification conversations. Microsoft has reported that Fabric surpassed 19,000 paying organisations within months of general availability, making it one of the fastest-growing analytics platforms in the company’s history.
This level of adoption naturally raises two questions for data engineers.
- What exactly is Microsoft Fabric, and why are so many organisations investing in it?
- If Fabric adoption is accelerating, is the DP-700 Microsoft Fabric Data Engineer Associate certification worth pursuing, and how does it compare to established paths like Databricks?
Here is a complete guide to both. Let’s first break down Microsoft Fabric: what it is, how it works, and why it represents a significant shift from traditional data engineering architectures. Then we’ll explore how Fabric is changing the role of the modern data engineer, compare DP-700 with Databricks certifications, and help you determine which path aligns best with your career goals.
What is Microsoft Fabric?
Microsoft Fabric is a unified analytics platform that combines data engineering, integration, warehousing, real-time analytics, data science, and business intelligence into a single SaaS environment built on OneLake. It is designed to simplify enterprise data architectures while supporting analytics and AI workloads at scale.
Microsoft Fabric replaces multiple Azure data tools with one connected platform.
This sounds like a product positioning statement until you understand the problem it was built to solve.
For years, enterprise data teams operated across fragmented architectures. A typical Azure-based analytics stack often includes:
- Azure Data Factory for ingestion
- Azure Synapse for warehousing and analytics
- Azure Data Lake Storage (ADLS) for storage
- Power BI for reporting
- Azure Machine Learning for AI workloads
Technically, these services worked together. Operationally, they often created friction. Every time a workflow crossed a tool boundary, teams paid a hidden coordination cost:
- Separate identity and access management policies
- Multiple monitoring dashboards
- Different compute models
- Duplicate governance configurations
- Complex permission handling
- Constant context switching for engineers
Instead of stitching together separate services, Fabric introduces a unified operating model where ingestion, transformation, analytics, governance, and reporting exist inside a shared environment.
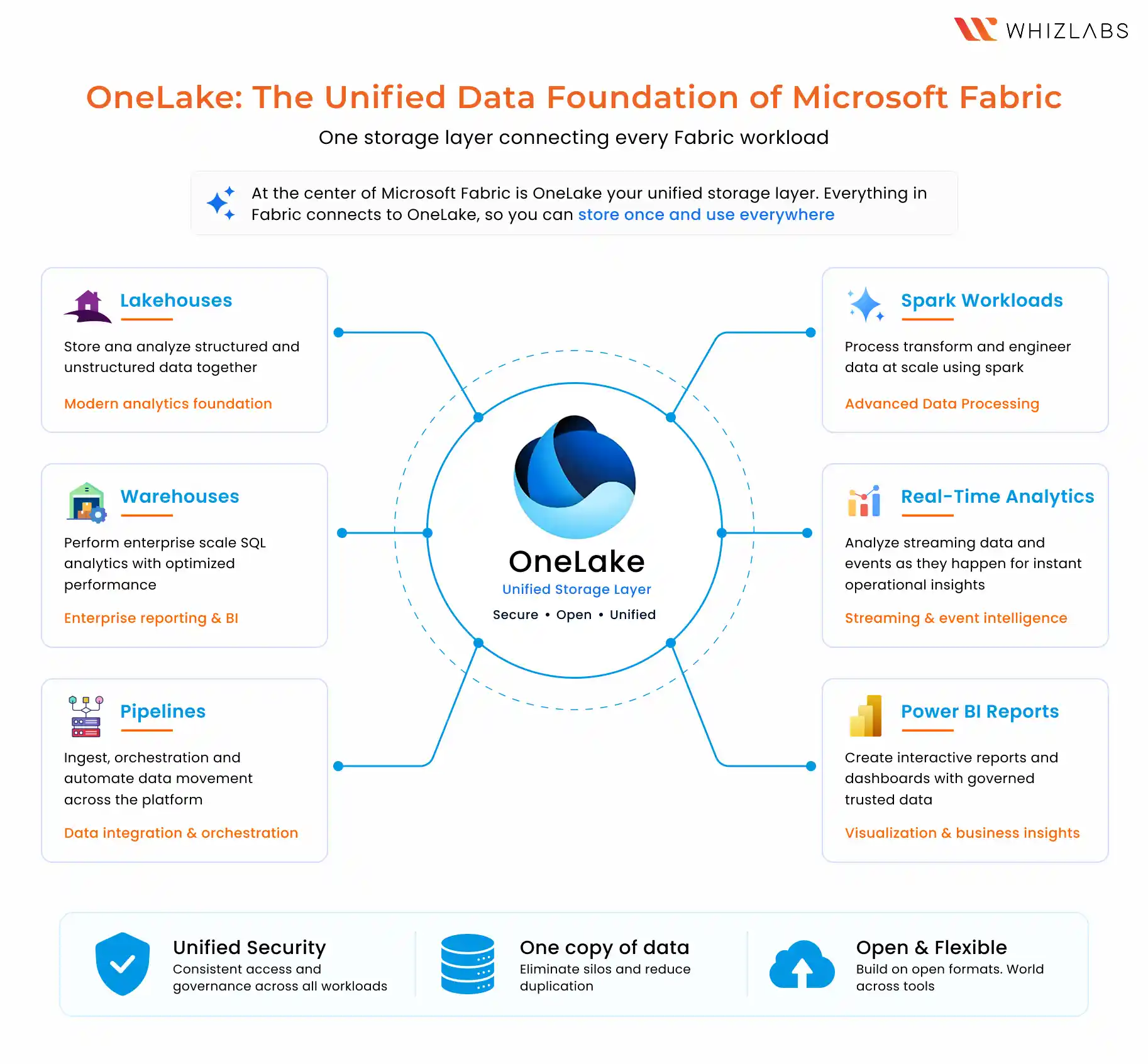
Store once. Access everywhere. Analyse across every Fabric experience.
Because everything operates on top of the same storage layer, organisations gain something that matters far more than convenience: consistency.
- One governance surface.
- One workspace experience.
- One security model.
- One billing ecosystem.
For enterprise leaders, that simplifies compliance, governance, and operational overhead. For data engineers, it removes much of the friction involved in managing disconnected services across the analytics lifecycle. And that is the real reason Microsoft Fabric is gaining attention.
It isn’t just another analytics tool.
Microsoft attempts to turn modern data engineering from a collection of loosely connected services into a unified platform experience.
Six Components of Microsoft Fabric
One of the reasons Microsoft Fabric feels different from traditional Azure analytics environments is that its services are designed to operate as parts of a single system rather than isolated tools. To understand why enterprises are paying attention to Fabric, it helps to break down the six core components that make the platform work.
1. OneLake: The Shared Storage Layer
OneLake is the unified storage foundation for Microsoft Fabric. Every Fabric workload, whether it’s a Lakehouse, Warehouse, Power BI report, Notebook, or Pipeline, reads from and writes to OneLake automatically.
In older architectures, teams often managed separate Azure Data Lake Storage accounts, Synapse workspaces, and Power BI datasets independently. That meant additional configuration, duplication, and data movement between systems. With OneLake, Fabric removes much of that operational overhead.
Instead of manually moving data across tools, everything operates against the same shared storage layer. That simplifies: Access control, Governance, Data sharing, Monitoring and Collaboration across teams.
2. Lakehouse: Where Structured and Unstructured Data Meet
The Lakehouse combines the flexibility of a data lake with the performance and structure of a warehouse. Fabric Lakehouses are built on the Delta Lake format and support SQL endpoints, Spark workloads, and medallion architecture patterns.
In practice, this often looks like:
- Raw event data landing in a Bronze layer
- Cleaned and validated data moving into Silver
- Business-ready datasets are becoming Gold tables for analytics and reporting
All inside the same Fabric environment. No moving files between storage accounts. No rebuilding pipelines across separate systems.
This is also one of the core architectural concepts validated in the DP-700 Data Engineer Associate Exam Certification.
3. Data Factory: Pipeline Orchestration Inside Fabric
Fabric includes a native version of Azure Data Factory for orchestration and ingestion. If you’ve used Azure Data Factory before, the experience will feel familiar: Data Pipelines, Scheduling, Connectors, Workflow orchestration and Data movement across systems.
But the difference is integration.
Pipelines inside Fabric can interact directly with Lakehouse tables, Spark notebooks, and Warehouses without leaving the platform.
For Azure engineers, this significantly reduces friction between ingestion and analytics workloads.
4. Spark: Large-Scale Transformation Without Cluster Management
Fabric includes managed Spark environments for notebook-based data transformation and processing. Data engineers can use: PySpark, Spark SQL and Scala notebooks – to process large-scale datasets directly inside Fabric.
In practice, Spark becomes important when the transformation logic goes beyond what SQL handles efficiently.
Examples include:
- Deduplicating millions of records
- Feature engineering for machine learning
- Parsing semi-structured data
- Complex enrichment workflows
The key difference in Fabric is operational simplicity. Engineers focus on transformation logic, not managing Spark clusters.
5. Real-Time Intelligence: Streaming Analytics at Scale
Fabric includes real-time ingestion and analytics capabilities through: Eventstreams, KQL databases and Real-Time Intelligence workloads.
This allows organisations to ingest, monitor, and analyse streaming data continuously.
Common use cases include: IoT telemetry, Application logs, Fraud detection, and live operational dashboards.
While still an emerging area for many data teams, real-time analytics is becoming increasingly important as organisations move toward AI-driven and event-based systems.
DP-700 includes coverage around orchestration, monitoring, and streaming-related workloads within Fabric environments.
6. Power BI: Reporting Inside the Same Platform
Power BI is natively integrated into Microsoft Fabric. This changes something subtle but important. Traditionally, reporting layers often sat separately from the engineering environment. Data had to be exported, modelled, synchronised, and secured across different systems.
Inside Fabric, Power BI operates directly against the same Lakehouse and Warehouse environment. That means:
- Gold-layer tables become instantly queryable
- Reporting and engineering share governance controls
- Credential management is simplified
- Data movement between tools is reduced
In practical terms, the analytics pipeline and reporting layer become part of the same operating system. And that’s ultimately the core idea behind Microsoft Fabric itself:
Not separate services connected, but a unified platform designed to operate as one system.
Why Are Enterprises Migrating to Microsoft Fabric Right Now?
Microsoft Fabric adoption is accelerating quickly, but the reason goes beyond curiosity around a new Microsoft product. Enterprises are moving toward Fabric because it changes how modern data systems are designed and operated.
Enterprise adoption accelerated faster than most Microsoft platform launches, driven not by feature novelty but by the operational consolidation Fabric delivers. Large enterprises, including companies in retail, manufacturing, healthcare, and financial services,s have already begun adopting Fabric as part of broader data modernisation initiatives.
It is not the feature set, but consolidation that is driving this shift. For years, Azure-based analytics environments were often built across multiple services:
- Azure Data Factory for ingestion
- Synapse Analytics for warehousing
- Azure Data Lake Storage for storage
- Power BI for reporting
- Separate governance and monitoring layers across the stack
Technically, the architecture works, and Operationally, it created fragmentation.
Different permission models. Separate monitoring experiences. Multiple computer systems. Repeated data movement between services. All of this increased complexity as environments scaled.
Fabric changed this by bringing those workloads into a unified operating environment built around OneLake. And that’s why many organisations are now evaluating migration paths from older Synapse and ADF-based architectures into Microsoft Fabric environments.
This shift is happening because Organisations wanted,
- Shared governance
- Unified storage
- Simplified orchestration
- Integrated analytics workflows
- Lower operational overhead across data platforms
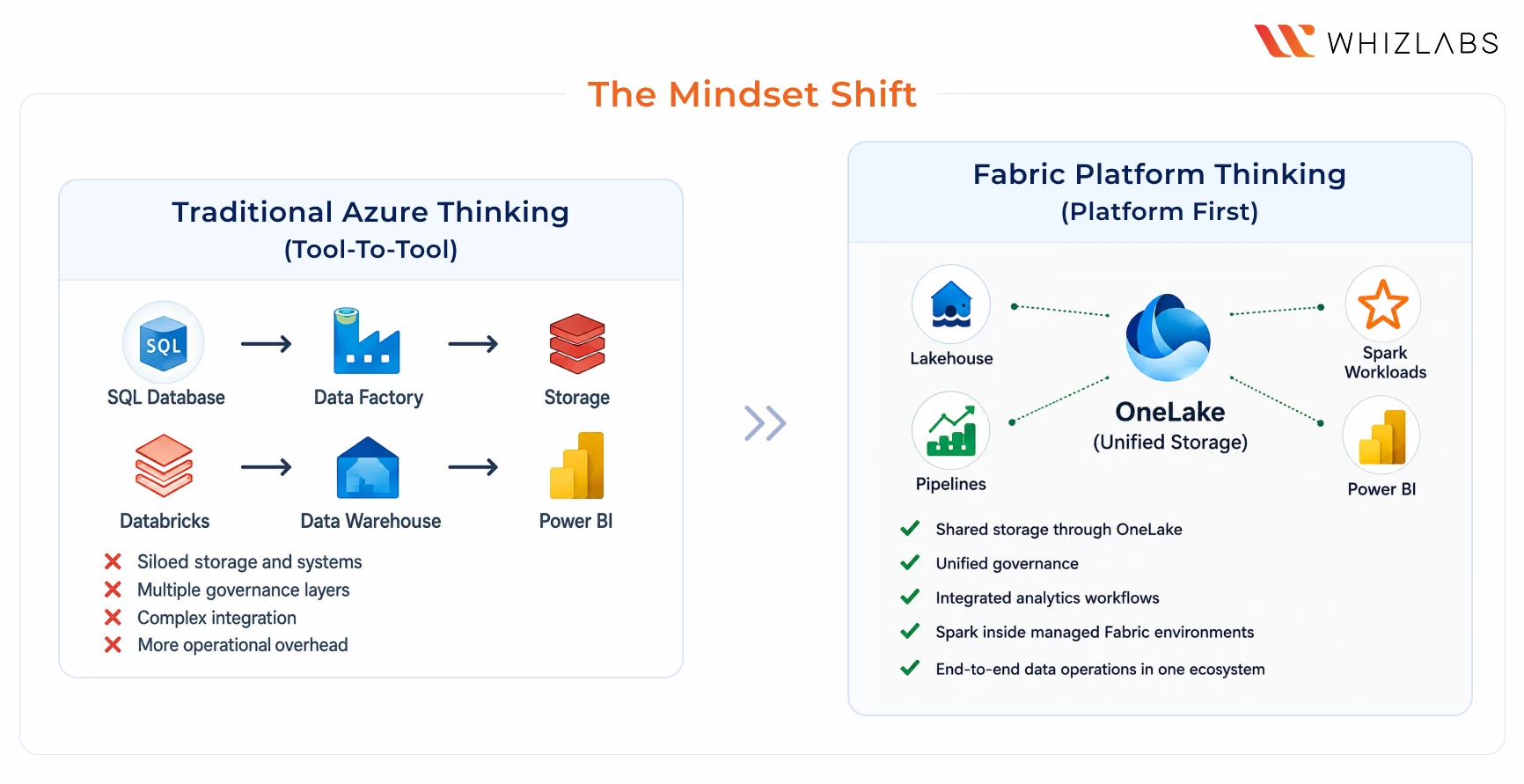
This migration is not an overnight process; for many organisations, this will be a multi-year transition. The existing Azure analytics environments gradually evolve toward Fabric-centric architectures.
But that transition is already changing how modern data systems are being designed, and, increasingly, what organisations expect data engineers to understand. That shift in architecture is also changing the roles and bringing us to what a Microsoft Fabric Data Engineer actually does in practice.
What is the role of Microsoft Fabric Data Engineers?
The easiest way to understand the Microsoft Fabric Data Engineer role is that they combine traditional data engineering with platform-level responsibility.
A typical day inside a Fabric environment rarely involves working on just one isolated tool. Instead, the role revolves around managing how data moves, transforms, governs, and serves analytics across a unified platform.
In practice, it’s
- Building Lakehouses for analytics workloads
- Designing ingestion pipelines using Data Factory
- Running Spark transformations on large datasets
- Managing Delta tables and medallion architectures
- Monitoring pipeline performance and failures
- Configuring workspace access and governance policies
- Supporting Power BI and analytics teams with trusted datasets
This is an operational work; you would have started it elsewhere, but by mid-week, you might be debugging a slow Spark notebook that’s delaying a downstream reporting workflow. And as the week closes, you’re reviewing governance changes tied to workspace access or compliance requirements. The role sits at the intersection of engineering, analytics, reliability, and governance.
If you’re weighing whether this role transition makes sense for your career, our DP-700 Certification and Career Growth guide → covers salary data, market demand, and a full preparation roadmap.

For professionals with traditional Azure data engineering backgrounds, most foundational attributes transfer directly. Skills that remain highly relevant include:
- SQL and data modeling
- ETL and pipeline design
- Data warehousing concepts
- Orchestration logic
- Monitoring and troubleshooting
But what’s changing is the architectural mindset?
Instead of thinking tool-to-tool integration first, Fabric engineers think platform-first:
- Shared storage through OneLake
- Unified governance
- Integrated analytics workflows
- Spark inside managed Fabric environments
- End-to-end data operations within one workspace ecosystem
That shift is exactly what the DP-700 Microsoft Fabric Data Engineer Associate certification is designed to validate.
And once engineers understand this, the next question naturally follows:
If DP-700 validates modern Fabric engineering skills, why choose it over the other established options, especially Databricks?
That’s where the comparison becomes important.
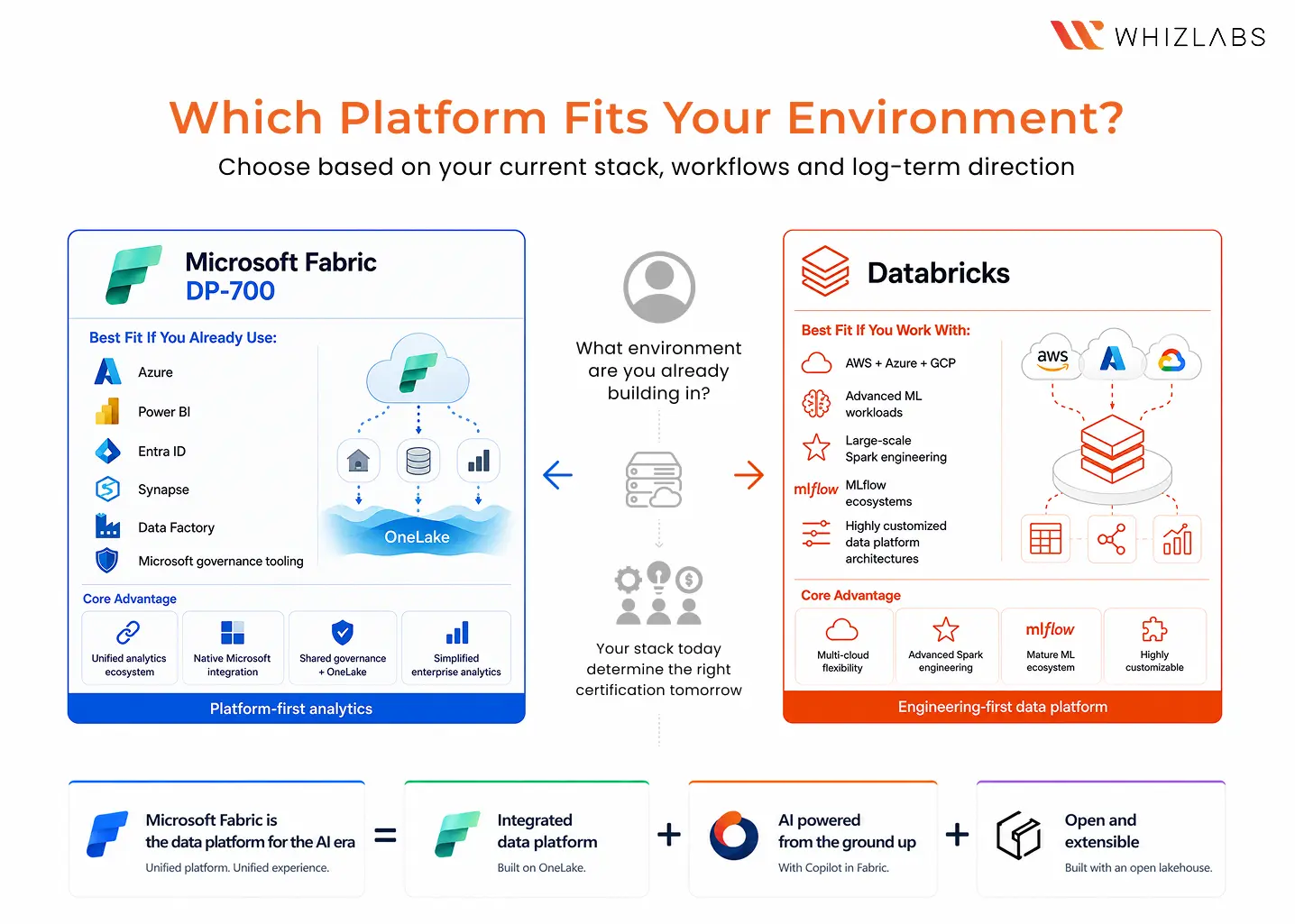
DP-700 vs Databricks Certified Data Engineer
Most comparisons are between Microsoft Fabric and Databricks. One side claims Fabric is the future because it’s unified. The other argues Databricks remains the gold standard for large-scale data and AI engineering.
The reality is more nuanced, pointing to a much sharper question.
Which platform aligns better with how your organisation builds data systems and the kind of engineer you want to become?
To answer that properly, six things matter more than hype:
- Platform architecture fit
- Ecosystem integration
- Exam scope and engineering depth
- Preparation complexity
- Ecosystem portability
- Long-term platform direction
|
Criteria |
DP-700 Microsoft Fabric | Databricks Certified Data Engineer |
Advantage |
| Platform Architecture Fit | Unified workspace with OneLake, Lakehouse, pipelines, governance, and reporting inside one platform | Strong Lakehouse architecture, but it relies more heavily on separate integrations across environments | DP-700 ✓ |
| Azure / Microsoft Ecosystem Integration | Native integration with Azure, Entra ID, Power BI, and Microsoft governance tooling | Azure Databricks integrates well, but still introduces additional architectural layers | DP-700 ✓ |
| Multi-Cloud Engineering Flexibility | Primarily Azure-first architecture | Strong AWS, Azure, and GCP portability | Databricks ✓ |
| Unified Governance Model | Single governance surface across storage, analytics, and reporting | Strong governance capabilities, but across more distributed environments | DP-700 ✓ |
| ML / AI Engineering Depth | Growing ML capabilities within Fabric | Stronger ML ecosystem with MLflow, Feature Store, and mature model operations | Databricks ✓ |
| Long-Term Platform Direction | Microsoft is positioning Fabric as the default unified analytics platform moving forward | Databricks is continuing its aggressive expansion across AI, streaming, and Lakehouse infrastructure | Draw ≈ |
- Databricks remains exceptionally strong for organisations operating large-scale multi-cloud environments or building ML-heavy platforms where deep Spark and MLflow expertise matter.
Microsoft Fabric, however, solves a different problem.
- It is designed around reducing architectural fragmentation inside Azure-centric enterprises. Instead of asking engineers to integrate multiple services manually, Fabric pushes toward a unified operating model where storage, pipelines, governance, analytics, and reporting operate inside the same environment.
If your organisation is heavily invested in Azure, Power BI, and Microsoft-native governance, the architectural simplicity of Fabric becomes difficult to ignore.
If your work revolves around cross-cloud engineering, advanced ML operations, or highly customised Spark ecosystems, Databricks still holds a meaningful advantage.
Databricks optimises for engineering flexibility. Microsoft Fabric optimises for operational unification. Both are solving different versions of the modern data platform problem.
DP-700 wins on platform architecture fit, Azure ecosystem integration, and unified governance. Databricks wins on multi-cloud flexibility and ML engineering depth. For data engineers working in Microsoft and Azure-centric organisations, the architectural comparison points clearly toward Microsoft Fabric and DP-700.
Which One Is Right for You? A Decision Framework Based on Your Current Stack
1. Azure/Microsoft stack:
If your organisation runs primarily on Azure, with Power BI, Entra ID, and Microsoft governance tooling already in place, DP-700 is the direct call. Fabric is built into that ecosystem—the certification maps to the platform your team is already building on.
2. Databricks-native or multi-cloud:
If your engineering environment is multi-cloud: AWS, GCP, or Azure Databricks or if your team does heavy ML workloads with MLflow and Feature Store, Databricks certification makes more architectural sense. Build where you operate.
3. Neutral ground/switching stacks:
If you’re choosing from neutral ground, Microsoft Fabric’s unified architecture gives you the broadest applicable skill set for enterprise data engineering right now. Organisations are consolidating onto unified platforms. Fabric is where Microsoft is building that future and the DP-700 certifies you to work within it.
Right certification often depends on the systems you’re already building on.
FAQ
1. Can I use Microsoft Fabric with Databricks?
Yes. Microsoft Fabric and Databricks are not mutually exclusive platforms. Organisations can integrate both environments using shared Delta Lake formats and OneLake shortcuts. From a certification perspective, however, they represent different platform specialisations and different engineering workflows.
2. Is Microsoft Fabric better than Databricks?
Neither platform is objectively “better”; they optimise for different priorities. Databricks offers stronger multi-cloud flexibility and a more mature machine learning ecosystem. Microsoft Fabric provides tighter integration with Azure, Power BI, governance tooling, and unified analytics workflows. The right choice depends largely on your organisation’s architecture and operating model.
3. Does DP-700 cover Databricks concepts?
Not directly. DP-700 is focused specifically on Microsoft Fabric. There is some conceptual overlap, but the certification validates those skills within the Fabric environment rather than Databricks-specific workflows or tooling.
Which data engineering certification has the best ROI in 2026?
The answer depends on your existing stack and career direction, but DP-700 is increasingly gaining attention because it aligns with Microsoft’s broader Fabric adoption strategy and unified analytics architecture. For a full comparison of leading certifications by market demand, salary potential, and certification ROI, read: Top Data Engineering Certifications to Consider in 2026
4. Is Microsoft Fabric replacing Azure Synapse Analytics?
Yes, effectively. Microsoft Fabric replaces the core use cases of Azure Synapse data integration, warehousing, and analytics within a unified platform. Microsoft has signalled Synapse as a mature service with investment consolidating into Fabric. For Azure teams running Synapse workloads, Fabric is the forward migration path.
5. How long does it take to prepare for the DP-700 exam?
Most candidates with a data engineering background need 6–8 weeks of structured preparation.
If you are already leaning towards DP 700
If you came into this comparison already leaning toward DP-700, the analysis above explains why that instinct makes sense.
- The platform adoption is real.
- Architectural consolidation is happening. Organisations that once operated across separate Azure data tools are increasingly moving toward unified analytics environments built around Microsoft Fabric, and DP-700 is the certification designed around that shift.
For professionals preparing for this certification, the most important thing to understand is that DP-700 is highly scenario-driven. The exam tests applied decision-making across ingestion, transformation, governance, orchestration, monitoring, and optimisation, not just conceptual recall.
That’s why hands-on practice matters.
Whizlabs, a cloud certification preparation platform specialising in cloud and data engineering certifications across AWS, Azure, GCP, and Microsoft Fabric, offers a DP-700 preparation path that includes: structured video modules, Microsoft Fabric hands-on labs, Lakehouse and Spark transformation scenarios, pipeline orchestration exercises, sandbox environments, and 400+ practice questions aligned to the exam domains.
Still have questions? Drop us an email at [email protected]. We will sort it out.
- How does FinOps Certified Practitioner Scale Financial & Tech Careers? - July 20, 2026
- What Is Generative AI for Azure Cloud Engineers? - July 13, 2026
- From Cloud Certification Ready To Building Real Capabilities - July 2, 2026
- How to Pass AWS SOA-C03 CloudOps Engineer Associate Exam? - June 12, 2026
- Claude Certified Architect – Foundations CCA-F Exam Guide - June 4, 2026
- DP-700 Master Content Guide Microsoft Fabric Explained for Data Engineers - May 28, 2026
- DP-700 Microsoft Fabric Data Engineer Career Roadmap - May 19, 2026
- AWS AI Practitioner vs Other AI Certs: Which to Choose in 2026 - May 6, 2026